微认证:基于BoostKit的大数据性能调优实践

【摘要】 微认证:基于BoostKit的大数据性能调优实践详解
基于BoostKit的大数据性能调优实践
1. 大数据特点及调优原因
1.1 大数据介绍及组件关系分布
- 大数据是集收集,处理,存储为一体的技术总称。在海量数据处理的场景,大数据对计算及存储的要求较高,普遍以集群形式存在。不同的组件有不同的功能体现


1.2 大数据并行计算特点天然匹配鲲鹏多核架构
- 海量数据需要更高的并发度来加速数据处理,鲲鹏多核计算的特点能够提升大数据任务的并发度,加速大数据的计算性能。此处以Mapreduce模型为例
- 但是,为了获得更好的性能,仍需根据硬件配置和应用程序特点,对软硬件系统做进一步的优化

1.3 调优原因

2. 大数据性能调优思路
2.1 常用调优思路

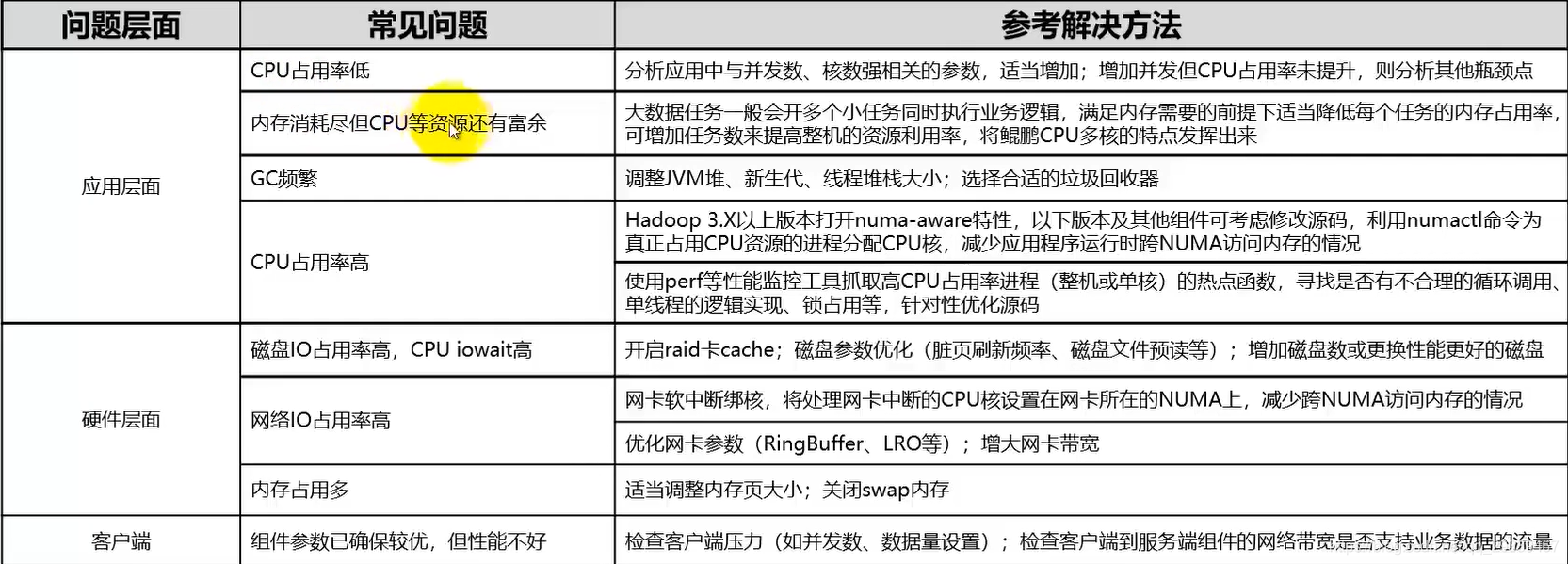
2.2 常见调优问题介绍
2.3 大数据组件:Hadoop-HDFS模块
- Hadoop由HDFS、Yarn、Mapreduce三个核心模块组成,分别负责分布式存储、资源分配和管理、分布式计算
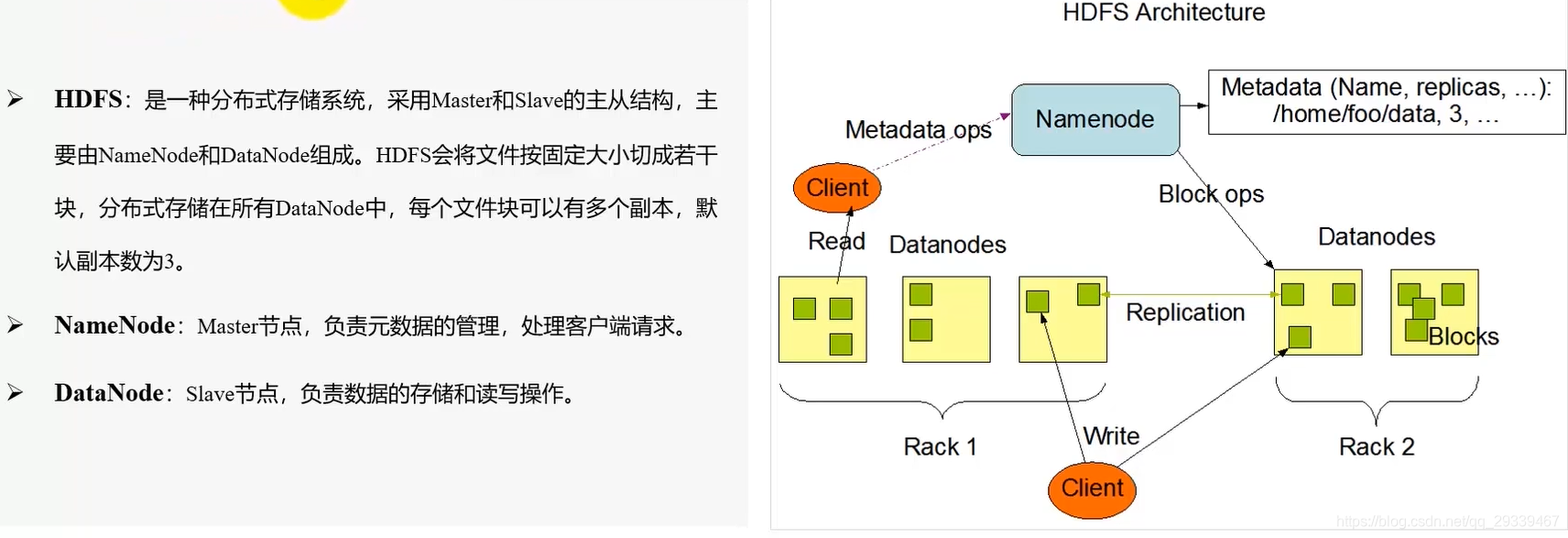
调优建议:尽可能保证DataNode节点间的磁盘性能统一,并从磁盘IO和网络IO两方面进行优化
