Efficient Video Object Segmentation via Network Modulation 翻译

通过网络调制实现高效的视频对象分割

项目地址:https://github.com/linjieyangsc/video_seg
摘要
当仅给出带注释的第一帧时,视频对象分割目标在整个视频序列中对特定对象进行分段。
最近基于深度学习的方法发现使用数百次梯度下降迭代来微调注释帧上的通用分割模型是有效的。
尽管这些方法实现了高精度,但微调过程效率低下并且不能满足现实世界应用的要求。
我们提出了一种新方法,该方法使用单个前向传递来使分割模型适应特定对象的外观。
具体地,在给定目标对象的有限视觉和空间信息的情况下,训练称为调制器的第二元神经网络以操纵分割网络的中间层。
实验表明,我们的方法比微调方法快70倍,并达到类似的准确度。
我们的模型和代码已在https://github.com/linjieyangsc/video_seg上发布。
介绍
语义分割在理解图像的视觉内容中起重要作用,因为它为每个像素分配预定义的对象或场景标签,从而将图像转换为分割图。
在处理视频内容时,人们可以在不知道其语义含义的情况下轻松地分割整个视频中的对象,这激发了一个名为半监督视频分割的研究课题。
在半监督视频分割的典型场景中,给出一个视频的第一帧以及带注释的对象掩模,并且任务是在所有后续帧中准确地定位对象。
以最小监督(例如,一个注释帧)执行精确像素级视频分割的能力可导致大量应用,诸如用于视频理解的精确对象跟踪,交互式视频编辑,增强现实和基于视频的广告。
当监督仅限于一个带注释的框架时,研究人员将这种情况称为一次性学习。
近年来,我们目睹了对开发视频分割的一次性学习技术的兴趣不断增加。
大多数这些作品都有一个类似的两阶段范式:首先,训练一个通用的全卷积网络(FCN)来分割前景物体;第二,基于视频的第一帧微调该网络,进行数百次前后迭代,以使模型适应特定的视频序列。
尽管这些方法实现了高精度,但微调过程可能耗费时间,这阻碍了实时应用。
这些方法中的一些论文也利用光流信息,这对于最先进的算法来说计算量很大。
为了降低半监督分割的计算成本,我们提出了一种新方法,使通用分割网络适应单个前馈传递中特定对象实例的出现。
我们建议采用另一种称为调制器的元神经网络来学习在给定任意目标对象实例的情况下调整通用分段网络的中间层。
图1显示了我们的方法。
通过从注释对象的图像和对象的空间先验提取信息,调制器产生参数列表,其被注入到分段模型中以用于逐层特征操纵。
