面试官:谈谈Redis缓存和MySQL数据一致性问题

前言
对于Web来说,用户量和访问量增一定程度上推动项目技术和架构的更迭和进步。可能会有以下的一些状况:
- 页面并发量和访问量并不多,MySQL
足以支撑自己逻辑业务的发展。那么其实可以不加缓存。最多对静态页面进行缓存即可。 - 页面的并发量显著增多,数据库有些压力,并且有些数据更新频率较低
反复被查询或者查询速度较慢。那么就可以考虑使用缓存技术优化。对高命中的对象存到key-value形式的Redis中,那么,如果数据被命中,那么可以不经过效率很低的db。从高效的redis中查找到数据。 - 当然,可能还会遇到其他问题,你还通过静态页面缓存页面、cdn加速、甚至负载均衡这些方法提高系统并发量。这里就不做介绍。
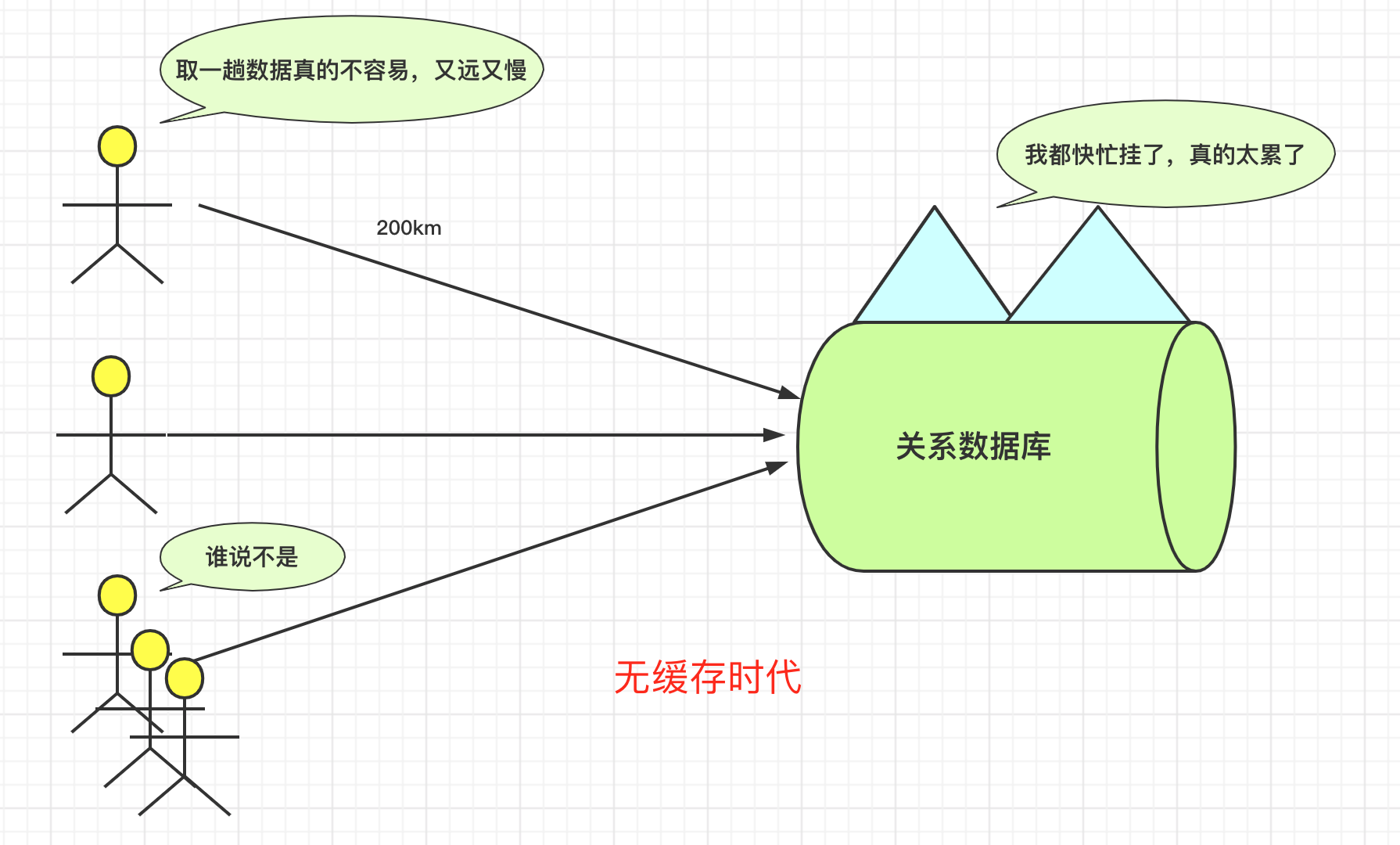
缓存思想无处不在
我们从一个算法问题开始了解缓存的意义。
问题1:
- 输入一个数n(n<20),求
n!;
分析1:
- 单单考虑算法,不考虑数值越界问题。
当然我们知道n!=n * (n-1) * (n-2) * ... * 1= n * (n-1)!;
那么我们可以用一个递归函数解决问题。
