Python法律实务——利用批量裁判文书内容制作行业白皮书(也可用于诉讼可视化实践)

前面的文章介绍了裁判文书中数据信息的提取,裁判文书目前作为学术研究、案件指引最重要的大数据源,受到了越来越多的重视。在实际工作中,许多律所或者律师,出于学术研究、业务宣传、品牌宣传等目的,会在自己的公号或者私有媒体对一些行业案件进行归纳整理分析。根据这些数据的指引,我们不仅能了解到学习法律知识,同样可以参照来作为案件的办理指引。
接下来,笔者就以帮助专做劳动法的同事陈律师制作某个行业白皮书(餐饮行业的劳动法领域)的过程为例,来做深入的介绍。
- 实践难度 :高
- 知识点涉及:正则表达式、python-docx库处理docx文档、pandas库处理excel文档、文件夹的遍历、Pyecharts制作图表
- 面向对象:掌握了Python初、中级别知识,熟悉了Python上述几个模块的基本使用方法的读者。
第一步 数据准备
由于绝大部分读者,不具备自建裁判文书数据库的能力,所以需要提前到裁判文书、或者类似网站进行检索,将检索到的裁判文书进行批量下载。
笔者当然是有自己的数据库的,但是为了演示,这里下载了2019年100多份相关的裁判文书。
第二步 设计编程思路
- 设计正则表达式,从文书中提取仲裁的请求
- 遍历所有docx文档,再利用python-docx库遍历文档中的每一段进行正则匹配
- 将匹配结果导出excel表格中
- 处理和分析excel表格
- 将excel表格数据转化为可视化图表
第三步 编程与调试
pattern=".*?申请仲裁.{1,5}[请要]求"
_re =re.compile(pattern,re.M|re.S|re.I)
result=[]
unmatched=[]
files=[]
for parent, dirnames, filenames in os.walk(r'餐饮大数据分析', followlinks=True):
for filename in filenames:
file_path = os.path.join(parent, filename)
if '.docx' in file_path:
_i={'fileName':filename,'filePath':file_path}
files.append(_i)
print(files)
print('files length:',len(files))
- 正则表达式
为了提取到我们的目标段落,我们先要找一个样本出来:

我们需要从判决书中找出双方的仲裁请求的那一段,并提取出来,通过这一段样本,我初步的正则表示为:
pattern=".*?申请仲裁.{1,5}[请要]求"
接下来我们要找出所有的docx文件,这个很简单,之前的文章已经介绍过文件夹的遍历:
files=[]
for parent, dirnames, filenames in os.walk(r'餐饮大数据分析', followlinks=True):
for filename in filenames:
file_path = os.path.join(parent, filename)
if '.docx' in file_path:
_i={'fileName':filename,'filePath':file_path}
files.append(_i)
print(files)
print('files length:',len(files))
-------------------------------------
[{'fileName': '10-上海广增餐饮管理有限公司与雷楠劳动合同纠纷一审民事判决书.docx', 'filePath': '餐饮大数据分析\\20200523004507\\10-上海广增餐饮管理有限公司与雷楠劳动合同纠纷一审民事判决书.docx'}, {'fileName': '11-宏葡(上海)餐饮有限公司与颜丹丹劳动合同纠纷一审民事判决书.docx', 'filePath': '餐饮大数据分析\\20200523004507\\11-宏葡(上海)餐饮有限公司与颜丹丹劳动合同纠纷一审民事判决书.docx'} …………]
files length: 117
接下来,我们需要遍历每一个word文件,并将word文档按照段落进行匹配:
pattern=".*?申请仲裁.{1,5}[请要]求"
_re =re.compile(pattern,re.M|re.S|re.I)
result=[]
unmatched=[]
files=[]
for parent, dirnames, filenames in os.walk(r'餐饮大数据分析', followlinks=True): # dirnames 子文件夹
for filename in filenames:
file_path = os.path.join(parent, filename)
if '.docx' in file_path:
_i={'fileName':filename,'filePath':file_path}
files.append(_i)
for i in files:
document = Document(i['filePath'])
sig=0
for paragraph in document.paragraphs:
res=_re.search(paragraph.text)
if res is not None:
_o={'fileName':i['fileName'],'filePath':i['filePath'],'paragraph':paragraph.text}
result.append(_o)
sig=1
break #匹配一次后,后面的段落就不再匹配
if sig==0:
_o = {'fileName': i['fileName'], 'filePath': i['filePath']}
unmatched.append(_o)
print('result:',result)
print('result length:',len(result))
print('unmatched:',unmatched)
print('unmatched length:',len(unmatched))
----------------------------------------
result: [{'fileName': '11-宏葡(上海)餐饮有限公司与颜丹丹劳动合同纠纷一审民事判决书.docx',…………]
result length: 61
unmatched: [{'fileName': '10-上海广增餐饮管理有限公司与雷楠劳动合同纠纷一审民事判决书.docx', ……]
unmatched length: 56
- _re =re.compile(pattern,re.M|re.S|re.I)
由于同一个正则表达式要多次重复使用,为了提升匹配效率,可以使用re.compile()来编译正则表达式,生成一个正则表达式对象,从而提升效率。 - document = Document(i['filePath'])
先实例化一个docx对象 - for paragraph in document.paragraphs
依次遍历这个docx对象中所有的段落
我们将匹配到的结果放入到result这个别表中,没匹配到的放到unmatched中,上面的结果可以看到result的长度只有61个,说明只匹配到了61个文档,显然这个正则表达式,匹配成功率不高。
为了作进一步处理,以及复查数据,我们将结果存储为excel表格:
data={'段落':[],'文件名称':[],'文件相对路径':[]}
unmatched_data={'文件名称':[],'文件相对路径':[]}
for p in result:
data['段落'].append(p['paragraph'])
data['文件名称'].append(p['fileName'])
data['文件相对路径'].append(p['filePath'])
for q in unmatched:
unmatched_data['文件名称'].append(q['fileName'])
unmatched_data['文件相对路径'].append(q['filePath'])
df = pd.DataFrame(data)
df.to_csv('result.csv', index=True,encoding="utf_8_sig")
df = pd.DataFrame(unmatched_data)
df.to_csv('noresult.csv', index=True,encoding="utf_8_sig")
通过上述代码,我们就将匹配到的结果列表result和未匹配到的结果列表unmatched,保存为名为"result.csv"和"noresult.csv"的两个表格。当然也可以将这两个数据合并到一个excel表格里。通过没匹配到的列表中的word文档查看,进一步修改了正则表达式:
pattern=".*?(?:申请|提起).*?(?:仲裁|申诉)"
以这种方式匹配出来104个,还有13个没有匹配到,这个时候,再去完善正则意义似乎不太大,毕竟只剩13个,人工匹配一下段落也很快。
result.csv表格内容截图:

到这一步,我们已经把所有的文书,都提取了我们想要的段落,并进行了保存。
我们下一步,需要提取段落中的争议重点,这一步并非不是不能通过Python处理,只是难度和前期时间成本非常大,这里我建议暂时通过人工的方式处理。在精选的字段中提取关键信息,由于已经给人工处理排除掉了许多无关信息,时间成本尚可接受。
笔者在上述表格的E列增加一个字段“案件焦点”,当然增加到其他列也可以,然后陈律师让助理在该列依次填入了归纳的焦点。
第四步 数据可视化展现
这里数据可视化,一样要用到pandas库来处理csv文件,同时也会利用到pyecharts模块,
读取csv文件,做先行处理:
import pandas
df=pd.read_csv('result.csv')
result={}
for index, row in df.iterrows():
key=row[4]
if key not in result:
result[key]=1
else:
result[key]+=1
print('result:',result)
---------------------------------------------
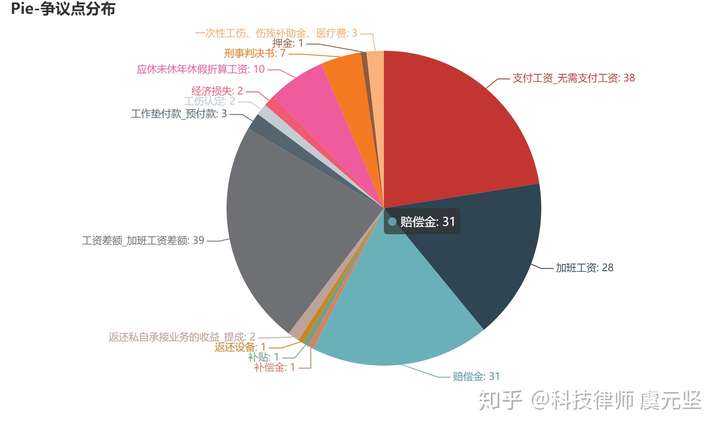
result={'支付工资_无需支付工资': 38, '加班工资': 28, '赔偿金': 31, '补偿金': 1, '补贴': 1,'返还设备':1,
'返还私自承接业务的收益_提成':2, '工资差额_加班工资差额':39,'工作垫付款_预付款':3,'工伤认定':2,'经济损失':2 ,'应休未休年休假折算工资':10,'刑事判决书':7,'押金':1,'一次性工伤、伤残补助金、医疗费':3}
转换为pyecharts要求的参数的数据格式:
_list=[]
for k in result:
p=(k,result[k])
_list.append(p)
print(_list)
-------------------------------
[('支付工资_无需支付工资', 38), ('加班工资', 28), ('赔偿金', 31), ('补偿金', 1), ('补贴', 1), ('返还设备', 1), ('返还私自承接业务的收益_提成', 2), ('工资差额_加班工资差额', 39), ('工作垫付款_预付款', 3), ('工伤认定', 2), ('经济损失', 2), ('应休未休年休假折算工资', 10), ('刑事判决书', 7), ('押金', 1), ('一次性工伤、伤残补助金、医疗费', 3)]
转换为图表
pie = Pie()
pie.add("", _list)
pie.set_global_opts(title_opts=opts.TitleOpts(title="Pie-争议点分布"),legend_opts=opts.LegendOpts(is_show = False))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
pie.render("pie.html")
转换为饼图:
我们也可以根据需要,转换为其他的柱状图、折线图等等其他图表。这里不做更多介绍。
总结
本文涉及的知识点比较多,难点主要在于正则表达式的书写,需要尽可能多的满足大部分文档的要求,否则剩余的文档越多,手工处理的工作会越多,正则表达式的书写,需要反复查询未匹配到的文档,进行修正。
其他的知识点,还涉及到文件夹文件遍历和筛选、word文档处理、excel文档处理,数据可视化操作等知识点,但总体而言,处理的方式还是中规中矩的,前面的文章也全都介绍过。
另外,我们也发现,Python并不能代替所有工作,争议点的筛查提取,还是需要人工来处理。不过实际上,通过机器学习等技术,也是完全可以实现自动化的。但是对于普通使用者来说,学习门槛和时间成本都太高,得不偿失。得益于前期的段落提取,这一步的工作量相对已经简单了很多。另外,本文呈现的最终结果,也并不完美,要得到更完美的报告,还需要不少润色和处理。
从另一个视角来看,本文的方法不仅可以用来做行业的白皮书,也可以用于诉讼领域,将类案查询结果,利用Python数据处理分析后,转化为可视化图表,会得到更好的庭审展示效果。

- 点赞
- 收藏
- 关注作者
评论(0)