如果没有一次性微调,我们的模型能够使用来自目标对象的最少提取信息来改变分割网络的行为。
我们将此过程称为网络调制。
图1 方法概述
我们的模型由调制器和分段网络组成。 调制器可以立即调整分割模型以通过视频序列分割任意对象。
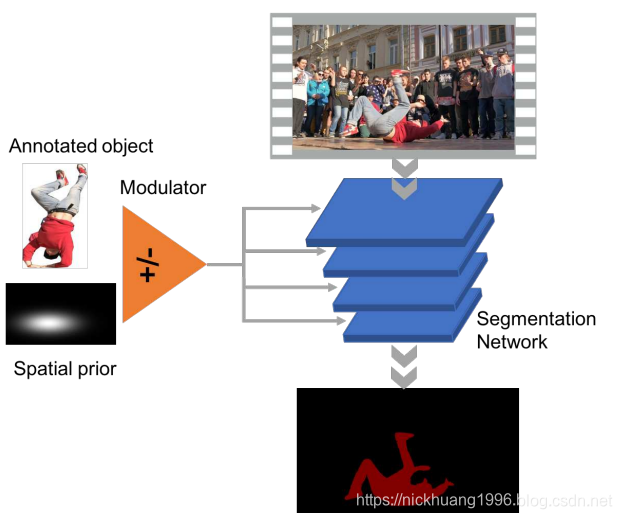
我们提出的模型是有效的,仅需要来自调制器的一个前向通道来产生分割模型所需的所有参数以适应特定的对象实例。
由空间先验引导的网络调制有助于模型即使存在多个类似实例也能跟踪对象。
整个管道是可区分的,可以使用标准随机梯度下降进行端到端学习。
实验表明,我们的方法在没有大幅度微调的情况下优于以前的方法,并且在70倍加速的单次微调之后实现了与这些方法相当的性能。
相关工作
半监督视频分割
半监督视频对象分割旨在在整个视频的其余部分中从第一个带注释的帧跟踪对象掩模。
在最近的文献中已经提出了许多方法,包括传播超像素,补丁,对象建议或双边空间,并且通常执行基于图形模型的优化以考虑多个同时框架。
随着FCN在静态图像分割上的成功,最近提出了基于深度学习的方法用于视频分割,并且已经实现了有希望的结果。
为了模拟时间运动信息,一些工作严重依赖于光流,并使用CNN来学习物体从当前帧到下一帧的掩模细化,或者将CNN的训练与双边训练结合起来相邻帧之间的过滤。
陈等人使用CNN来联合估计光流并提供学习的运动表示以产生跨时间的运动一致分段。
与这些方法不同,Caelles等人结合静态图像的离线和在线训练过程,不使用时间信息。
虽然它节省了以前某些方法中涉及的光流和/或条件随机场(CRF)的计算,但在线微调仍需要多次迭代优化,这对需要快速推理的实际应用提出了挑战。
用于低射击(low-shot)学习的元学习
当前深度学习的成功依赖于通过梯度下降优化来学习大规模标记数据集的能力。
但是,如果我们的目标是学习适应许多环境的许多任务,那么模型从头开始学习每个设置的每个任务并不是最佳的。
相反,我们希望我们的深度学习系统能够非常快速地从非常有限的数据量学习新任务。
在“一次性学习”的极端情况下,算法需要通过单次观察来学习新任务。
学习多功能模型的一个潜在策略是元学习或学习学习的概念,其可以追溯到20世纪80年代后期。
最近,元学习已经成为一个热门的研究课题,出版了神经网络优化,发现了良好的网络架构,快速强化学习和少数镜头图像识别。
Ravi和Larochelle 提出了一个LSTM元学习器来学习几个镜头学习的更新规则。
还有论文中针对大量任务的元优化目标是学习能够通过有限数量的更新快速适应新任务的模型。
