高性能MySQL(二):服务器性能剖析


前言
我准备开一个新的系列,这是我以前接触不多的新领域,叫性能调优。
刷博客的时候,看到“性能调优”这个词的时候,我整个人都愣住了,感觉时间停滞了。
我发现,我根本不知道我写的项目代码,性能属于什么水平,就算是烂,也不知道到底有多烂。 我使用的中间件,也不知道它们的性能如何。
这样不好。
本系列取材于《高性能MySQL》第三版,是我的学习笔记。
在他们的技术咨询生涯中,最常碰到的三个性能相关的服务请求是:如何确认服务器是否达到了性能最佳的状态、找出某条语句为什么执行不够快,以及诊断被用户描述成“停顿”、“堆积”或“卡死”的某些间歇性疑难杂症。
首先我们要保持空杯精神(对我来说,我的杯子一直是空的),抛弃掉一些关于性能的常见的误解。
性能优化简介
性能:性能即相应时间,这是一个非常重要的原则。我们通过任务和时间而不是资源来测量性能。
数据库服务器的目的是执行SQL语句,所以它关注的是查询或者语句(查询 == 发送给服务器的指令)。
优化:我们假设优化是服务器在一定的工作负载下尽可能的而减少响应时间。
这里就引申出第二个原则:无法测量就无法有效的优化,所以第一步应该测量时间花在什么地方。
有两种情况会导致不合适的测量:
在错误的时间启动和停止测量
测量的是聚合后的信息,而不是目标活动本身
- 1
- 2
完成一项任务所需要的时间可以分成两部分:执行时间和等待时间。如果需要优化任务的执行时间,最好的办法就是通过测量定位不同的子任务花费的时间,然后优化去掉一些子任务,降低子任务的执行频率,或者提升子任务的效率。而优化任务的等待时间则相对要复杂一些。
那么如何确认哪些子任务是优化的目标呢?这个时候性能剖析就可以派上用场了。
通过性能剖析进行优化
性能剖析一般有两个步骤:测量任务所花费的时间;然后对结果进行排序,将重要的任务排到前面。
我们将实际的讨论两种类型的性能剖析:基于执行时间的分析和基于等待的分析。
基于时间的分析研究的是什么任务的执行时间最长,而基于等待的分析则是判断任务在什么地方被阻塞的时间最长。
(突然感觉有点郁闷,这一章一直看不通,外面都在说用explain,但是我总觉得还有更核心的问题。会是慢查询日志吗?)
后面会讲一个性能测试工具:pt-qurey-digest,前面就先看着吧。
理解性能剖析
1、值的优化的查询
性能剖析不会自动给出哪些查询值得时间去优化。
对一个占总响应时间不超过5%的查询进行优化,无论如何努力,收益也不会超过5%。第二,如果花费了1000美元去优化一个任务,但业务的收入没有增加,那么可以说反而导致了业务的逆优化。如果优化的成本大于收益,就应该停止优化。
2、异常优化
某些任务即使没有出现再性能剖析输出的前面,也需要优化,比如某些任务执行的次数很少,但是每次执行都非常慢,严重影响用户体验。因为其执行频率低,所以总的响应时间占比并不突出。
3、未知的未知
要知道,工具始终是有局限性的。
剖析MySQL查询
在MySQL当前版本中,慢查询日志是开销最低、精度最高的测量查询时间的工具。慢查询日志带来的I/O开销可以忽略不计,更需要担心的是日志可能消耗大量的磁盘空间。如果长期开启慢查询日志,要注意部署日志轮转工具。或者不要长期开启慢查询日志,只在需要收集负载样本的期间开启即可。
慢查询日志
MySQL 慢查询日志是排查问题 SQL 语句,以及检查当前 MySQL 性能的一个重要功能。
- 查看是否开启慢查询功能:
mysql> show variables like 'slow_query%';
+---------------------+-----------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
+---------------------+-----------------------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
slow_query_log 慢查询开启状态
slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
long_query_time 查询超过多少秒才记录
默认没有开启慢查询日志记录,通过命令临时开启:
set global slow_query_log='ON';
set global slow_query_log_file='/var/lib/mysql/instance-1-slow.log';
set global long_query_time=2;
- 1
- 2
- 3
永久配置:(自取,我就不永久了)
修改配置文件达到永久配置状态:
/etc/mysql/conf.d/mysql.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/instance-1-slow.log
long_query_time = 2
配置好后,重新启动 MySQL 即可。
测试
通过运行下面的命令,达到问题 SQL 语句的执行:
mysql> select sleep(2);
+----------+
| sleep(2) |
+----------+
| 0 |
+----------+
1 row in set (2.00 sec)
然后查看慢查询日志内容:
$ cat /var/lib/mysql/instance-1-slow.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
不要直接打开整个慢查询日志进行分析,这样只会浪费时间和金钱。
建议使用pt-query-digest生成一个剖析报告,如果必要,可以再查看日志中需要关注的部分。
pt-query-digest
pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
下载:
wget https://www.percona.com/downloads/percona-toolkit/3.2.1/binary/redhat/7/x86_64/percona-toolkit-3.2.1-1.el7.x86_64.rpm
- 1
ls | grep percona-toolkit-3.2.1-1.el7.x86_64.rpm
- 1
PT 工具是使用 Perl 语言编写和执行的,所以需要系统中有 Perl 环境。安装相关的依赖包,
[root@xxx ~]# yum install perl-DBI.x86_64
[root@xxx ~]# yum install perl-DBD-MySQL.x86_64
[root@xxx ~]# yum install perl-IO-Socket-SSL.noarch
[root@xxx ~]# yum install perl-Digest-MD5.x86_64
[root@xxx ~]# yum install perl-TermReadKey.x86_64
- 1
- 2
- 3
- 4
- 5
安装 Percona Toolkit:
rpm -iv percona-toolkit-3.2.1-1.el7.x86_64.rpm
- 1
rpm -qa | grep percona
- 1
工具目录安装路径:/usr/bin
下载的跟乌龟一样慢,我就先拿些现成的来了。加速包又一直解析不出来。。
解析慢查询日志:
pt-query-digest /var/lib/mysql/VM_0_9_centos-slow.log > slow_report.log
- 1
输出结果分为3部分:
汇总信息
[root@VM_0_9_centos ~]# more slow_report.log
# 230ms user time, 20ms system time, 26.35M rss, 220.76M vsz # CPU和内存使用信息
# Current date: Wed Aug 26 15:44:46 2020 # 当前时间
# Hostname: VM_0_9_centos # 主机名
# Files: /var/lib/mysql/VM_0_9_centos-slow.log # 输入的慢日志路径
## 整个分析结果的汇总信息
# Overall: 258 total, 37 unique, 0.02 QPS, 0.00x concurrency _____________
# Time range: 2020-08-26T11:20:16 to 2020-08-26T15:44:11
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 7s 249us 5s 26ms 4ms 311ms 657us
# Lock time 349ms 0 152ms 1ms 348us 12ms 194us
# Rows sent 33.01k 0 9.77k 131.03 755.64 742.92 0.99
# Rows examine 93.32k 0 9.77k 370.38 874.75 775.00 54.21
# Query size 51.71k 15 7.23k 205.23 223.14 615.30 143.84
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Overall:总共有多少个查询,该例总共有2.58k(2580)个查询。
Time range:查询执行的时间范围。注意,MySQL5.7版本中的时间格式不同于之 前的版本。
Unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查 询。该例为10个。
Attribute:如上述代码段所示,表示Attribute列描述的Exec time、Lock time等属性 名称。
total:表示Attribute列描述的Exec time、Lock time等属性的统计数值。
min:表示Attribute列描述的Exec time、Lock time等属性的最小值。
max:表示Attribute列描述的Exec time、Lock time等属性的最大值。
avg:表示Attribute列描述的Exec time、Lock time等属性的平均值。
95%:表示Attribute列描述的Exec time、Lock time等属性的所有值从小到大排 列,然后取位于95%位置的那个数值(需要重点关注这个值)。
stddev:标准偏差,用于数值的分布统计。