static long jiecheng(int n)
{
if(n==1||n==0)return 1;
else { return n*jiecheng(n-1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样每输入求一次需要执行n次。
问题2:
- 输入t组数据(可能成百上千),每组一个xi(xi<20),求
xi!;
分析2:
- 如果使用
递归,输入t组数据,每次输入为xi,那么每次都要执行次数为:

当每次输入的Xi过大或者t过大都会造成不小的负担!时间复杂度为O(n2) - 那么能否换个思想的。没错、是
打表。打表常用于ACM算法中,常用于解决多组输入输出、图论搜索结果、路径储存问题。那么,对于这个求阶乘。我们只需要申请一个数组,按照编号从前往后将在需求的数存到数组中,后面再取得时候直接输出数组值就可以,思想很明确吧:
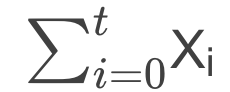
import java.util.Scanner;
public class test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc=new Scanner(System.in);
int t=sc.nextInt();
long jiecheng[]=new long[21];
jiecheng[0]=1;
for(int i=1;i<21;i++)
{
jiecheng[i]=jiecheng[i-1]*i;
} for(int i=0;i<t;i++) {
int x=sc.nextInt();
System.out.println(jiecheng[x]);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 时间复杂度才O(n)。这里的思想就和
缓存思想差不多。先将数据在jiecheng[21]数组中储存。执行一次计算。当后面继续访问的时候就相当于当问静态数组值。每次都为O(1的操作)。
缓存的应用场景
缓存适用于高并发的场景,提升服务容量。主要是将从经常被访问的数据或者查询成本较高从慢的介质中存到比较快的介质中,比如从硬盘—>内存。我们知道大多数关系数据库是基于硬盘读写的,其效率和资源有限,而redis是基于内存的,其读写速度差别差别很大。当并发过高关系数据库性能达到瓶颈时候,就可以策略性将常访问数据放到Redis提高系统吞吐和并发量。
对于常用网站和场景,关系数据库主要可能慢在两个地方:
- 读写IO性能较差
- 一个数据可能通过较大量计算得到
所以使用缓存能够减少磁盘IO次数和关系数据库的计算次数。读取上速度快也从两个方面体现:
- 基于内存,读写较快
- 使用哈希算法直接定位结果不需要计算
所以对于像样的,有点规模的网站,缓存是很 necessary的,而Redis无疑是最好的选择之一。
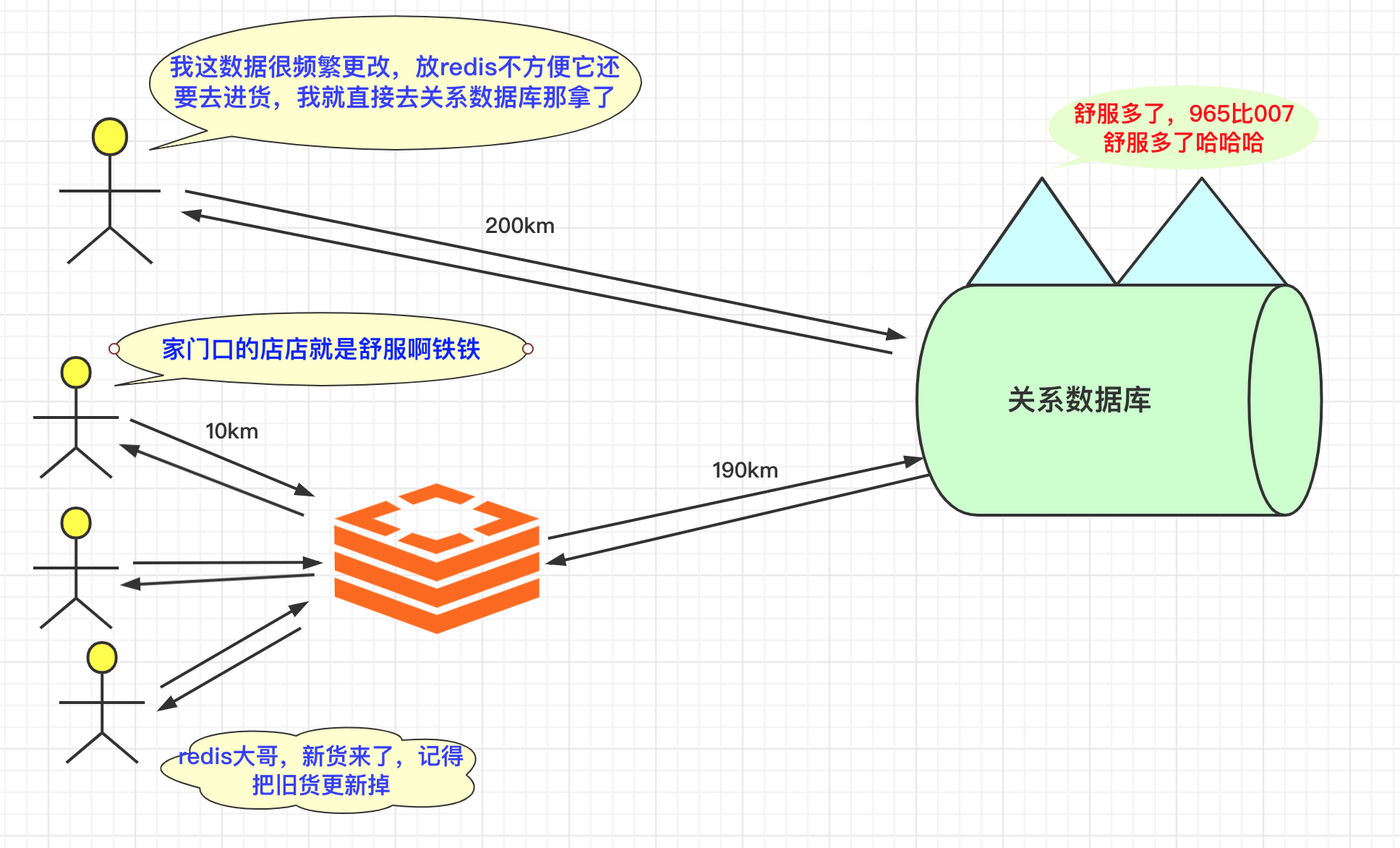
需要注意的问题
缓存使用不当会带来很多问题。所以需要对一些细节进行认真考量和设计。当然最难得数据一致性在下面单独分析。
是否用缓存
项目不能为了用缓存而用缓存,缓存并一定适合所有场景,如果对数据一致性要求极高,又或者数据频繁更改而查询并不多,又或者根本没并发量的、查询简单的不一定需要缓存,还可能浪费资源使得项目变得臃肿难维护,并且使用redis缓存多多少少可能会遇到数据一致性问题需要考虑。
缓存合理设计
在设计缓存的时候,很可能会遇到多表查询,如果遇到多表查询缓存的键值对就需要合理考虑,是拆分还是合在一起?当然如果组合种类多但常出现的不多也可以直接缓存,具体的设计要根据项目业务需求来看,并没有一个非常绝对的标准。
过期策略选择