Hariharan和Girschick训练了一个学习者,他们生成了新的样本,并使用新的样本来训练新的任务。
我们的方法类似于元学习,因为它学习用另一个元学习器即调制器快速更新分割模型。
网络操纵
以前的几个工作试图结合模块来操纵深度神经网络的行为,或者操纵数据的空间排列或过滤器权重的连接。
我们的方法也受到条件批量归一化的强烈推动,其中深度模型的行为由基于指导输入的批量归一化参数操纵,例如, 用于图像样式化的样式图像或用于视觉问题回答的语言句子。
网络调制的视频对象分割
在我们提出的框架中,我们利用调制器立即使分割网络适应特定对象,而不是执行数百次梯度下降迭代。
与在一次性学习方法中更新整个网络相比,我们可以通过调整分割网络中有限数量的参数来实现类似的准确性。
视频对象分割有两个重要提示:视觉外观和空间连续运动。
为了使用来自视觉和空间域的信息,我们结合了两个网络调制器,即视觉调制器和空间调制器,以学习分别基于注释的第一帧和对象的空间位置来调整主分段网络中的中间层。
条件批量标准化
我们的方法受到最近使用条件批量归一化(CBN)的工作的启发,其中每个批量归一化层的规模和偏差参数由第二控制器网络产生。
这些参数用于控制主网络的行为,以执行图像样式化和问题回答等任务。
在数学上,每个CBN层可以如下配制:
![]()
其中xc和yc是第c个通道中的输入和输出特征映射,γc和βc分别是控制器网络产生的缩放和偏置参数。
为清楚起见,省略了均值和方差参数。
视觉和空间调制
CBN层是特征图上更一般的缩放和移位操作的特殊情况。
在每个卷积层之后,我们定义一个新的调制层,其中包含由联合训练的视觉和空间调制器生成的参数。
我们设计了两个调制器,使得视觉调制器产生通道方向尺度参数以调整特征图中不同通道的权重,而空间调制器产生元素方向偏置参数以在调制特征之前注入空间。
具体来说,我们的调制层可以表述如下:
![]()
其中γc和βc分别是来自视觉和空间调制器的调制参数。
γc是用于通道加权的标量,而βc是应用逐点偏差值的二维矩阵。
图2示出了所提出的方法的图示,其由三个网络组成:完全卷积主分割网络,视觉调制器网络和空间调制器网络。
视觉调制器网络是CNN,其将带注释的视觉对象图像作为输入并且为所有调制层产生尺度参数的矢量,而空间调制器网络是基于空间先前输入产生偏置参数的非常有效的网络。
图2
我们的模型有三个组件的例证:分段网络,视觉调制器和空间调制器。 这两个调制器产生一组参数,这些参数操纵分段网络的中间特征图并使其适应于分割特定对象。
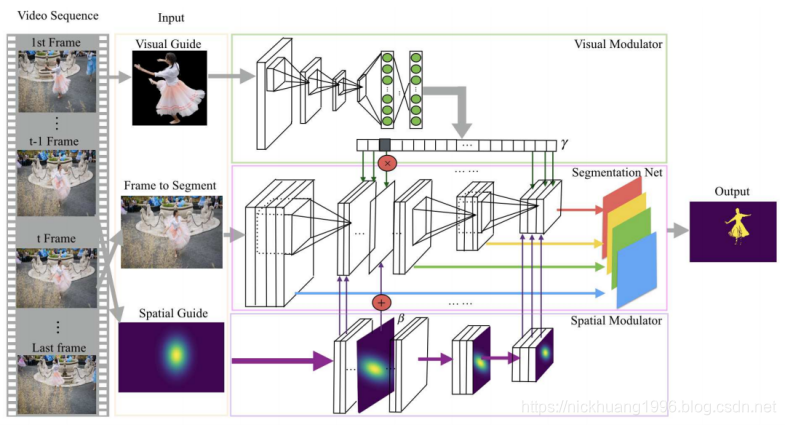
视觉调制器