median:表示Attribute列描述的Exec time、Lock time等属性的中位数,即把所有 值从小到大排列,取位于中间的那个数值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
第二部分:
对查询进行参数化并分组,然后对各类查询的执行情况进行分析,结果按总执行时间从大到小排列
# Profile
# Rank Query ID Response time Calls R/Call V/M It
# ==== =============================== ============= ===== ====== ===== ==
# 1 0x59A74D08D407B5EDF9A57DD5A4... 5.0003 73.7% 1 5.0003 0.00 SELECT
# 2 0x64EF0EA126730002088884A136... 0.9650 14.2% 2 0.4825 0.01
# 3 0x5E1B3DE19F673369DCF52FE6A5... 0.3174 4.7% 2 0.1587 0.00 INSERT data_million_a
# 4 0x3992A499999D8F9E3ACC220E0F... 0.1334 2.0% 1 0.1334 0.00 ALTER TABLE dtb_table_size `dtb_table_size`
# 5 0x66CAA645BA3ED5433EADC39CCA... 0.0991 1.5% 2 0.0495 0.08 SELECT data_million_a
# MISC 0xMISC 0.2735 4.0% 250 0.0011 0.0 <32 ITEMS>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Rank:为查询生成的数字编号,表示该分类语句在整个分析结果集中的排名。
Query ID:为查询生成的随机字符串ID(根据指纹语句生成的checksum随机字符串)。
Response time:该查询的总的响应时间和占所有查询的总的响应时间的百分比。
Calls:该查询的执行次数,即本次分析总共有多少条这种类型的查询语句。
R/Call:该查询平均每次执行的响应时间。
V/M:响应时间的方差与均值的比值。
Item:具体的查询语句对象(标准化格式转换的语句形式:去掉了具体的select字段和表名、where条件等)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
第三部分:
按照语句执行的总时间,从大到小依次打印每条语句的相关统计信息
# Query 1: 0 QPS, 0x concurrency, ID 0x59A74D08D407B5EDF9A57DD5A41825CA at byte 0
# Scores: V/M = 0.00
# Time range: all events occurred at 2020-08-26T11:20:16
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 1
# Exec time 73 5s 5s 5s 5s 5s 0 5s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 0 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0
# Query size 0 15 15 15 15 15 0 15
# String:
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(5)\G
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Time range:查询执行的时间范围。注意,MySQL5.7版本中的时间格式不同于之 前的版本。
Attribute:如上述代码段所示,表示Attribute列描述的Count、Exec time、Lock time等属性名称。
pct:表示该分组语句(这里指上述代码段中“Query 1”代表的分组语句,具体的语 句样本在EXPLAIN ...关键字下面有输出。另外,在上述代码段中,如total、min等计算值
都是针对该语句分组的,下文中不再赘述)的total值(该分组语句的统计值)与统计样本 中总的所有语句统计值的占比。
total:表示Attribute列描述的Count、Exec time、Lock time等属性的统计值。
min:表示Attribute列描述的Exec time、Lock time等属性的最小值。
max:表示Attribute列描述的Exec time、Lock time等属性的最大值。
avg:表示Attribute列描述的Exec time、Lock time等属性的平均值。
95%:表示语句对应的Exec time、Lock time等属性值从大到小排序之后,位于 95%位置的那个数值(需要重点关注这个值)。
stddev:标准偏差,用于数值的分布统计。
median:代表对应属性值的中位数,将所有值从小到大排列,取位于中间的那个 数值。
Databases:库名。
Users:各个用户执行的次数(占比)。