2.4 大数据组件:Hadoop-Yarn模块
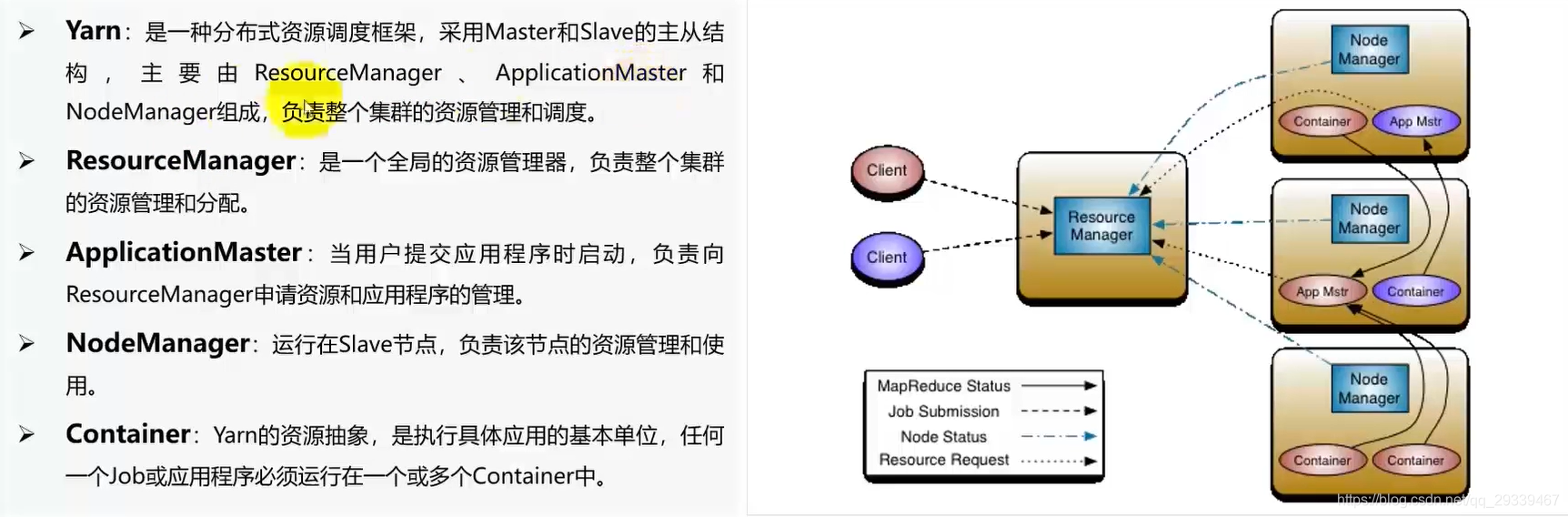
调优建议:尽可能将Slaves的CPU和内存资源提供给Yarn管理和使用,并根据应用程序的数据量,适当调整Container内存大小,将所有CPU核都利用起来,发挥鲲鹏多核的优势
2.5 大数据组件:Hadoop-Mapreduce模块
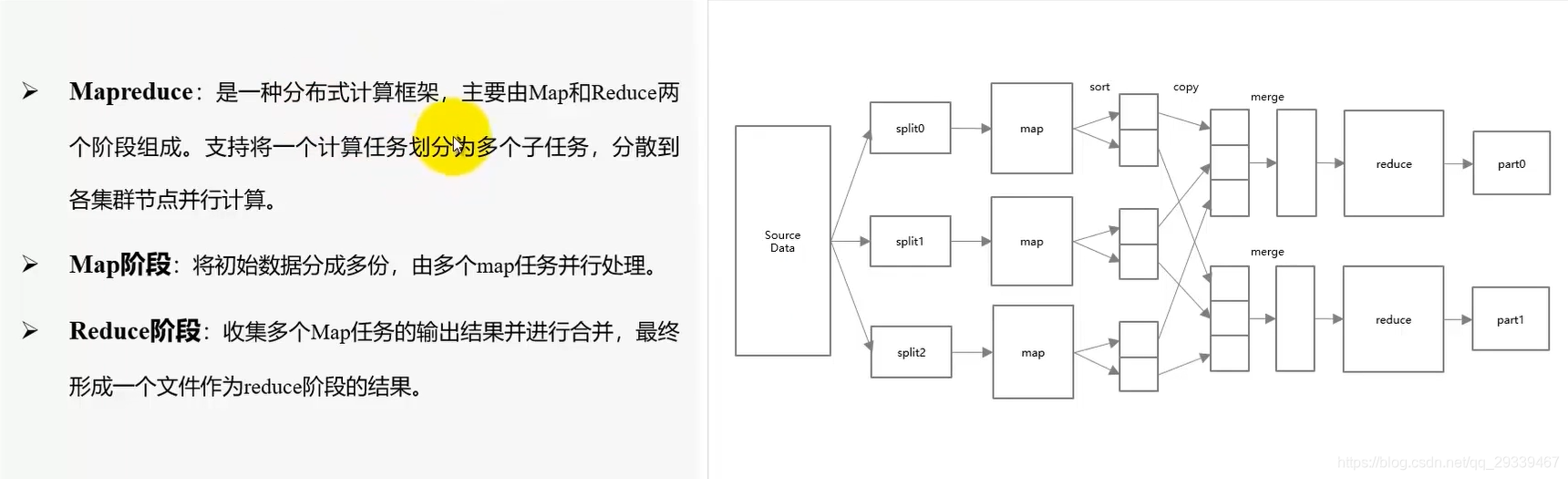
调优建议:适当调整Map核Reduce任务的数量与Reduce任务启动的时间,保证总任务数能覆盖到所有CPU核,避免资源浪费