视觉调制器用于使分割网络适应于关注特定对象实例,该特定对象实例是第一帧中的注释对象。
为方便起见,以下将注释对象称为视觉引导。
视觉调制器从视觉引导中提取诸如类别,颜色,形状和纹理的语义信息,并生成相应的频道方向权重,以便重新定位分割网络以分割对象。
我们使用VGG16 神经网络作为视觉调制器的模型。
我们修改其针对ImageNet分类训练的最后一层,以匹配分段网络的调制层中的参数数量。
视觉调制器隐含地学习不同类型对象的嵌入。
它应该产生类似的参数来调整类似对象的分割网络和不同对象的不同参数。
使用这种视觉调制器的一个显着优点是我们可以潜在地转移利用大量对象类(例如ImageNet)学习的知识,以便学习良好的嵌入。
空间调制器
我们的空间调制器将图像中对象的先前位置作为输入。
由于对象在视频中连续移动,我们将先前设置为前一帧中对象掩码的预测位置。
具体而言,我们将位置信息编码为在图像平面上具有二维高斯分布的热图。
高斯分布的中心和标准偏差是根据前一帧的预测掩模计算的。 为方便起见,此热图在下文中称为空间指南。
空间调制器将空间指南下采样到不同的比例,以匹配分割网络中的不同特征图的分辨率,然后对每个下采样的热图应用缩放和移位操作以生成相应调制层的偏置参数。
在数学上,
![]()
其中m是对应调制层的下采样高斯热图,γ~c和β~c分别是第c通道的标度 - 移位参数。
这是通过计算效率高的1×1卷积实现的。
在图2的底部,我们说明了空间调制器的结构。
实施细节
我们的FCN结构具有超柱结构的VGG16 模型。
直观地说,我们应该在FCN中的每个卷积层之后添加调制层。
然而,我们发现在早期卷积层之间添加调制层实际上会恶化模型的性能。
一个可能的原因是早期层提取的低级特征对调制器引入的缩放和移位操作非常敏感。
在我们的实现中,我们将调制操作添加到VGG16中的所有卷积层,除了前四层,这导致九个调制层。
与MaskTrack 类似,我们也利用静态图像训练我们的模型。
理想情况下,视觉调制器应该学习从任何对象到FCN中不同层的调制权重的映射,这要求模型查看所有可能的不同对象。
但是,大多数视频语义分段数据集仅包含非常有限数量的类别。
我们通过使用最大的公共语义分割数据集MSCOCO 来解决这一挑战,该数据集有80个对象类别。
我们选择大于图像大小3%的对象进行训练,结果总数为217,516个对象。
对于预处理视觉调制器的输入,我们首先使用带注释的蒙版裁剪对象,然后将背景像素设置为平均图像值,然后将裁剪的图像调整为224×224的恒定分辨率。
对象也增加了高达10%随机缩放和10°随机旋转。
