Python中的堆栈:如何,为什么以及在哪里?

嘿,您可能已经在这里搜索Python中的Stack了,好吧,我们为您整理了一下。在此博客中,我们将对如何在Python中使用Stack进行如何,为什么和为什么进行深入分析。
该博客包含以下主题:
- 什么是数据结构中的堆栈?
- 为什么以及何时使用堆栈?
- 我们如何在Python中实现堆栈?
- 一个简单的程序来说明Python中的Stack。
- 有关在Python和相关程序中使用堆栈的更多信息
- 该 表内置
- 该 collections.deque类
- 该 queue.LifoQueue 类
什么是数据结构中的堆栈?
数据结构是组织计算机中存储的关键,以便我们可以有效地访问和编辑数据。 堆栈 是计算机科学中定义的最早的数据结构之一。简而言之,Stack是项目的线性集合。它是一组对象的集合,这些对象支持用于插入和删除的快速后进先出(LIFO)语义。它是现代计算机编程 和CPU架构中使用的函数调用和参数的数组或列表结构 。类似于 餐厅中的一叠盘子,一叠中的元素按照 “后进先出”的顺序 从堆栈的顶部添加或删除。与列表或数组不同,则不允许对堆栈中包含的对象进行随机访问。
Stack中有两种类型的操作-
- 推入–将数据添加到堆栈中。
- 弹出–从堆栈中删除数据。
堆栈简单易学且易于实现,它们广泛地集成在许多软件中以执行各种任务。它们可以用数组或链表实现 。在 这里,我们将依靠 List数据结构。
为什么以及何时使用Stack?
堆栈是简单的数据结构,可让我们按顺序存储和检索数据。
谈到性能,正确的堆栈实现预期将花费 O(1)的 时间进行插入和删除操作。
要了解底层的Stack,请考虑一堆书。您在堆栈顶部添加了一本书,因此要拾取的第一本书将是添加到堆栈中的最后一本书。
现实世界中有很多堆栈用例,对它们的了解使我们能够轻松有效地解决许多数据存储问题。
假设您是一名开发人员,并且正在使用全新的文字处理器。您需要创建一个撤消功能-允许用户回溯其操作,直到会话开始。堆栈非常适合这种情况。我们可以通过将用户的每个动作推入堆栈来记录该动作。当用户想要撤消某个动作时,他们可以相应地从堆栈中弹出。
我们如何在Python中实现堆栈?
在Python中,我们可以通过以下方式实现python堆栈:
- 使用内置的List数据结构。Python的内置 List 数据结构带有模拟 堆栈 和 队列操作的方法。
- 使用双端队列库可以有效地在一个对象中提供堆栈和队列操作。
- 使用 queue.LifoQueue类。
如前所述,我们可以使用“ PUSH”操作将项目添加到堆栈中,并使用“ POP”操作删除项目 。
按键操作
推入–在堆栈顶部添加一个元素。请参考下图以了解更多信息:
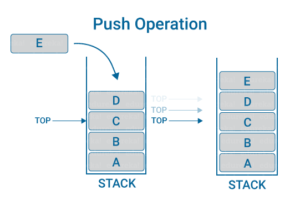
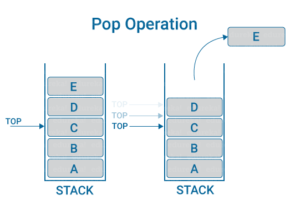
POP操作
Pop –从堆栈顶部删除一个元素。
这是一个简单的程序,用于说明Python中的堆栈-
class Stack
def_init_(self):
self.items=[]
def is_empty(self):
return self.items==[]
def push(self, data):
self.items.append(data)
def pop(self):
return self.items.pop()
s= Stack()
while True:
print(‘push<value>’)
print(‘pop’)
print(‘quit’)
do= input(‘What would you like to do?’).split()
operation= do[0].strip().lower()
if operation== ‘push’:
s.push(int(do[1]))
elif operation== ‘pop’:
if s.is_empty():
print(‘Stack is empty’)
else:
print(‘Popped value:’, s.pop())
elif operation==’quit’:
break有关在Python和相关程序中使用堆栈的更多信息