- 缓存装的是相对热点和常用的数据,Redis资源也是有限,需要选择一个合理的策略让缓存过期删除。我们学过
操作系统也知道在计算机的缓存实现中有先进先出的算法(FIFO);最近最少使用算法(LRU);最佳淘汰算法(OPT);最少访问页面算法(LFR)等磁盘调度算法。设计Redis缓存时候也可以借鉴。根据时间来的FIFO是最好实现的。且Redis在全局key支持过期策略。 - 并且过期时间也要根据系统情况合理设置,如果硬件好点当前可以稍微久一点,但是过期时间过久或者过短可能都不太好,过短可能缓存命中率不高,而过久很可能造成很多冷门数据存储在Redis中不释放。
数据一致性问题★
上面其实提到数据一致性问题。如果对一致性要求极高那么不建议使用缓存。下面稍微梳理一下缓存的数据。
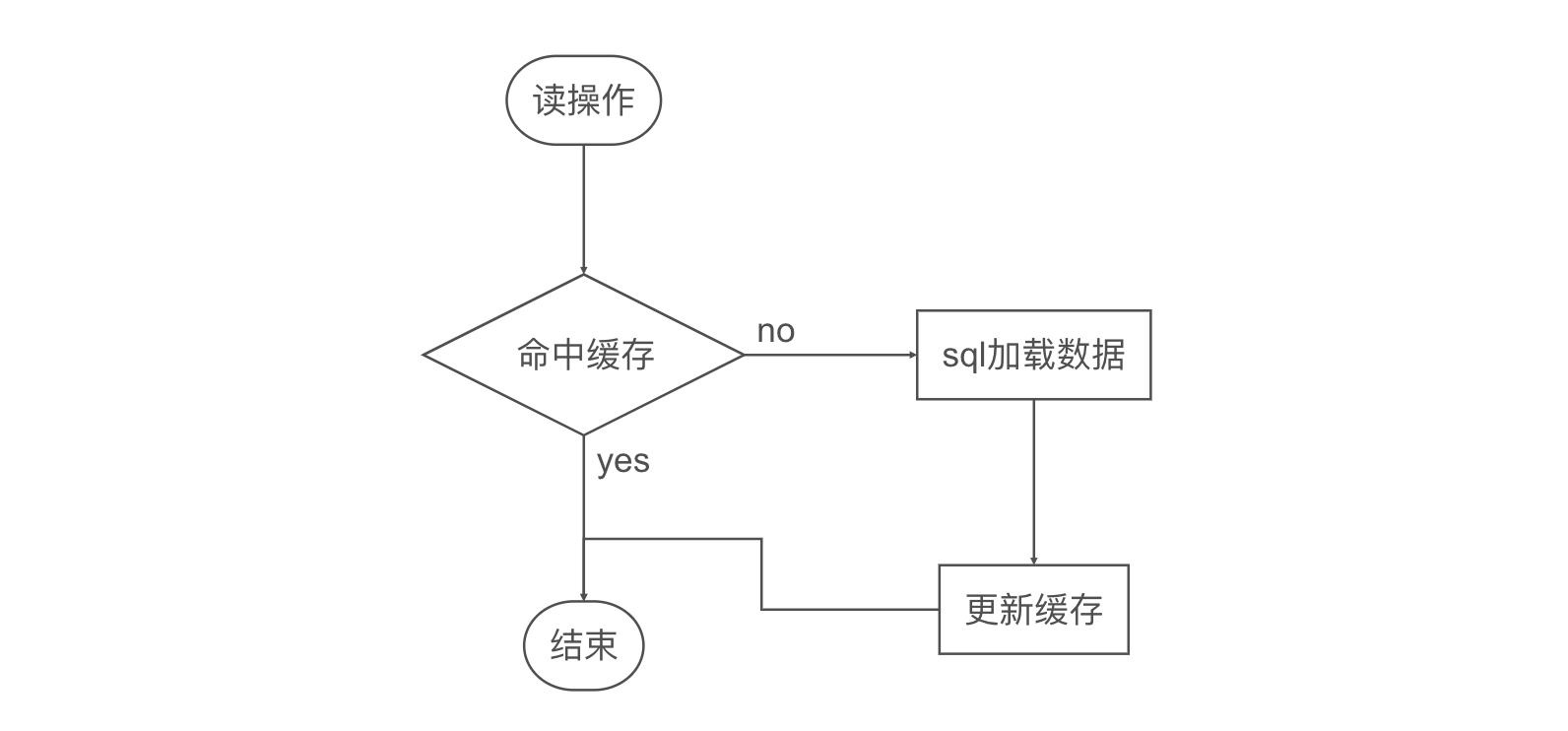
在Redis缓存中经常会遇到数据一致性问题。对于一个缓存,下面罗列几种情况:
读
read:从Redis中读取,如果Redis中没有,那么就从MySQL中获取更新Redis缓存。
下面流程图描述常规场景,没啥争议:
写1:先更新数据库,再更新缓存(普通低并发)
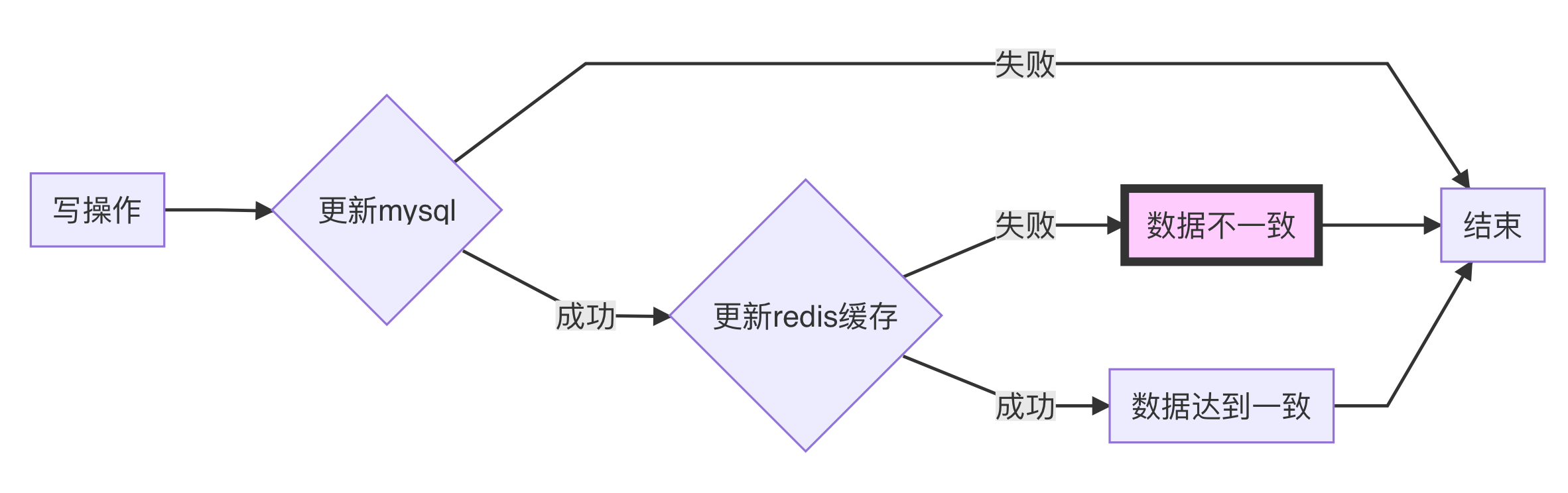
