java使用ZipOutputStream对文件进行压缩

【摘要】
目录
java处理文件压缩的类ZipOutStream压缩文件1.putNextEntry(new ZipEntry(""))2.write()
java处理文件压缩的类
java中常用ZipOutStream进行文件的压缩,用ZipInputStream对文件进行解压,zip相对于其他的文件的io稍有一点点不同的就是:它的内部就是一个小型...
java处理文件压缩的类
java中常用ZipOutStream进行文件的压缩,用ZipInputStream对文件进行解压,zip相对于其他的文件的io稍有一点点不同的就是:它的内部就是一个小型的文件系统。如果是一个文件夹所有文件都是文档二不是文件夹。那还好办直接操作。如果涉及到文件夹和文档的不固定分布。那就需要仔细考虑下。这里用递归进行遍历。
ZipOutStream压缩文件
主要两个方法:
1.putNextEntry(new ZipEntry(""))
这里面重要的就是ZipEntry这个概念首先要懂。ZipEntry是zip下面的文件条目,你可以比作外面系统的File类似。后面的参数就是在zip目录下的相对位置。所以这里有一点比较重要的就是当你遍历文件夹的时候你的ZipEntry的参数的改变规律。写不好的话会使整个文件目录混乱(如果文件层级较低那就不碍事)。而putNextEntry(ZipEntry z)的意思就是我下面io操作(写入)都是在z这个文件条目下进行的。
2.write()
这个zipoutputstream流和其他的output流不一样的地方就是BufferedOutputStream不能嵌套它。也就是它不能套缓存流用。
对于文件夹下包含文件夹需要特殊考虑。判断它是不是文件夹。文件夹的话要遍历他的子节点文件。用递归思想。已在代码中给出注释。还有文件要注意相对绝对路径。
贴上我的模板代码:
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
public class test1 {
public static void main(String[] args) throws IOException {
String filepath="F:\\fileget\\二班";//目标文件夹
String zipname="F:\\fileget\\二班软工作业.zip";//目标输出路径
filetozip(filepath,zipname);
}
public static void filetozip(String filepath,String zipname) throws IOException {
File file=new File(filepath);