堆栈在算法中提供了广泛的用途,例如在语言解析和 运行时内存管理(“调用堆栈”)中。使用堆栈的一种简短而有用的算法是在树或图数据结构上进行深度优先搜索(DFS)。 Python玩几个堆栈实现,每个都有稍微不同的特征。让我们简单看一下它们:
该 表 内置
Python的内置列表类型构成了不错的堆栈数据结构,因为它支持在摊销的O(1) 时间内进行推入和弹出操作 。
Python的列表在内部以动态数组的形式实现,这意味着它们偶尔需要在添加或删除它们时调整存储在其中的元素的存储空间大小。存储空间的分配超出了要求,因此并非每次推送或弹出操作都需要调整大小,并且 这些操作将获得摊销的 O(1)时间复杂度。
尽管这会使它们的性能不如基于链接列表的实现提供的稳定的O(1)插入和删除操作一致 。另一方面,列表提供 对堆栈上元素的快速O(1)时间随机访问,这可能是一个附加好处。
使用列表作为堆栈时,这是一个重要的性能警告:
为了获得用于插入和删除的摊销 O(1)性能,可使用append()方法将new添加到列表的末尾,并使用pop()从末尾删除new。基于Python列表的堆栈向右扩展,向左收缩。
从前面进行添加和删除需要花费更多时间(O(n) 时间),因为现有元素必须四处移动才能为要添加的新元素腾出空间。
#使用Python列表作为堆栈(LIFO):
s = []
s.append('eat')
s.append('sleep')
s.append('code')
>>> s
['eat', 'sleep', 'code']
>>> s.pop()
'code'
>>> s.pop()
'sleep'
>>> s.pop()
'eat'
>>> s.pop()
IndexError: "pop from empty list"该 collections.deque 类
deque类实现了一个双端队列,该队列支持在O(1) 时间(未分期偿还)中从任一端添加和删除元素 。
由于双端队列在同等程度上支持在两端添加和删除元素,因此它们既可以用作队列也可以用作堆栈。
Python的双端队列对象被实现为双链表,这给它们提供了适当而一致的性能插入和删除元素,但是O(n) 性能差, 因为它们在堆栈中间随机访问元素。
如果您正在Python标准库中查找具有链接列表实现的性能特征的堆栈数据结构,则collections.deque是一个不错的选择。
#使用collections.deque作为堆栈(LIFO):
from collections import deque
q = deque()
q.append('eat')
q.append('sleep')
q.append('code')
>>> q
deque(['eat', 'sleep', 'code'])
>>> q.pop()
'code'
>>> q.pop()
'sleep'
>>> q.pop()
'eat'
>>> q.pop()
IndexError: "pop from an empty deque"该 queue.LifoQueue 类
Python标准库中的此堆栈实现是同步的,并提供锁定语义以支持多个并发的生产者和使用者。
的 队列模块 包含其它几类实施多生产者,多消费者队列是用于并行计算是有用的。
根据您的用例,锁定语义可能会有所帮助,或者只是产生不必要的开销。在这种情况下,最好使用列表或双端队列作为通用堆栈。
#使用queue.LifoQueue作为堆栈:
from queue import LifoQueue
s = LifoQueue()
s.put('eat')
s.put('sleep')
s.put('code')
>>> s
<queue.LifoQueue object at 0x108298dd8>
>>> s.get()
'code'
>>> s.get()
'sleep'
>>> s.get()
'eat'
>>> s.get_nowait()
queue.Empty
>>> s.get()
# Blocks / waits forever...如果到目前为止,您现在必须可以使用Python中的堆栈,希望此博客可以帮助您了解Python中堆栈的不同实现方法。
至此,我们的“ python堆栈”文章结束了。我希望您喜欢阅读此博客并发现它有启发性。到现在为止,您必须已经对python堆栈及其用法有了很好的了解。现在继续练习所有示例。

- 点赞
- 收藏
- 关注作者
评论(0)