更新数据库信息,再更新Redis缓存。这是常规做法,缓存基于数据库,取自数据库。
但是其中可能遇到一些问题,例如上述如果更新缓存失败(宕机等其他状况),将会使得数据库和Redis数据不一致。造成DB新数据,缓存旧数据。
写2:先删除缓存,再写入数据库(低并发优化)
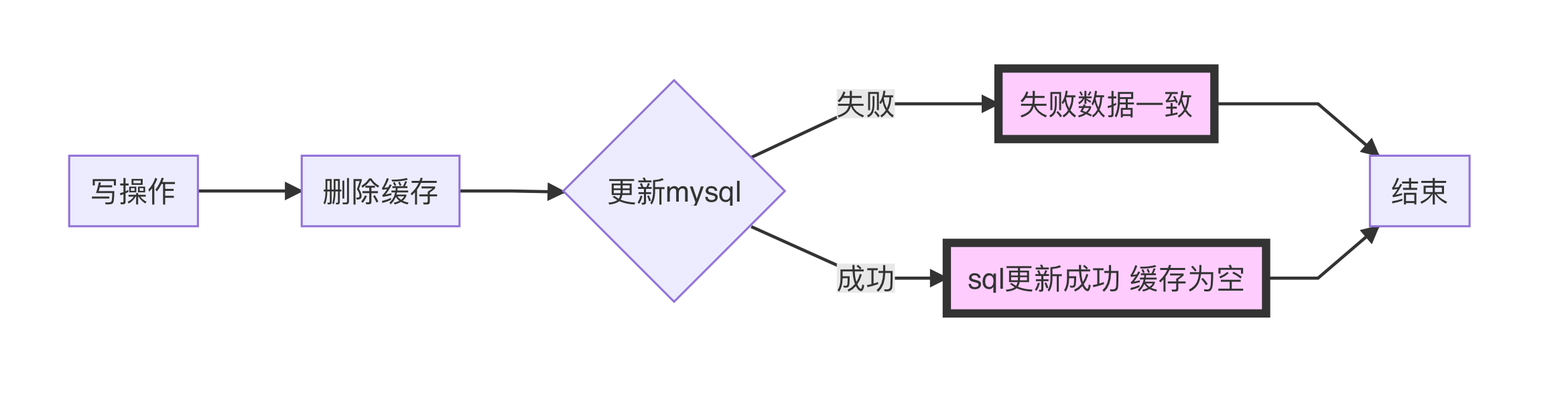
解决的问题
这种情况能够有效避免写1中防止写入Redis失败的问题。将缓存删除进行更新。理想是让下次访问Redis为空去MySQL取得最新值到缓存中。但是这种情况仅限于低并发的场景中而不适用高并发场景。
存在的问题
写2虽然能够看似写入Redis异常的问题。看似较为好的解决方案但是在高并发的方案中其实还是有问题的。我们在写1讨论过如果更新库成功,缓存更新失败会导致脏数据。我们理想是删除缓存让下一个线程访问适合更新缓存。问题是:如果这下一个线程来的太早、太巧了呢?
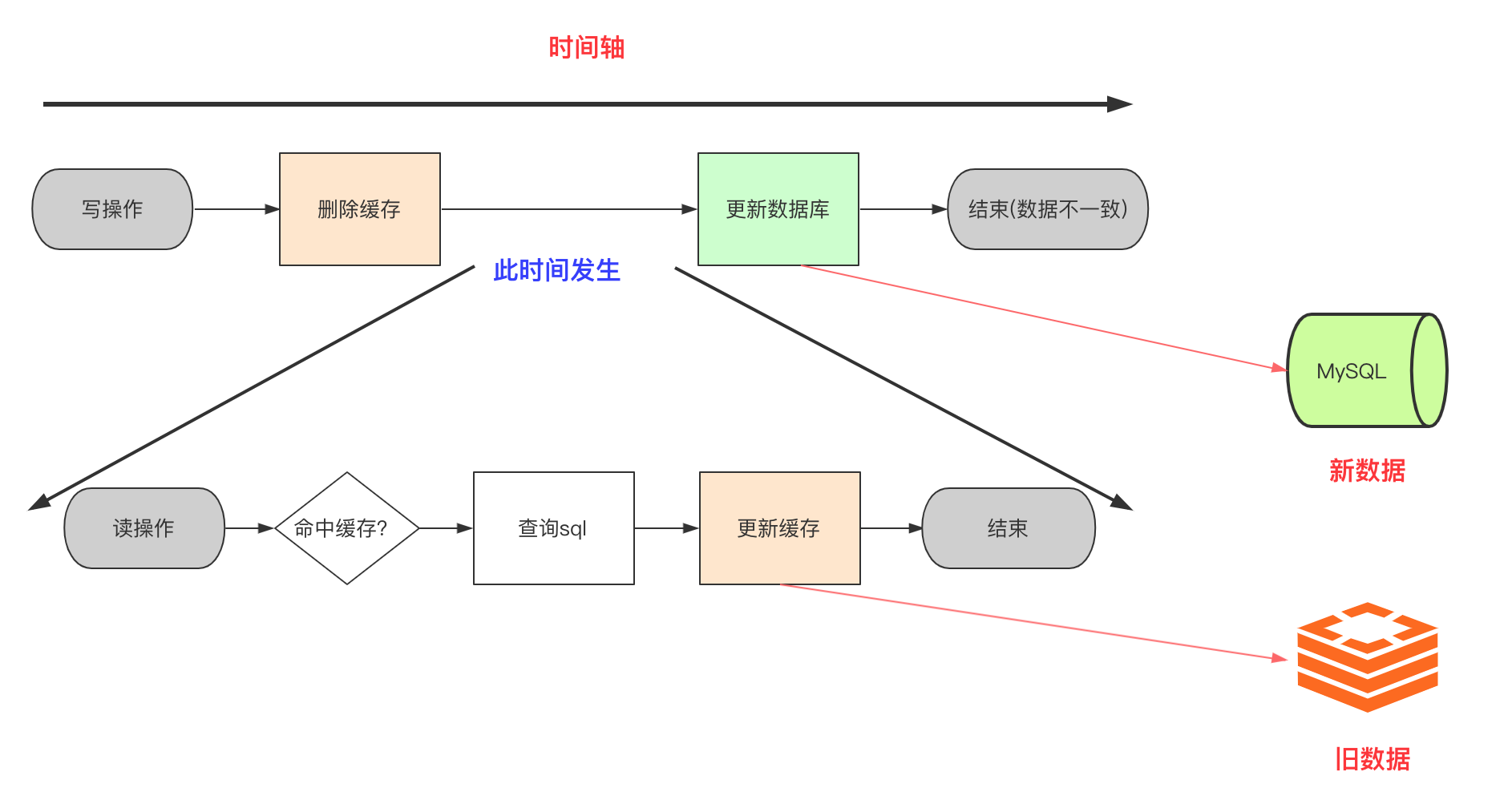
因为多线程你也不知道谁先谁后,谁快谁慢。如上图所示情况,将会出现Redis缓存数据和MySQL不一致。当然你可以对key进行上锁。但是锁这种重量级的东西对并发功能影响太大,能不用锁就别用!上述情况就高并发下依然会造成缓存是旧数据,DB是新数据。并且如果缓存没有过期这个问题会一直存在。