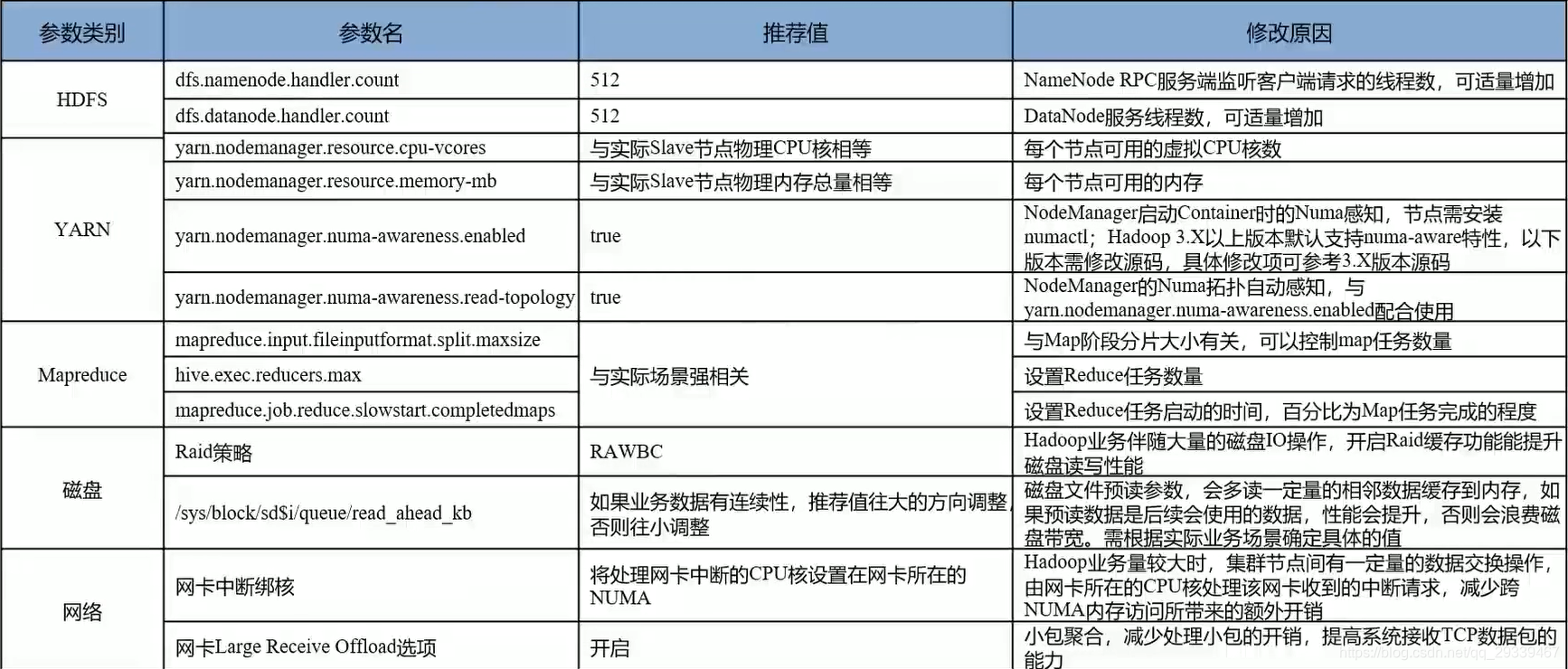
2.6 大数据组件:Hadoop 常用调优参数
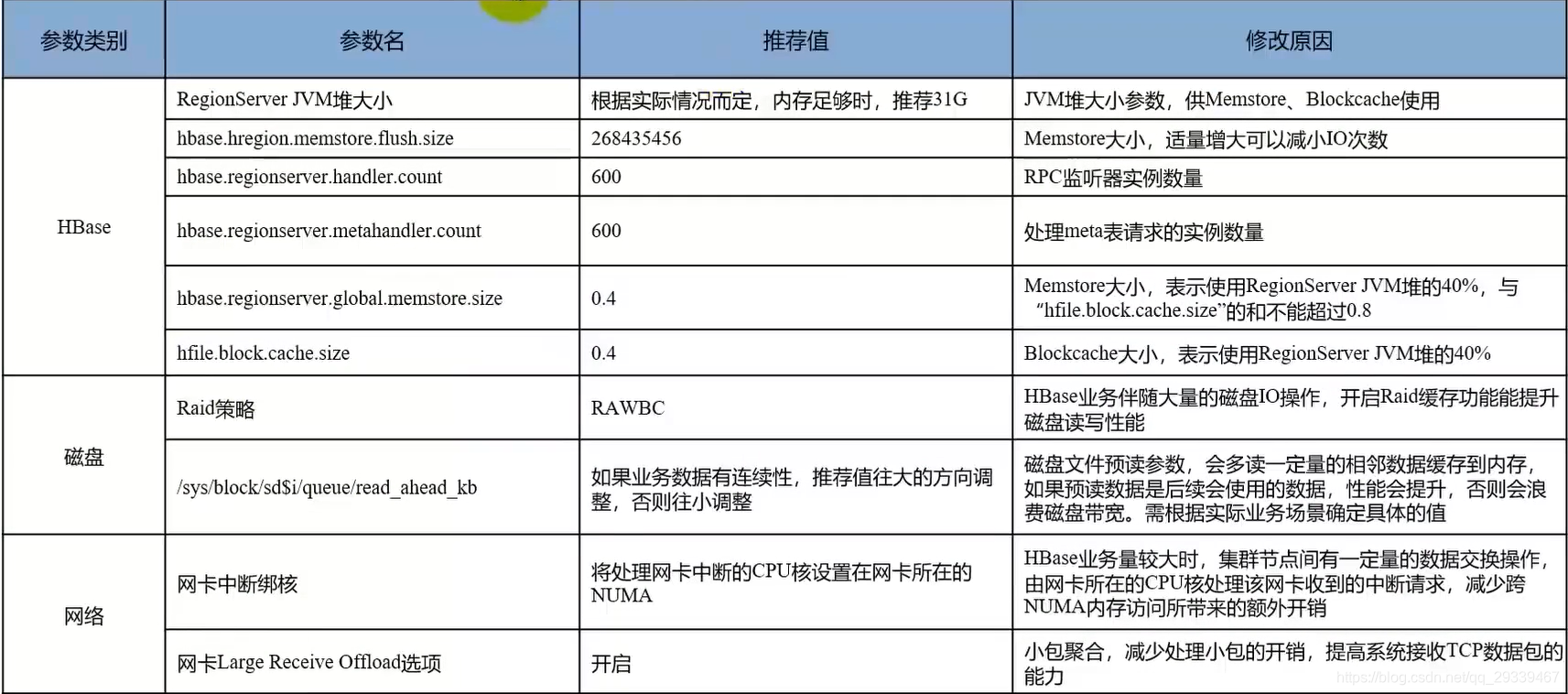
2.7 大数据组件:HBase框架
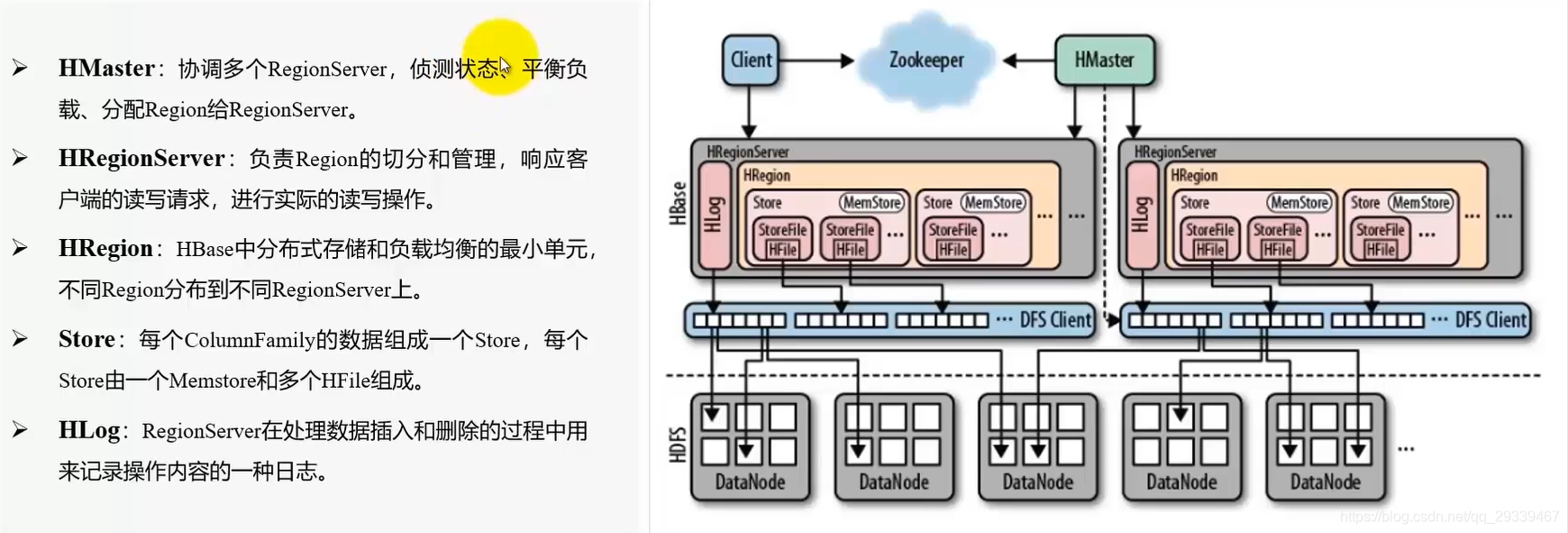
调优建议:适当增加MemStore核BlockCache容量来提升读写性能,同时优化磁盘IO和网络IO
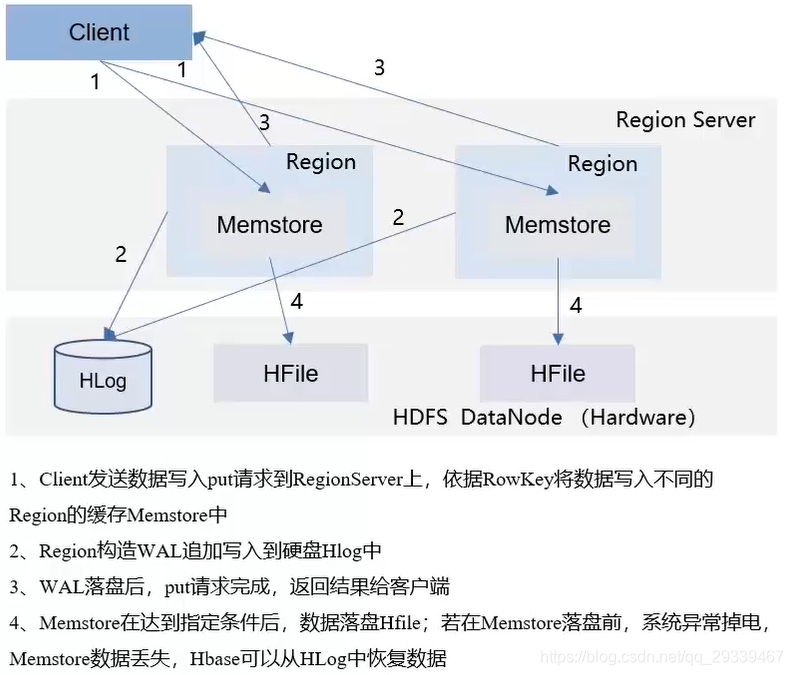