为了预处理空间指南作为空间调制器的输入,我们首先计算掩模的平均值和标准偏差,然后使用高达20%随机移位和40%随机缩放来增加掩模。
对于送入FCN的整个图像,我们使用320,400和480的随机大小,方形。
视觉调制器和分割网络都使用在ImageNet 分类任务上预训练的VGG16模型进行初始化。
通过将视觉调制器的最后一个全连接层的权重和偏差分别设置为0和1,将调制参数{γc}初始化为1。
空间调制器的权重随机初始化。
我们使用平衡交叉熵损失。
使用小批量(mini-batch)8。
对于β1和β2,我们分别使用默认动量为0.9和0.999的Adam优化器。
该模型首先训练10个epoch,学习率为10^-5,然后训练另外5个epoch,学习率为10^-6。
此外,为了模拟视频中移动物体的外观变化,可以在视频分割数据集(如DAVIS 2017 )上对模型进行微调。
为了更加强大的外观变化,我们从整个视频序列中随机选取一个前景对象作为每个帧的视觉指南。
空间指南是从前一帧中对象的Ground Truth掩模获得的。
相同的数据增强作为MSCOCO上的训练应用。
该模型经过20个时期的微调,学习率为10^-6。
实验
在本节中,我们将介绍实验的三个部分:我们的方法与先前方法的比较,调制参数的可视化和消融研究。
我们的模型在几个流行的视频分割数据集上进行了测试,包括DAVIS 和YoutubeObjects。
DAVIS 2016 & YoutubeObjects
我们的方法与DAVIS 2016和YoutubeObjects的最新方法的性能比较。 以平均IU测量的性能。
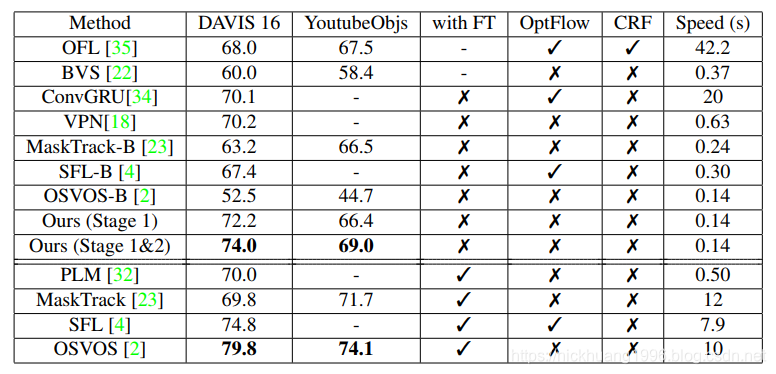
在我们的方法中,视觉调制器的一个前向传递允许分割模型适应,这比在目标视频上进行模型微调的现有方法更有效。
视觉调制器仅需要针对整个视频计算一次。
同时,需要针对每个帧计算空间调制器,但是开销可以忽略不计,即,我们的模型在视频序列上的平均速度与FCN本身大致相同。
我们的方法是所有比较方法中第二快的,只有MaskTrack-B和OSVOS-B达到相似的速度但精度较低。
DAVIS 2017
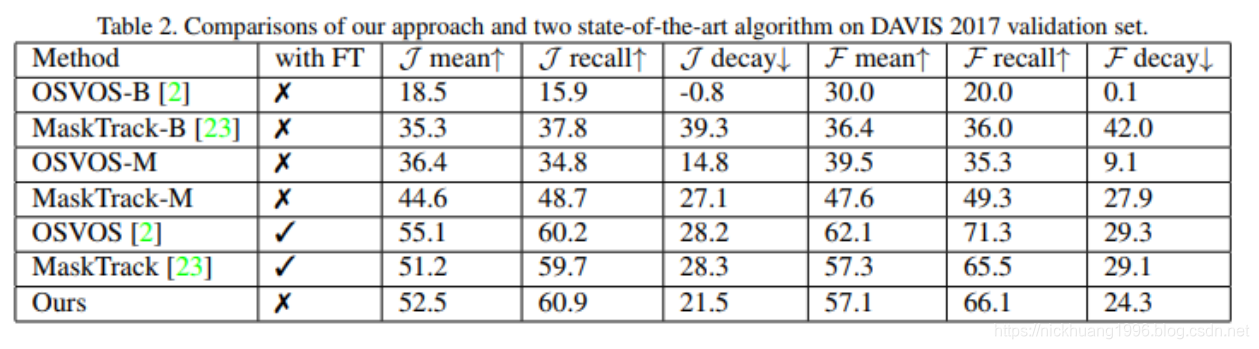
表2显示了DAVIS 2017上不同方法的结果。
我们利用DAVIS数据集的官方评估指标:区域相似度J和轮廓精度F的均值,反馈和衰减。
注意J mean等于我们上面使用的平均IU。
同样,我们的模型大大优于OSVOS-B和MaskTrack-B,同时通过模型微调获得与两种方法相当的性能。