写3:延时双删策略
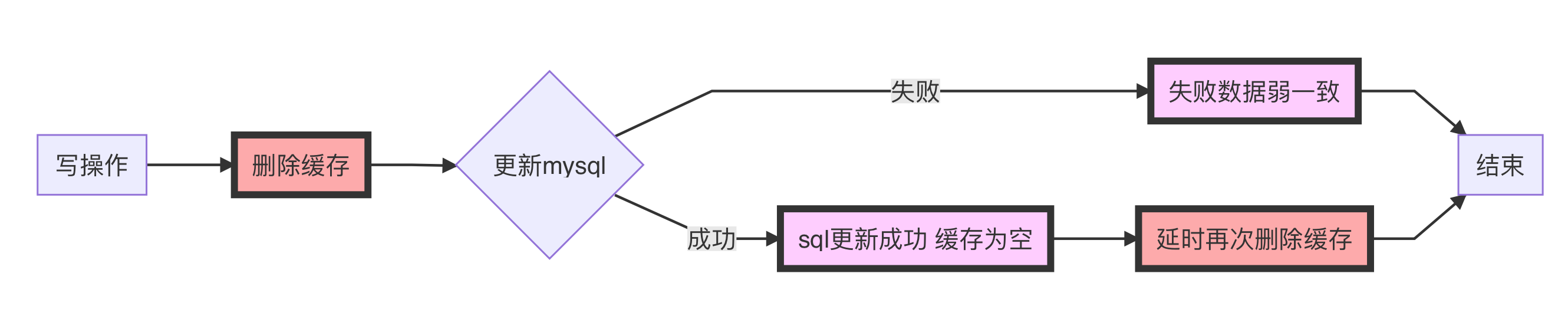
这个就是延时双删策略,能过缓解在写2中在更新MySQL过程中有读的线程进入造成Redis缓存与MySQL数据不一致。方法就是删除缓存->更新缓存->延时(几百ms)(可异步)再次删除缓存。即使在更新缓存途中发生写2的问题。造成数据不一致,但是延时(具体实间根据业务来,一般几百ms)再次删除也能很快的解决不一致。
但是就写的方案其实还是有漏洞的,比如第二次删除错误、多写多读高并发情况下对MySQL访问的压力等等。当然你可以选择用MQ等消息队列异步解决。其实实际的解决很难顾及到万无一失,所以不少大佬在设计这一环节可能会因为一些纰漏会被喷。作为菜菜的笔者在这里就更不献丑了,各位大佬欢迎贡献你们的方案。
写4:直接操作缓存,定期写入sql(适合高并发)
当有一堆并发(写)扔过来的后,前面几个方案即使使用消息队列异步通信但也很难给用户一个舒适的体验。并且对大规模操作sql对系统也会造成不小的压力。所以还有一种方案就是直接操作缓存,将缓存定期写入sql。因为Redis这种非关系数据库又基于内存操作KV相比传统关系型要快很多。