OutputStream outputStream=new FileOutputStream(zipname);
ZipOutputStream zipout=new ZipOutputStream(outputStream); //递归函数 三个参数分别代表 1:当前zipout流 2:当前文件/文件夹 3:在zip下的path
dozip(zipout,file,""); zipout.finish();
zipout.close();
outputStream.close();
}
private static void dozip(ZipOutputStream zipout, File file, String addpath) throws IOException { if(file.isDirectory()) { File f[]=file.listFiles(); for(int i=0;i<f.length;i++) { if(f[i].isDirectory()) { dozip(zipout, f[i], addpath+f[i].getName()+"/"); } else { dozip(zipout, f[i], addpath+f[i].getName()); } } } else { InputStream input; BufferedInputStream buff; zipout.putNextEntry(new ZipEntry(addpath)); input=new FileInputStream(file); buff=new BufferedInputStream(input); byte b[]=new byte[1024*5]; int a=0; while((a=buff.read(b))!=-1) { zipout.write(b); } buff.close(); input.close(); System.out.println(file.getName()); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
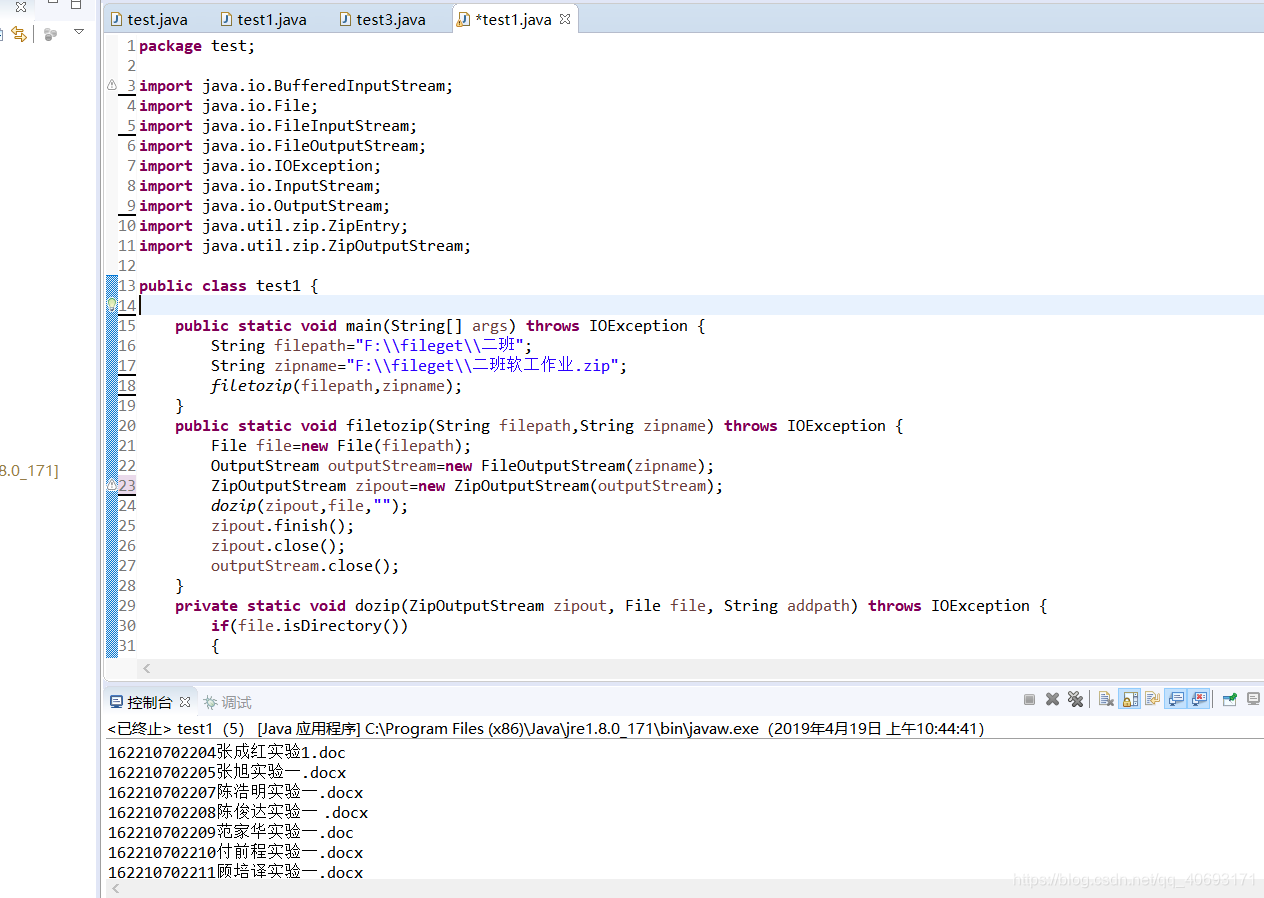
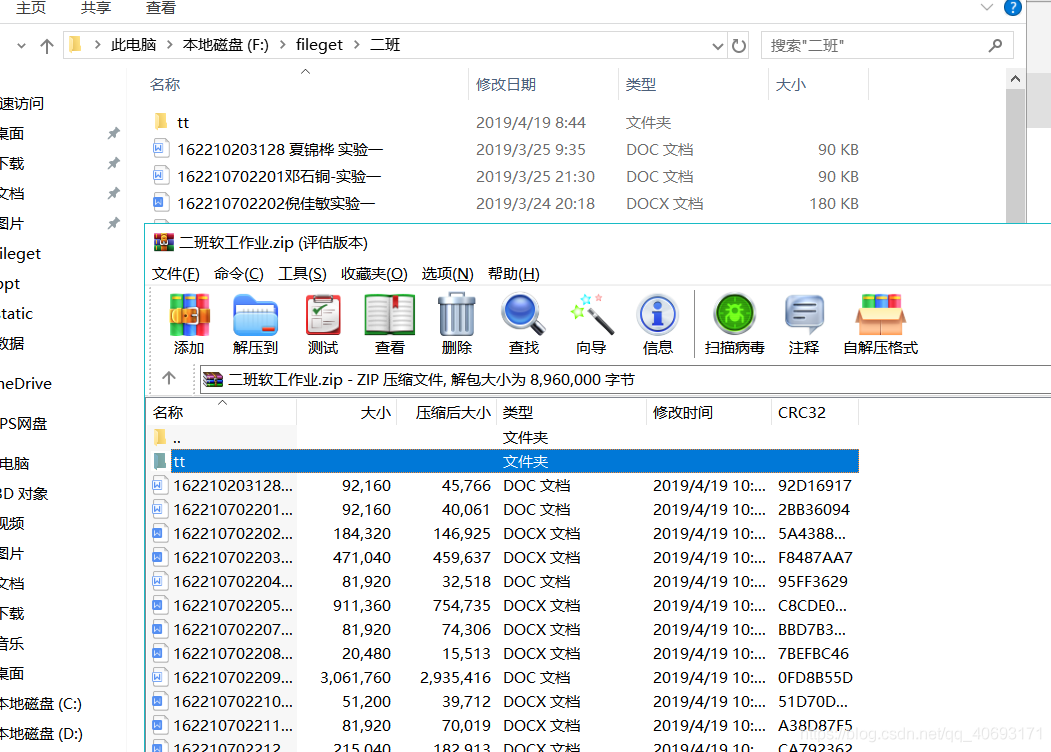
另外,解压的那个类后面有时间会补充下来。
- 如果对
后端、爬虫、数据结构算法等感性趣欢迎关注我的个人公众号交流:bigsai


文章来源: bigsai.blog.csdn.net,作者:Big sai,版权归原作者所有,如需转载,请联系作者。
原文链接:bigsai.blog.csdn.net/article/details/89406706

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)