蓝桥杯节点选择(java)第一道树形dp分析

【摘要】 蓝桥杯 节点选择
问题描述 有一棵 n 个节点的树,树上每个节点都有一个正整数权值。如果一个点被选择了,那么在树上和它相邻的点都不能被选择。求选出的点的权值和最大是多少?
输入格式 第一行包含一个整数 n 。
接下来的一行包含 n 个正整数,第 i 个正整数代表点 i 的权值。
接下来一共 n-1 行,每行描述树上的一条边。
输出格式 输出一个整数,代表选出的...
蓝桥杯 节点选择
问题描述
有一棵 n 个节点的树,树上每个节点都有一个正整数权值。如果一个点被选择了,那么在树上和它相邻的点都不能被选择。求选出的点的权值和最大是多少?
输入格式
第一行包含一个整数 n 。
接下来的一行包含 n 个正整数,第 i 个正整数代表点 i 的权值。
接下来一共 n-1 行,每行描述树上的一条边。
输出格式
输出一个整数,代表选出的点的权值和的最大值。
样例输入
5
1 2 3 4 5
1 2
1 3
2 4
2 5
样例输出
12
样例说明
选择3、4、5号点,权值和为 3 4 5 = 12 。
数据规模与约定
对于20%的数据, n <= 20。
对于50%的数据, n <= 1000。
对于100%的数据, n <= 100000。
权值均为不超过1000的正整数。
分析
- 看到蓝桥杯的树形dp题,刚开始看的很蒙蔽。从来没做过树形的dp,刚开始表示很难理解,当时主要的疑惑点有一下几点:
1:这个树怎么解决?这么乱的一棵树感觉根本无法下手,因为你不知道那个是根节点,那个是子节点。输出的结果又和那个有关系?
2:树形怎么dp?以前都是遇到线性区间的dp,树形dp,怎么查找连续点,就算找到连续的点交叉点如何处理? - 看了一些博客和文章之后,有了解到dp处理树形的特殊手段:
一: 一般来说,树形dp的每个节点都有一个选择性,本题就是该店选择和不选择,dp[i][0]表示不选择,dp[i][1]表示选择该节点。
二:对于树形dp,一般要和搜索结合(更确切的说是递归)结合,对于树的划分层次,一般是选择一个点,然后从这个点进行往下搜索 ,他的邻居都变成他的子节点。也就是相当于从这个根节点除法,可能有很多分叉。也就是有很多分叉会到根节点。但是这有和dp有啥关系呢?dp是从尾到头还是从头到尾?
三:对于顺序的选择肯定是从尾部到顶部,因为dp要的是一个整合结果而不是分散求最值或者其他。那么还有问题就是那么多的跟节点,那么多合的点,还有反向路径不好记录,记录的难度和开销都超级大。如果从尾部推到dp还是有一定难度。
四:我们要先抛开整体看局部这个点,对于某个单点来说(如果他是头节点),分析到他的结果,如果取他那么他的儿子们都不能取,那么dp[i][1]=dp[儿子们][0] value[i];如果不取他,那么对于每个儿子来说要给最大的,那么dp[i][0]=max(dp[每个儿子][0],dp[每个儿子][1]);这样就得到递推式dp[x][0]=sum(max(dp[num][0],dp[num][1]));dp[x][1]=sum(dp[num][0]) value[i].
五:对于头节点(可以任选),满足④,对于头节点的儿子也同样满足④,但是唯一不同的是要过滤头节点(准确的说是父节点)。防止死循环。递归搜索的过程是双向的过程,先去再回,我们可以同过先去构造树并且获得后面的一些信息,然后根据后来得到的值进行操作当前等级的dp。 - 总的来说这个树形dp就是分析某个点的状态方程,通过递归搜索进行划分树。获得结果。并且这题只有n-1条路径,n个点,不用考虑去重。
附上代码:
package 算法训练;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.StreamTokenizer;
import java.util.ArrayList;
import java.util.List;
public class 节点选择 { // static boolean jud[]; static int dp[][];//dp数组 static int value[];//保存权值 static List <Integer>[]list;//邻接表储存图。节省空间
public static void main(String[] args) throws IOException {
// TODO 自动生成的方法存根
StreamTokenizer in=new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
in.nextToken();
int n=(int)in.nval;
value=new int[n];//权值
dp=new int[n][2];
list=new ArrayList[n]; for(int i=0;i<n;i++) {list[i]=new ArrayList<>();}
for(int i=0;i<n;i++)
{ in.nextToken(); value[i]=(int)in.nval;
}
for(int i=0;i<n-1;i++)
{ in.nextToken(); int t1=(int)in.nval; in.nextToken();int t2=(int)in.nval; list[t1-1].add(t2-1);//添加路径 list[t2-1].add(t1-1); }
dfs(0,-1);//理论上任意n之内节点都可以,但是右侧第一个理论上保证不是这个点的父亲
int value=max(dp[0][0], dp[0][1]);
out.println(value);
out.flush();
}
private static void dfs(int x, int y) {//当前节点,父亲节点
for(int i=0;i<list[x].size();i++)
{ int num=list[x].get(i); if(num!=y)//不是父亲节点 { dfs(num,x); dp[x][0]+=max(dp[num][0],dp[num][1]); dp[x][1]+=dp[num][0]; }
}
dp[x][1]+=value[x];//加上自己的权值 }
private static int max(int i, int j) {
// TODO 自动生成的方法存根
return i>=j?i:j;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
但是结果只能过7个,

看了下其他人没优化输入的只能过5个超时。我用测试数据测试了一下原因是栈内存溢出。苦逼的Java。。
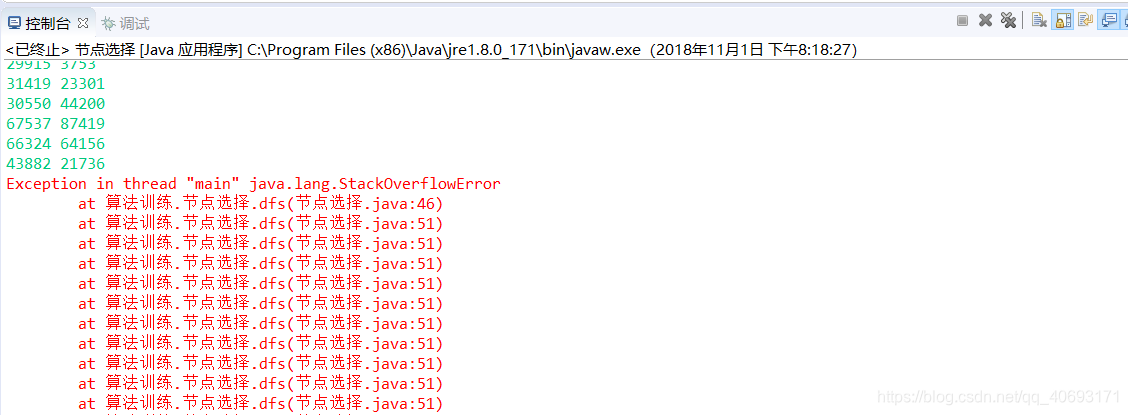
也可能是因为我比较菜,,想不出好的方法,呵呵,。欢迎大佬踢场。。
文章来源: bigsai.blog.csdn.net,作者:Big sai,版权归原作者所有,如需转载,请联系作者。
原文链接:bigsai.blog.csdn.net/article/details/83627755

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)