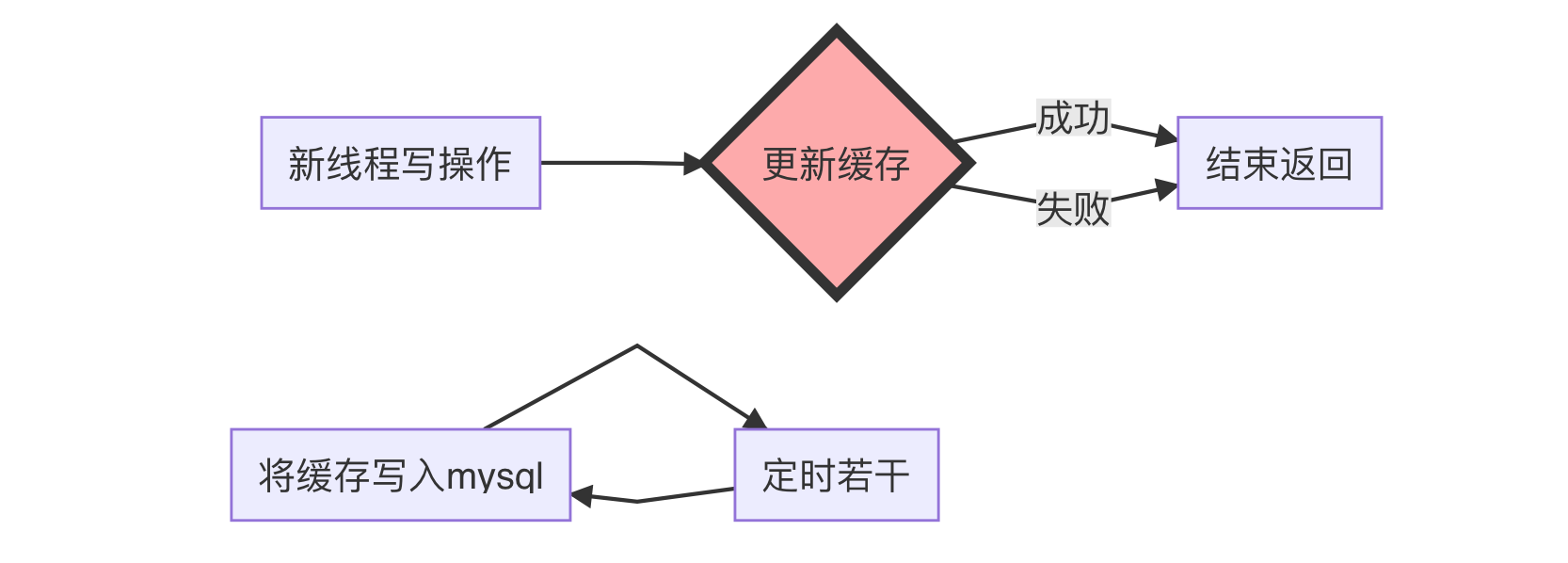
上面适用于高并发情况下业务设计,这个时候以Redis数据为主,MySQL数据为辅助。定期插入(好像数据备份库一样)。当然,这种高并发往往会因为业务对读、写的顺序等等可能有不同要求,可能还要借助消息队列以及锁完成针对业务上对数据和顺序可能会因为高并发、多线程带来的不确定性和不稳定性,提高业务可靠性。
总之,越是高并发、越是对数据一致性要求高的方案在数据一致性的设计方案需要考虑和顾及的越复杂、越多。上述也是笔者针对Redis数据一致性问题的学习和自我发散(胡扯)学习。如果有解释理解不合理或者还请各位大佬指正!
最后,感觉不错的话还请一键三连,欢迎关注原创公众号:「bigsai」,在这里,不仅能学到知识和干货,还给你准备了很多进阶资料,在成长之路与你为友!,回复「bigsai」口令即可领取!

文章来源: bigsai.blog.csdn.net,作者:Big sai,版权归原作者所有,如需转载,请联系作者。
原文链接:bigsai.blog.csdn.net/article/details/109587386

- 点赞
- 收藏
- 关注作者
评论(0)