OSVOS-M和MaskTrack-M均优于其基线实现,J均值分别增加18%和9.3%。
由于分割模型的权重是固定的,因此精度增益仅来自调制器,这证明视觉调制器能够通过操纵中间特征图的比例来改善不同的模型结构。
我们的方法与前两种方法相比的一些定性结果如图3所示。
与MaskTrack相比,我们的方法通常获得更准确的边界,部分原因是粗糙空间先验迫使模型在图像上探索更多线索。
与OSVOS相比,由于空间调制器提供的跟踪功能,当图像中存在多个相似物体时,我们的方法显示出更好的结果。
另一方面,我们的方法也显示出对训练数据中看不见的对象类别有效。
在图3中,骆驼和猪是MS-COCO数据集中看不见的对象类别。
图3
我们的方法的一些定性结果与最近两个关于DAVIS 2017的最新方法相比较。
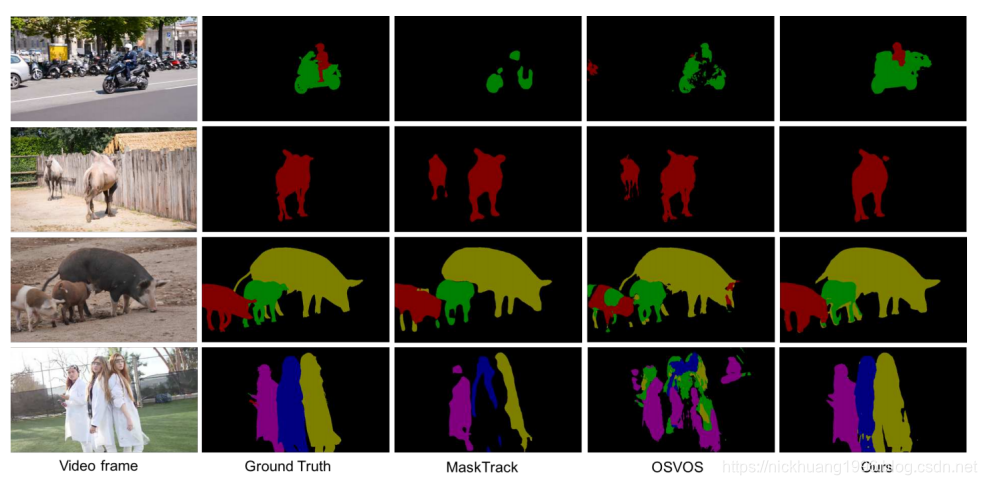
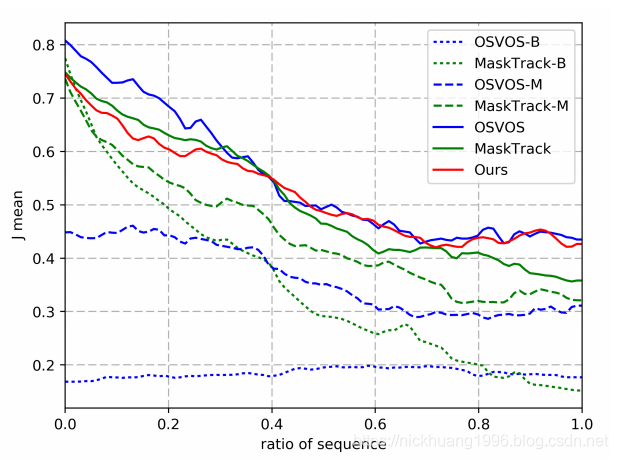
图4
J表示不同方法在DAVIS 2017上的表现。我们的是红色的。
可视化调制参数
我们的模型隐含地学习了来自视觉调制器的调制参数的嵌入用于注释对象。
直观地说,类似的对象应该具有相似的调制参数,而不同的对象应该具有显着不同的调制参数。
为了可视化这种嵌入,我们从MS-COCO中的10个对象类中的100个对象实例中提取调制参数,并使用图5中的多维缩放在二维嵌入空间中可视化参数。
我们可以看到同一类别主要聚集在一起,类似的类别比不同的类别更接近。
图5
从10个类别的100个对象的学习调制参数的可视化:自行车,摩托车,汽车,公共汽车,卡车,狗,猫,马,牛,人。 放大以查看详细信息。
例如,猫和狗,汽车和公共汽车由于其相似的外观而混合在一起,而自行车和狗,公共汽车和马匹由于视觉差异很大而彼此远离。
哺乳动物类(猫,狗,牛,马,人)通常聚集在一起,人造物体(汽车,公共汽车,自行车,摩托车,卡车)聚集在一起。

不同层中调制参数
我们还研究了不同层中调制参数的大小。 调制参数{γc}根据视觉指南而改变。
因此,我们计算MS-COCO验证集中图像的每个调制层中调制参数{γc}的标准偏差,并在图6中进行说明。
图6
在不同调制层中来自视觉调制器的γc的标准偏差的直方图。 带注释的名称是VGG16中相应的卷积层。
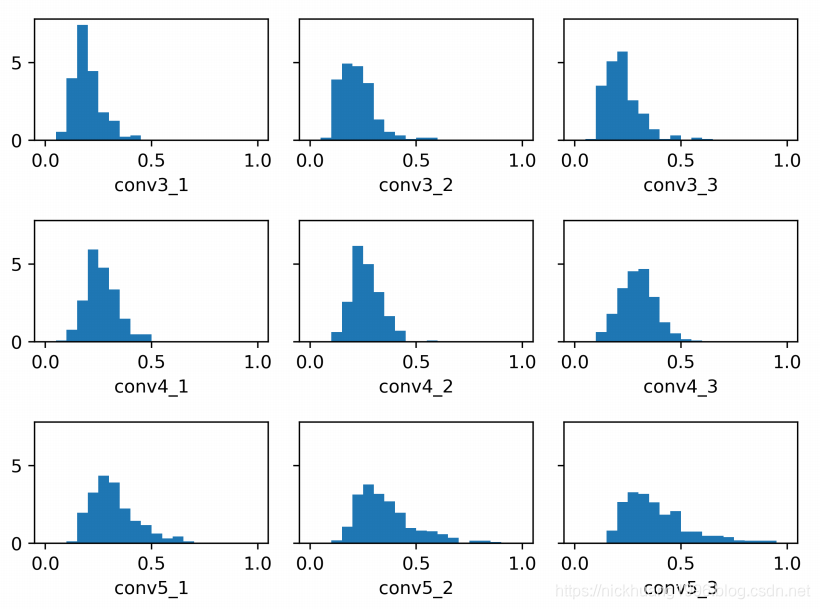
一个有趣的观察结果是,对于网络的更深层次,调制参数的变化变得更大。
这表明,在最后几层中,特征地图的操纵比在网络的早期层中更为显着。
