Python 爬虫进阶必备 | 某财经资讯网站的签名加密逻辑分析(旧站更新)

今日网站
aHR0cHMlM0EvL3d3dy5jbHMuY24vdGVsZWdyYXBo
这个网站是 Js 逆向学员群里由学员提出的,这个网站的加解密之前已经写过案例了,听学员说加密已经更改了,所以抽个时间写一篇解析一下。
(上面那串密文用 Base64 解码就行了)
抓包与加密定位
打开网站,同时打开抓包,所有的 XHR 请求里都带着 sign 加密参数

搜索参数的结果非常多,所以我们直接打 XHR 断点,就像下面这个样子

过一小会儿就自动断上了
网站断点断上的时候,这个参数如果已经生成了,那应该是去找堆栈,在堆栈里向上寻找。
所以不要乱了步骤
我这里就不纠结怎么找到这个参数的位置了,调试几遍就能看到,在下面图里标注的地方就是 sign 生成的地方


参数加密分析
这里的 p 的逻辑看着有点复杂
p = r ? l({}, b(l({}, r)), {sign: g(l({}, r))}) : {sign: g("")}
其实就是一个三元表达式,如果你看不明白这个逻辑是怎么执行的,可以看下之前推荐过的一些 Js 教程,这里不纠结这个。
可以看到这里主要的逻辑就是下面这段
sign: g(l({}, r))
所以我们找找这些方法都是些什么?

先进来的逻辑好像也有一些复杂的样子,不过我们不要担心这个,只要把注意力关注在 t 这个值的变化上
我们逐步执行到下面这行代码的时候,
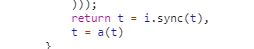
我们看下t的值,我们通过console观察

可以看到这里中间的操作就是将参数拼接起来了
def params_format(params):
url = ''
if params:
if not isinstance(params, dict):
raise Exception('params必须是字典') # 不是字典格式抛出异常
url += '&'.join(
[str(key) + '=' + str(value) for key, value in params.items()])
strSplit = url.split('&')
strSorted = sorted(strSplit)
strConvert = '&'.join(strSorted)
return strConvert
写了一个大概意思的 Python 代码
我们现在已经琢磨好了大部分的代码,但是好像还没有加密的操作,所以我们继续执行
可以看到接下来执行的这一步就是一个加密了
完成加密结果是一串密文

我们追进去是下面这样的代码

到这里我直接用网站测试一下,看看能不能撞到

测试结果和上面打印出来是一样的,就是 sha1
直接分析下一步的t = a(t)
再次追进去,看到下面这样的代码

其实标志也很清楚,再测试下和 MD5 的结果一样一样的。

我也测试了一下这个网站的其他sign都是这个加密的逻辑,有些之所以会变是因为其中带入了时间戳,也是一个近乎没有难度的网站。
以上就是今天的全部内容了,咱们下次再会~

- 点赞
- 收藏
- 关注作者
评论(0)