Hadoop环境搭建测试以及MapReduce实例实现

目录
2.4 搭建eclipse环境编程实现Wordcount程序
1 任务
- 熟悉常用的 Hadoop 命令
- 运行 Wordcount 实例
- 搭建 Eclipse 编程环境
- 编程实现 Wordcount 程序
2 过程
2.1 熟悉常用的 Hadoop 命令
1.利用Shell命令操作
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
注意
有三种shell命令方式的区别:
(1) hadoop fs
(2) hadoop dfs
(3) hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令
./bin/hadoop fs

2.查看help命令如何使用

3.利用HDFS的Web界面管理
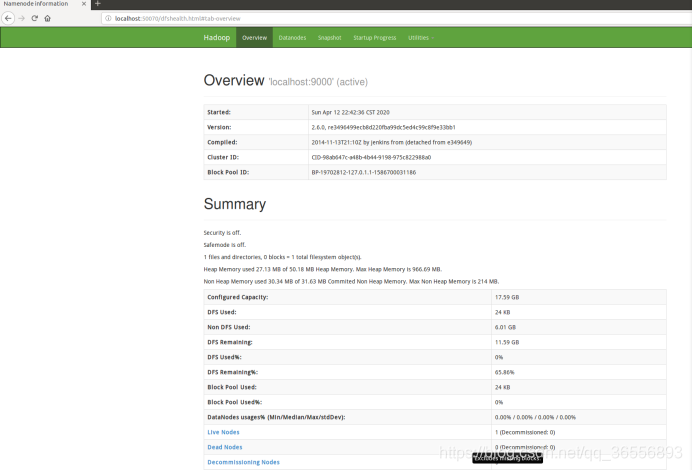
2.2 Hadoop环境搭建
1.SSH登录权限设置
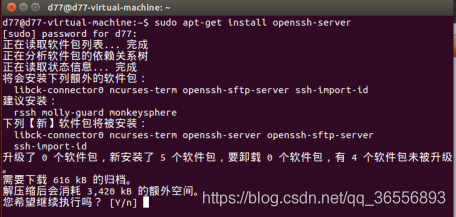
(1) Ubuntu 默认已安装了 SSH client,现在安装 SSH server:
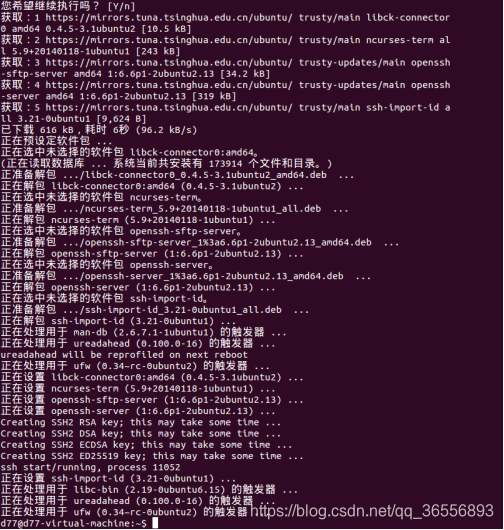
(2)安装成功后
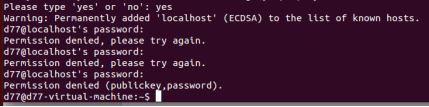
(3)登录
![]()
(4)登录成功
2.安装Java环境
(1)下载JDK1.7.0