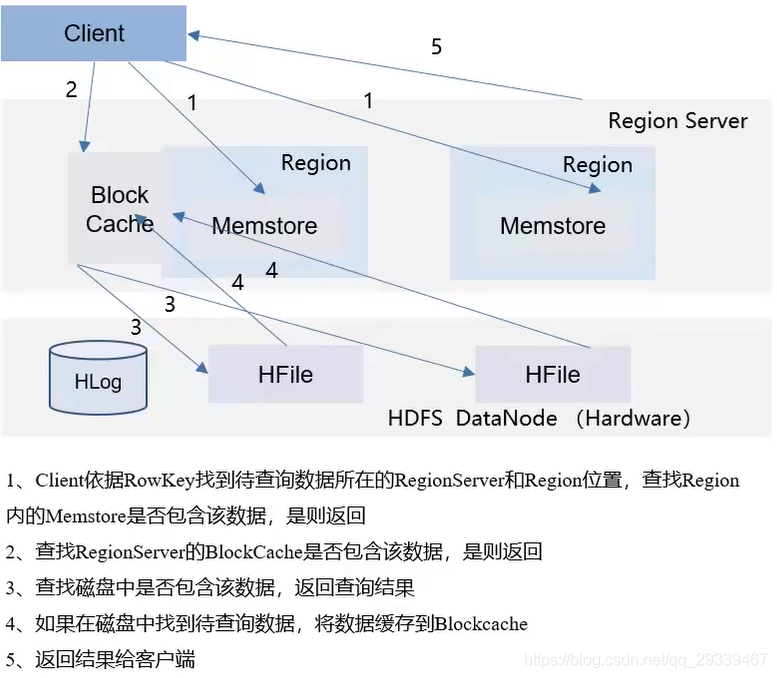
2.8 大数据组件:HBase读写流程
-
写入流程:优先写入Memstore内存区域,加速写入速度,HLog保障数据可靠
-
读取流程:依次从Memstore和BlockCache查找数据,若未命中,再从磁盘查找
2.9 大数据组件:HBase常用调优参数
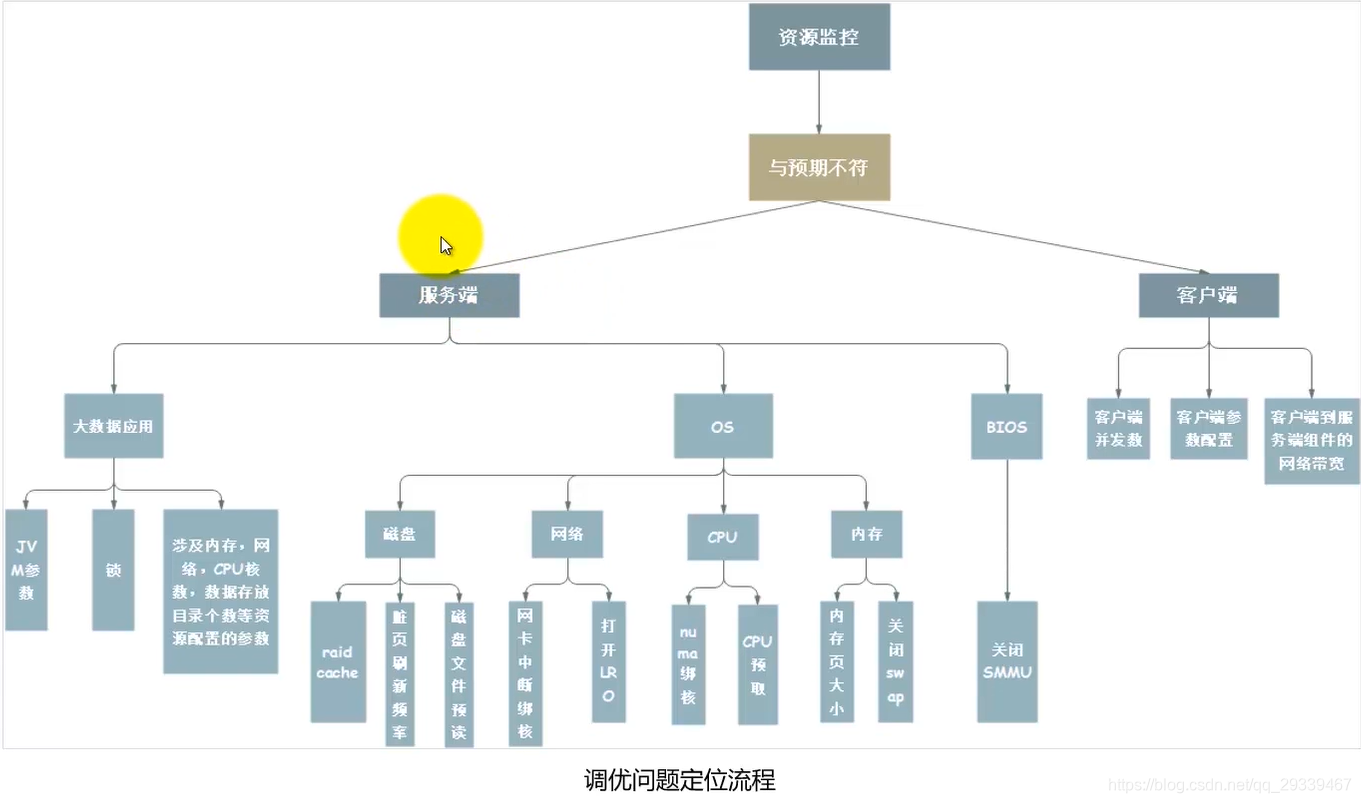
2.10 性能定位:问题定位流程
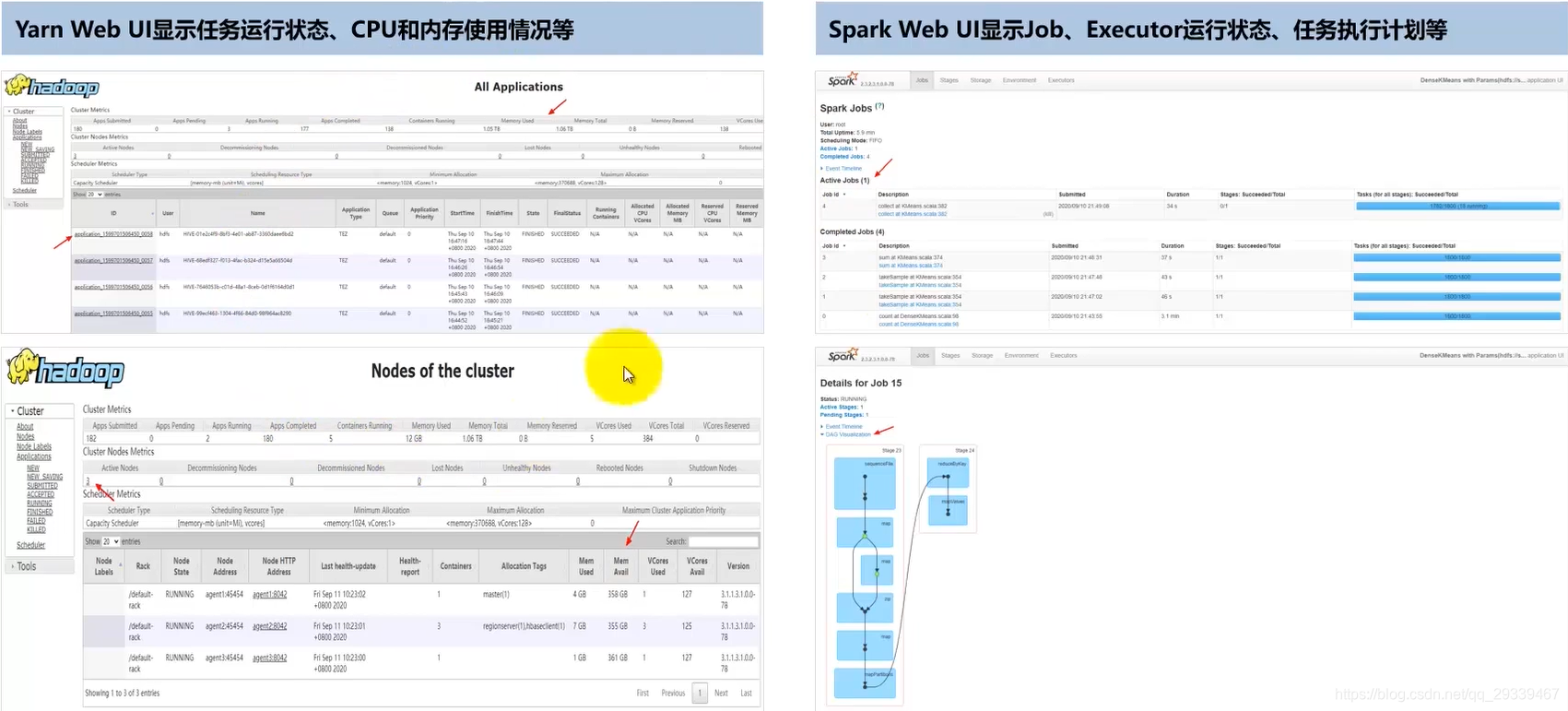
2.11 性能定位:资源监控工具