Query_time distribution:查询时间分布,由“#”字符表示的长短体现了语句执行时 间的占比区间。从上述代码段中可以看到,执行时间在1s左右的查询数量占绝大多数。
Tables:使用查询语句中涉及的表生成的用于查询表统计信息和表结构的SQL语 句文本。
EXPLAIN:表示查询语句的样本(方便复制出来查看执行计划。注意,该语句不 是随机生成的,而是分组语句中最差的查询SQL语句)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
优秀资料
参考资料来源:Mysql性能瓶颈深度定位分析
我们在性能测试过程中,经常会遇到Mysql出现性能瓶颈的情况,对于数据库来说,所谓的性能瓶颈无非是慢SQL、CPU高、IO高、内存高,其中前三个举实际例子来进行性能分析,最后内存高只是方法性说明(实际测试项目中没遇到过):
首先我们要保证没有数据库配置方面的性能问题,毕竟在性能测试前,对一些基本配置要撸一遍,避免犯低级错误。
慢SQL定位分析
首先业务系统慢,肯定是体现在响应时间上,所以在性能测试中,如果发现慢我们就从响应时间上进行拆分,最后拆到mysql,那就是分析慢SQL,同样如果在高并发时发现mysql进程占CPU很高,也是优先分析是否存在慢SQL,而且判断慢SQL还是比较简单的,对于Mysql就是看慢日志查询。
获取到慢SQL,当然是要实际验证一下有多慢,是否索引配置了,拿一条实际测试项目的SQL语句来分析:
explain SELECT count(c.id) FROM administrative_check_content c LEFT JOIN administrative_check_report_enforcers e ON c.report_id=e.report_id LEFT JOIN administrative_check_report r ON c.report_id = r.id WHERE e.enforcer_id= 'ec66d95c8c6d437b9e3a460f93f1a592';
- 1
- 2
- 3
- 4
- 5
可以分析出这条语句,86%的时间是花在了Sending data(所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 [检索] + 发送数据”):
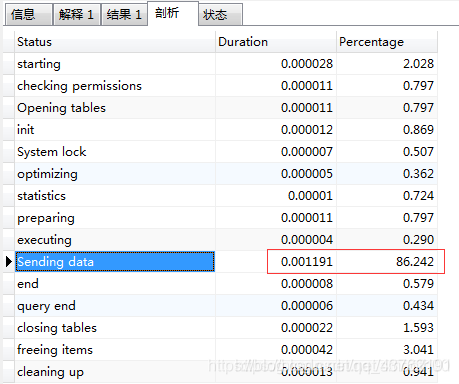
用show profile进行sql分析:
开启分析也很简单,使用临时开启执行set profiling=1即可(这个功能会缓存最近查询的分析语句,默认15条,最多100条,适合在压测结束后开展sql分析,用完后再设成0关闭),如下:
#显示是否开启Profiling,以及最多存储多少条
show variables like '%profil%';
#开启Profiling
set profiling=1;
#执行你的SQL
#在这里我们主要是执行前面所找到的慢SQL
#查看分析
show profiles;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过show profiles我们可以看到我们上面执行的那条SQL(Query_ID=18,为了确保监视最新的数据,Query_ID最好取25)
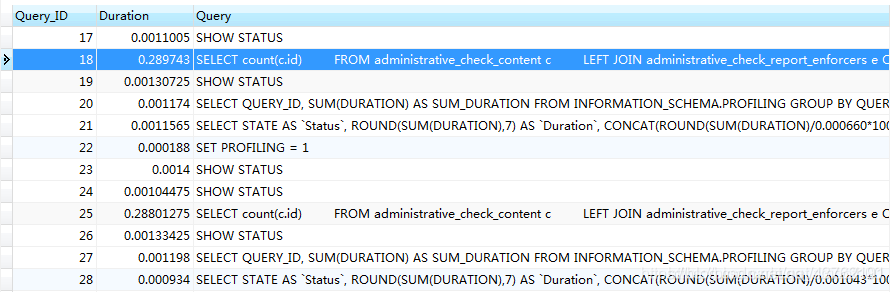
执行:show profile cpu,memory,block io for query 18;
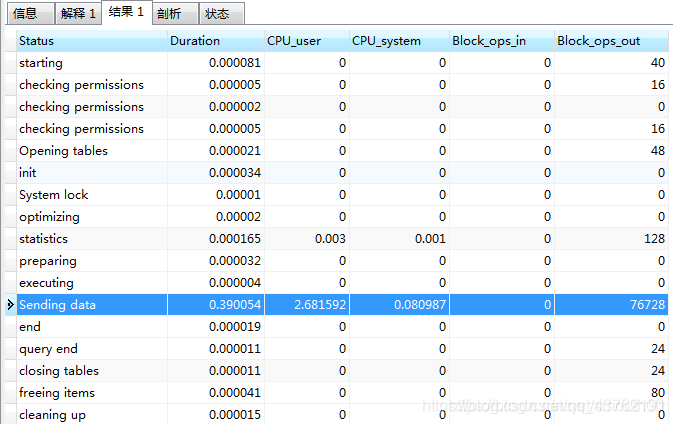
可以看出也是Sending data总共消耗0.39秒,其中CPU_user时间占比较高(简单的一条SQL语句消耗这些时间就算很高了),另外还能看到这条SQL的IO开销(因为查询,都是ops out块输出)
也可以通过SQL查表来查看以上记录:
select QUERY_ID,SEQ,STATE,DURATION,CPU_USER,CPU_SYSTEM,BLOCK_OPS_IN,BLOCK_OPS_OUT from information_schema.PROFILING where QUERY_ID = 18
- 1
另外说明一下这个show profile语句:
show profile cpu, block io, memory,swaps,context switches,source for query [Query_ID];
# Show profile后面的一些参数:
# - All:显示所有的开销信息
# - Cpu:显示cpu相关开销
# - Block io:显示块IO相关开销
# - Context switches: 上下文切换相关开销
# - Memory:显示内存相关开销
# - Source:显示和source_function,source_file,source_line相关的开销信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

哎,水了水了。
文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/113919571

- 点赞
- 收藏
- 关注作者
评论(0)