(2)下载成功

(3)环境变量的配置

(4)保存.bashrc文件并退出vim编辑器并命令让.bashrc文件的配置立即生效
![]()
(5)查看是否安装成功

3.Hadoop的安装
(1)在计算机中建立一个共享文件夹,并将hadoop下载到其中,并解压

(2)将文件名改为hadoop
![]()
(3)修改文件权限
![]()
(4)检查版本信息

4.伪分布式安装配置
(1)修改配置文件core-site.xml

(2)修改配置文件hdfs-site.xml
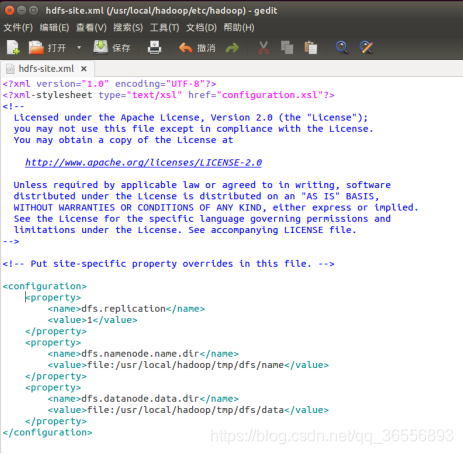
(3)初始化文件系统
![]()
(4)初始化过程中出现环境变量配置问题,因此我们打开hadoop-env.sh文件进行修改
![]()
(5)修改后,再次进行初始化
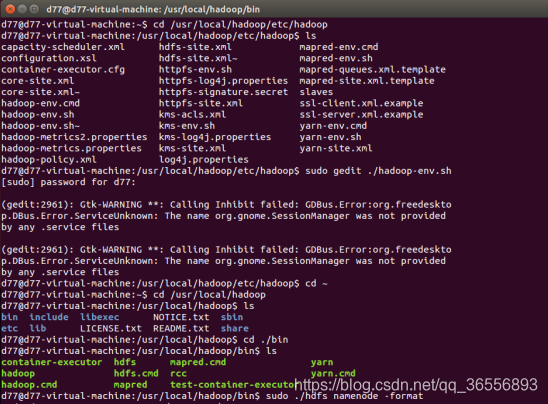
(6)初始化成功
2.3 Wordcount实例
1.格式化namenode
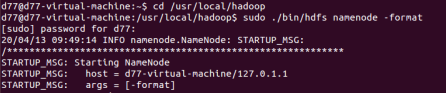
2.格式化成功
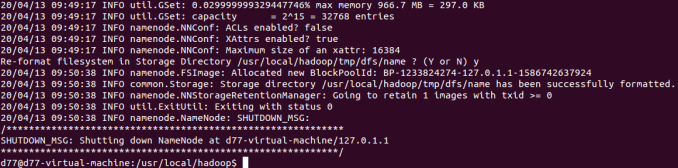
3.启动进程

4.查看进程

5.把本地到hadoop/input (自己建立的)文件夹中到文件上传到hdfs文件系统到input文件夹下
![]()
6.查看文件是否上传成功
![]()
7.运行wordcount实例