深层神经网络的最后几层通常学习高级语义含义,可用于更有效地将分割模型调整到特定对象。
我们还通过在空间调制器的每一层中提取尺度参数{γ~c}来研究空间调制器,并在图7中将它们可视化。
{γ〜c}的大小是空间指南的相对尺度。 FCN中的功能图。
{γ〜c}的比例与空间先验对中间特征图的影响成比例。
有趣的是,我们观察到{γ〜c}值的稀疏性。
除最后一个卷积层conv5-3外,大约60%的参数具有零值,这意味着只有40%的特征图受这些层中的空间先验影响。
图7
来自不同调制层中的空间调制器的γ~c的幅度的直方图。 带注释的名称是VGG16中相应的卷积层。
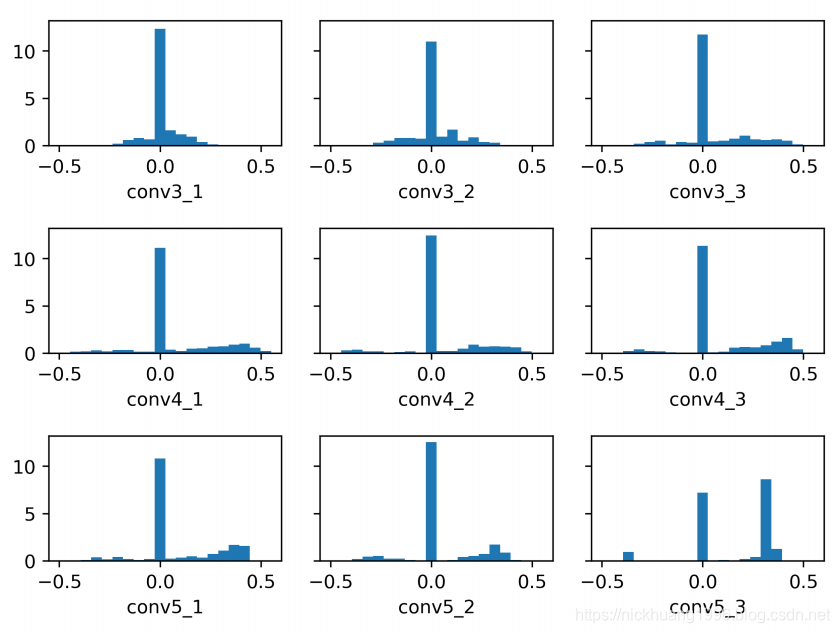
在conv5-3中,大约70%的特征图与空间指南相互作用,并且大多数特征图与空间指南的相似比例(注意峰值约为0.4)相加。
这表明空间先验被逐渐融合到特征图中,而不是在网络的开始时有效。
在完成所有特征提取之后,空间调制器对特征图进行大的调整,这提供了目标对象的位置的强大先验。
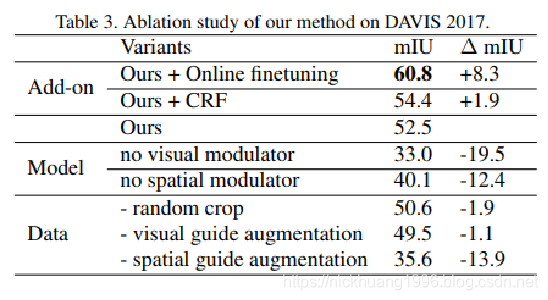
消融研究
我们研究了不同成分对我们方法的影响。
我们在2017年DAVIS上进行实验,并使用平均IU测量性能。
对于模型结构的变体,我们仅使用空间或视觉调制器进行实验。
对于数据增强方法,我们没有对FCN输入进行随机作物增强,也没有对视觉指南和空间指南进行仿射变换。
我们尝试使用CRF作为后处理步骤。
为了研究单次微调对我们模型的影响,我们还尝试使用少量迭代进行标准的单次微调。
结果显示在表3中。
结论
在这项工作中,我们提出了一个新的框架来有效地处理一次性视频分割。
为了减轻先前基于FCN的方法开发的单次微调的慢速,我们建议使用网络调制方法,通过调制器网络的一次正向来模拟微调过程。
我们在实验中表明,通过注入由调制器计算的有限数量的参数,可以重新利用分割模型来分割任意对象。
所提出的网络调制方法是用于少数学习问题的通用学习方法,其可以应用于诸如视觉跟踪和图像风格化的其他任务。
我们的方法属于元学习的一般范畴,同样值得研究视频分割的其他元学习方法。
未来的另一项工作是学习调制参数的循环表示以基于时间信息操纵FCN。
文章来源: nickhuang1996.blog.csdn.net,作者:悲恋花丶无心之人,版权归原作者所有,如需转载,请联系作者。
原文链接:nickhuang1996.blog.csdn.net/article/details/88219578

- 点赞
- 收藏
- 关注作者
评论(0)