- nmon:支持收集一段时间内,整机的CPU、磁盘、网络、内存等各项资源的使用情况
- perf:获取指定进程内的调用情况、各线程调用的CPU资源消耗情况,并支持生成火焰圈
- dstat:监控系统整体的性能信息,包括CPU、磁盘、网络、分页等
- top:监控进程和整机的CPU、内存资源消耗情况,并支持查看每个CPU核的使用情况
- iostat:监控每块磁盘的读写次数、数据量大小、使用率
- sar:监控每张网卡的网络IO读写次数和数据量大小
- jstat:JVM统计监控工具
- java VisualVM:图形化的Java程序性能分析工具,能监控应用程序性能消耗、GC状况、线程堆信息等
2.12 性能定位:Web监控界面,显示基本配置和运行状态
3. 性能调优案例分享
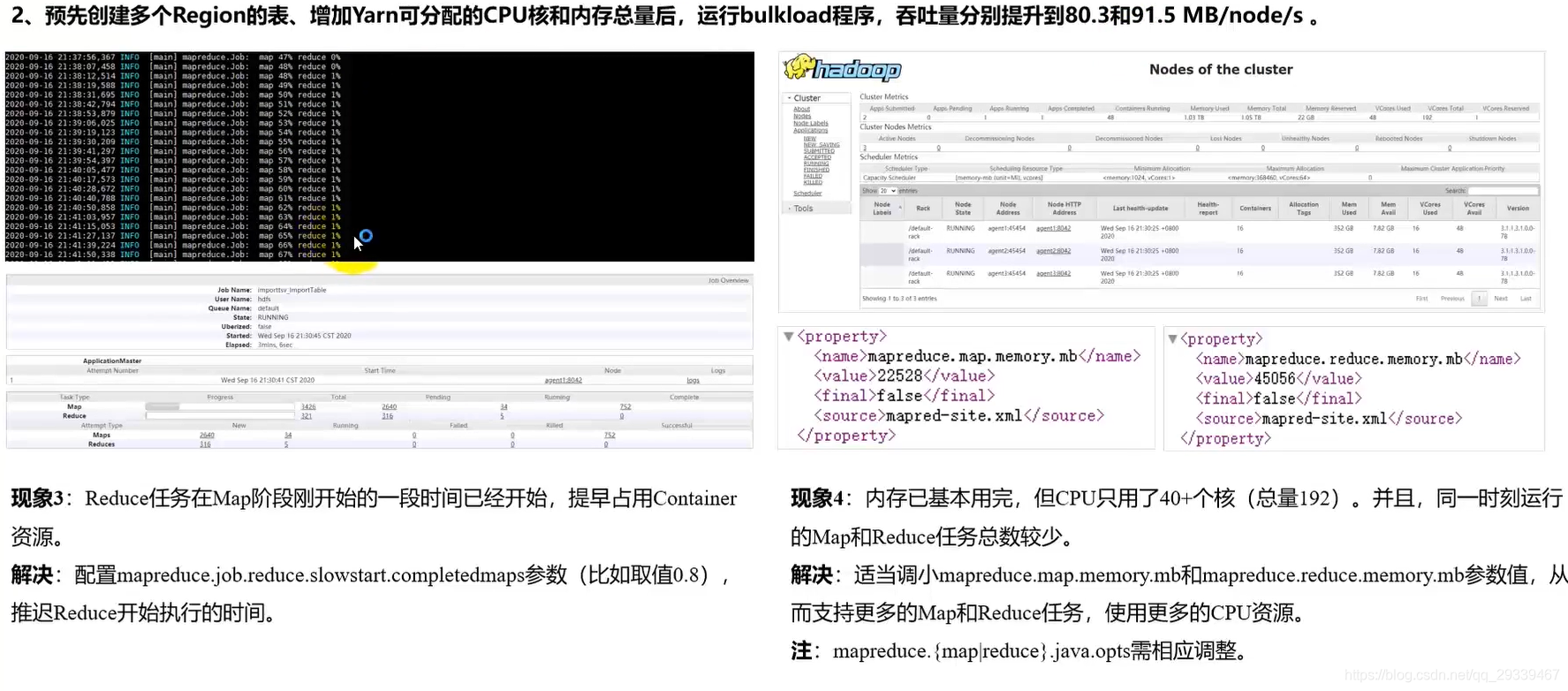
3.1 案例1:HBase Bulkload性能优化
- 背景:以HBase bulkload 性能优化为切入点,阐述调优过程中可能遇到的问题和解决思路
- 环境配置:采用1+3集群规模,由Ambari统一管理,每个节点拥有64 cores、384G内存、10GE网络带宽和6 * 4T的机械硬盘,将NameNode、ResourceManager、HMaster等进程部署在server节点,并在3个agent节点部署DataNode、NodeManager和RegionServer进程