8.查看mapreduce进度

9.查看运行结果

10.将运行结果取回本地文件系统

11.关闭进程
2.4 搭建eclipse环境编程实现Wordcount程序
1、安装eclipse
(1) 下载eclipse
(2)安装并创建快捷方式

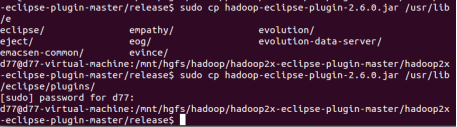
(3)下载并安装Hadoop-Eclipse-Plugin,在共享文件夹中下载,再解压
2.配置Hadoop-Eclipse-Plugin
(1)启动eclipse
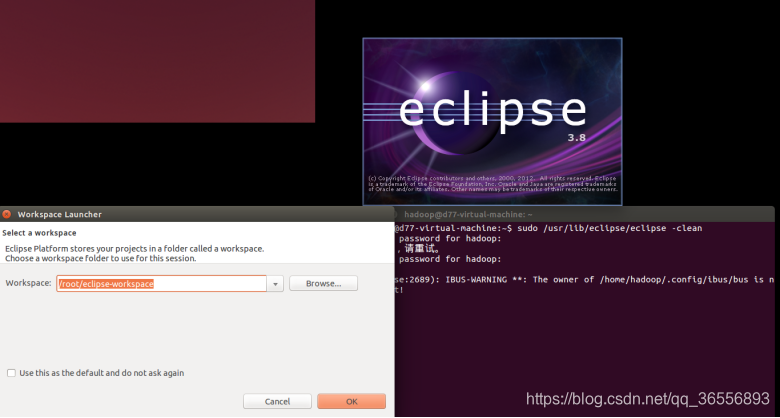
(2)安装好Hadoop-Eclipse-Plugin插件的效果
(3)对插件的进一步配置
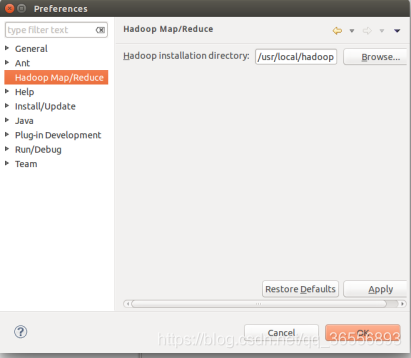
① 选择Hadoop的安装目录
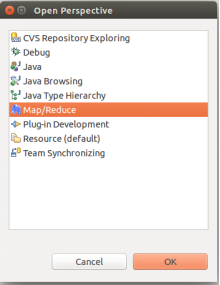
② 切换Map/Reduce开发视图
③ Hadoop Location的设置
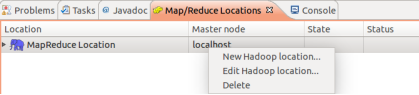
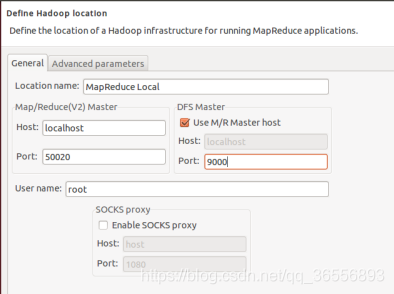
④ 建立与Hadoop集群的连接
3.在Eclipse中操作HDFS中的文件
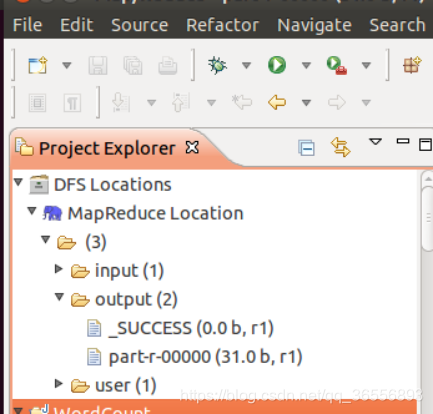
配置好后,点击左侧 Project Explorer 中的 MapReduce Location (点击三角形展开)就能直接查看 HDFS 中的文件列表了(HDFS 中要有文件,如下图是 WordCount 的输出结果),双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件,无需再通过繁琐的 hdfs dfs -ls 等命令进行操作了。
以下output/part-r-00000文件记录了输出结果。
4.在Eclipse中创建MapReduce项目
(1) 创建Project
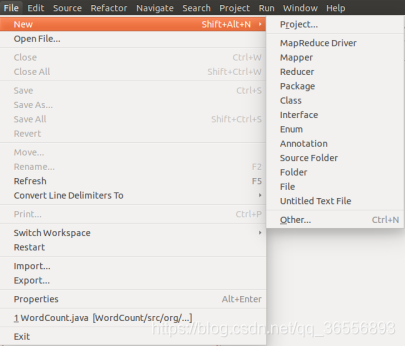
(2)创建MapReduce项目
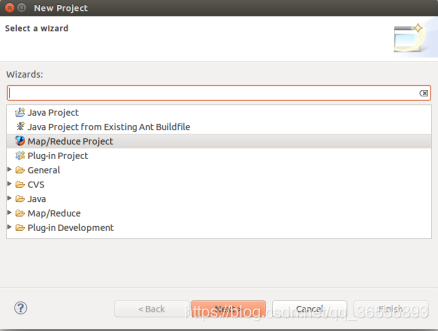
(3)填写项目名
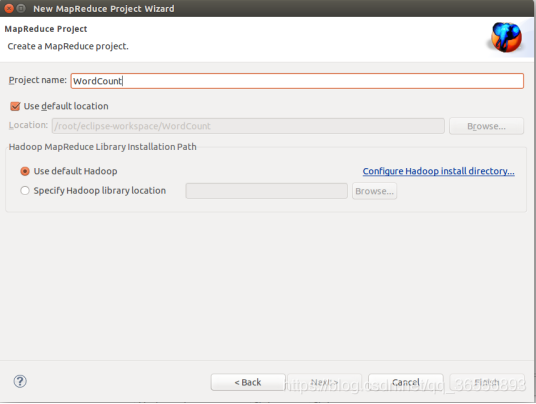
(4)项目创建完成
(5)新建Class
(6)填写Class信息

(7)编辑WordCount.java文件
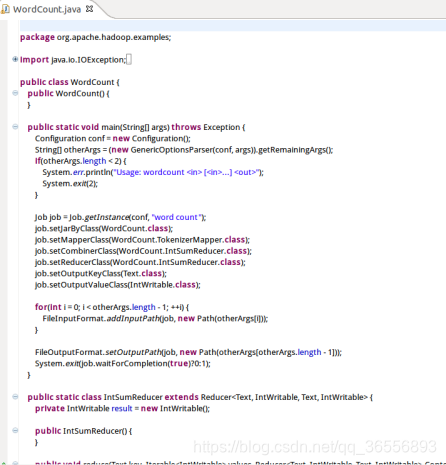
5.通过 Eclipse 运行 MapReduce
(1) 将 /usr/local/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 复制到WordCount 项目下的 src 文件夹
(2)Wordcount运行结果同shell指令结果对比

2.5基于Hadoop的数据去重实例实现
1.实例描述
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
2.设计思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个<key,value-list>时就直接将key复制到输出的key中,并将value设置成空值。
在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会交给reduce。所以从设计好的reduce输入可以反推出map的输出key应为数据,value任意。继续反推,map输出数据的key为数据,而在这个实例中每个数据代表输入文件中的一行内容,所以map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将value设置为key,并直接输出(输出中的value任意)。map中的结果经过shuffle过程之后交给reduce。reduce阶段不会管每个key有多少个value,它直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空了)。
3.程序部分代码
-
public class WordCountDatededuplication {
-
-
//map将输入中的value复制到输出数据的key上,并直接输出
-
public static class Map extends Mapper<Object,Text,Text,Text>{
-
private static Text line=new Text();//每行数据
-
-
//实现map函数
-
public void map(Object key,Text value,Context context)
-
throws IOException,InterruptedException{
-
line=value;
-
context.write(line, new Text(""));
-
}
-
}
-
-
//reduce将输入中的key复制到输出数据的key上,并直接输出
-
public static class Reduce extends Reducer<Text,Text,Text,Text>{
-
//实现reduce函数
-
public void reduce(Text key,Iterable<Text> values,Context context)
-
throws IOException,InterruptedException{
-
context.write(key, new Text(""));
-
}
-
}
-
-
public static void main(String[] args) throws Exception{
-
Configuration conf = new Configuration();
-
//这句话很关键
-
conf.set("mapred.job.tracker", "192.168.1.2:9001");
-
-
String[] ioArgs=new String[]{"dedup_in","dedup_out"};
-
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
-
if (otherArgs.length != 2) {
-
System.err.println("Usage: Data Deduplication <in> <out>");
-
System.exit(2);
-
}
-
-
Job job = new Job(conf, "Data Deduplication");
-
job.setJarByClass(Dedup.class);
-
-
//设置Map、Combine和Reduce处理类
-
job.setMapperClass(Map.class);
-
job.setCombinerClass(Reduce.class);
-
job.setReducerClass(Reduce.class);
-
-
//设置输出类型
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(Text.class);
-
-
//设置输入和输出目录
-
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
-
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
-
System.exit(job.waitForCompletion(true) ? 0 : 1);
-
}
-
}
4.实验结果
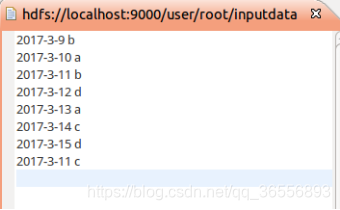
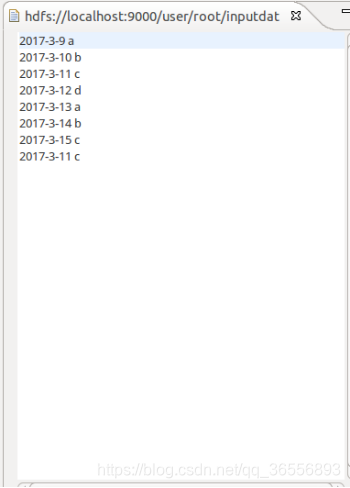
(1)准备测试数据
创建文件夹inputdatadeduplication,并在该文件夹下创建两个文件data1.txt和data2.txt

data1.txt文件:
data2.txt文件:
(2)查看运行结果
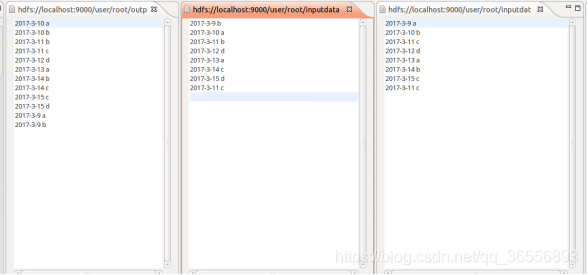
3 总结
首先我们启动eclipse需要管理员的权限,这样我们在运行这个程序时,避免了“无法访问”的错误。
MapReduce实例实现的主要难点是代码的编写.
希望各位既可以掌握Hadoop伪分布式的搭建过程,也熟悉一些Linux指令,锻炼动手能力。
文章来源: nickhuang1996.blog.csdn.net,作者:悲恋花丶无心之人,版权归原作者所有,如需转载,请联系作者。
原文链接:nickhuang1996.blog.csdn.net/article/details/109261209

- 点赞
- 收藏
- 关注作者
评论(0)