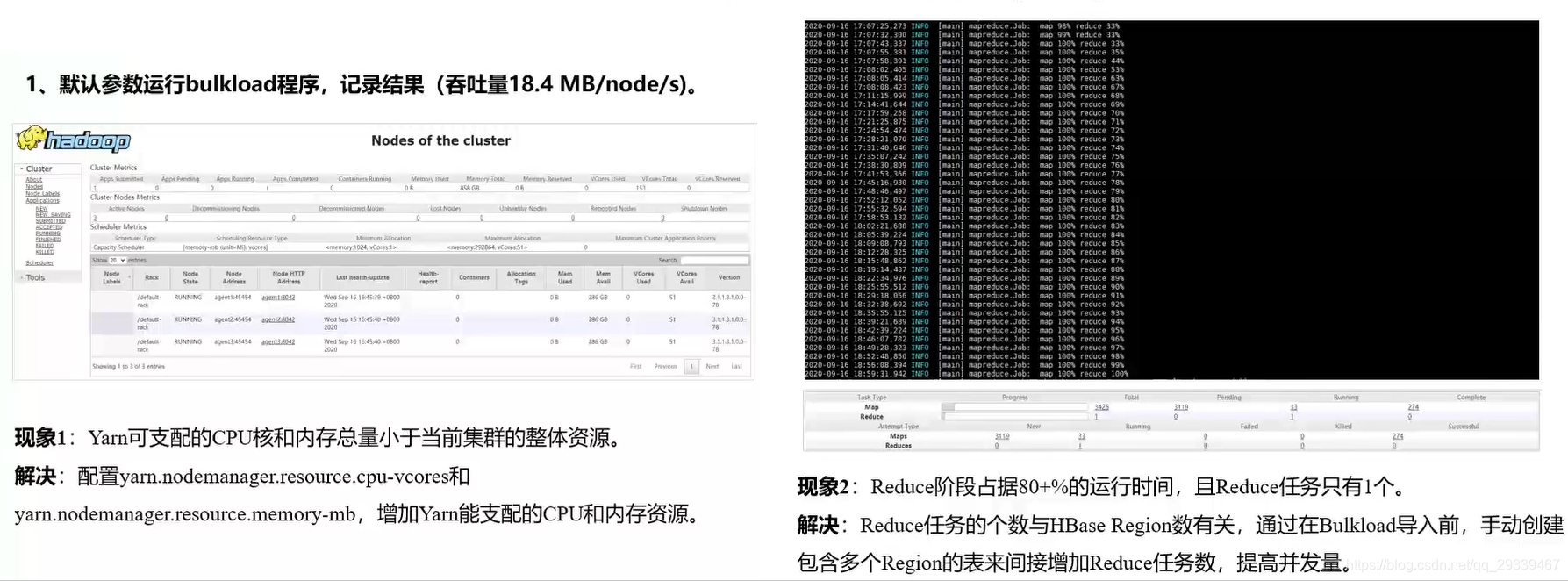
- 应用程序:使用HBase组件自带的bulkload程序进行测试

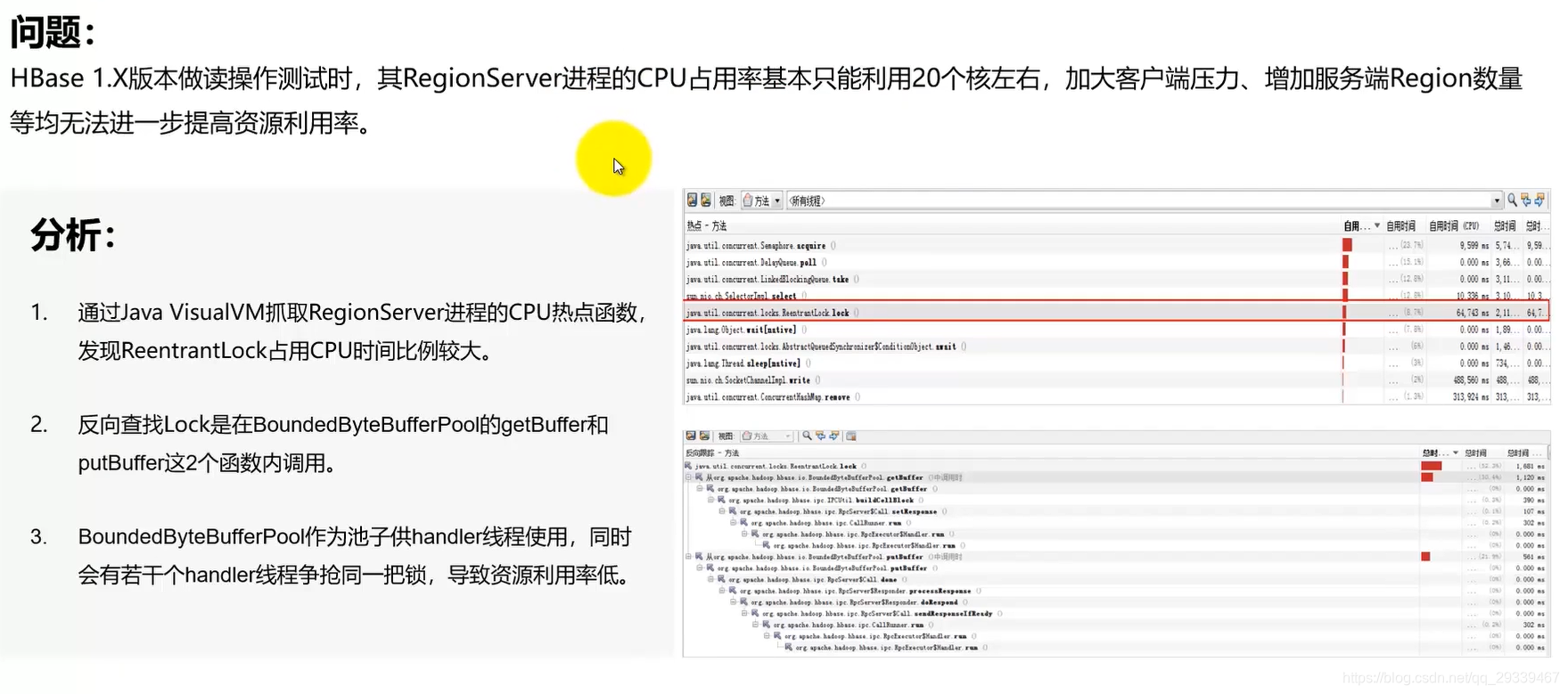
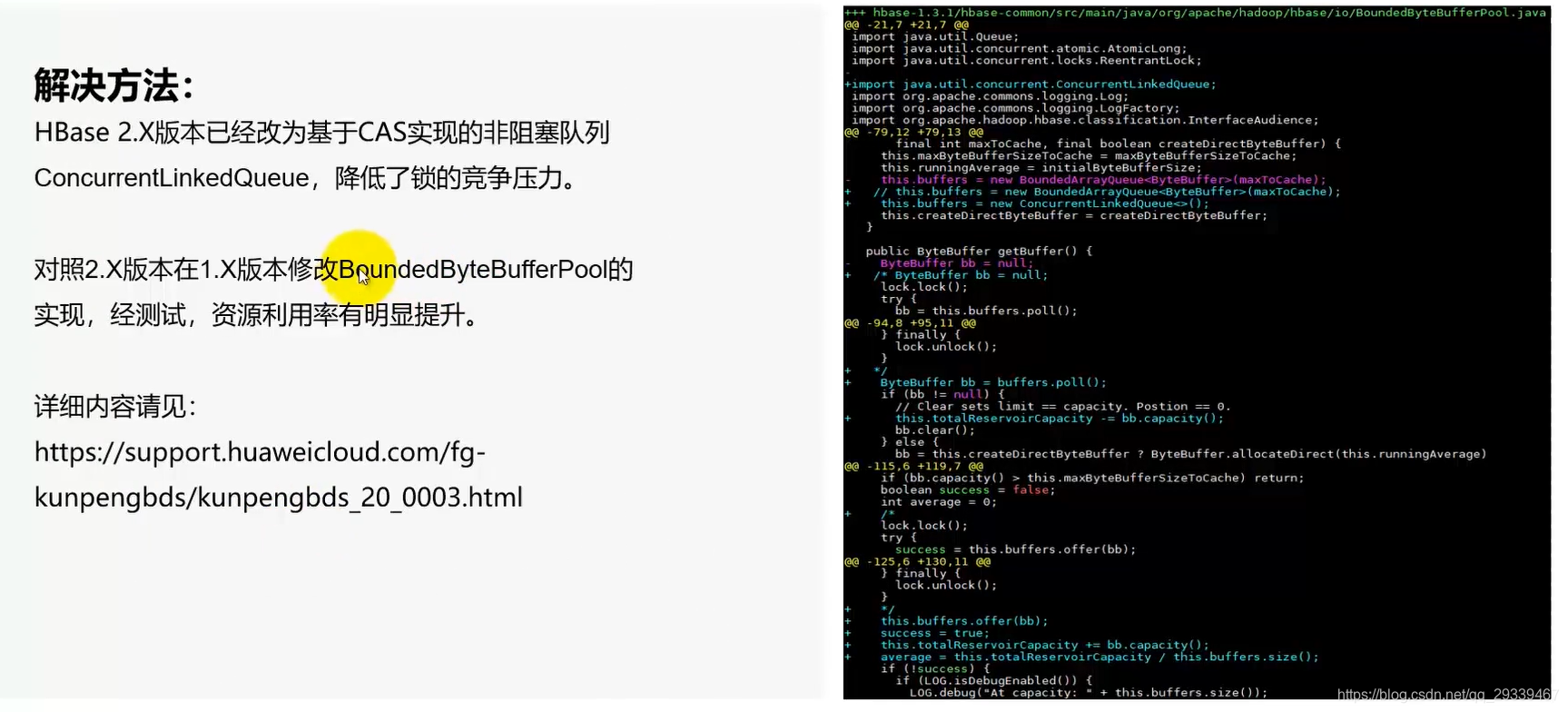
3.2 案例2:HBase 1.X版本执行读测试时,资源利用率低

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)