Python法律实务应用——制作爬虫获取指导案例

hi,大家好,我是虞元坚律师。爬虫技术,是python的一个重要应用领域,也是互联网技术中非常常见的一项技术。我之前已经写过很多有关爬虫的文章,但是大多数都是关于爬虫技术涉及的法律问题方面。今天,我就有针对性的来讲一讲,如何利用Python制作我们的爬虫工具,并且自动化搜集信息。
为了不耽误大家时间,我先提前总结下本文主要面向的对象和会适用的知识。
适用对象:已经有一定入门知识的Python学习者,或者法律从业者虽无python学习经验的,可以囫囵吞枣的看。
会用到的知识:完整的知识需要用到的有json库使用、 requests库使用、正则表达式、python操作mysql数据库等,但是本文主要介绍利用requests库来进行爬虫。requests库主要是用来模拟request请求的,我们常用的get请求和post请求,都可以用到,其中的session对象,可以用来留存请求过程中的数据,比如cookie,而无需重新获取。爬虫技术,其实归根到底,就是利用计算机来模拟网络请求,从而自动化采集信息。
难度:初级。
对于爬虫工具的制作,一般有以下几个流程:
1、找到目标网站的数据接口,获取响应的参数
2、查看是否有反爬虫策略,如果有的话需要制定策略
3、将获取的数据解析并进行存储(本文存储在MySql数据库中)
第一步:我们的目标网站为:
里面有最高法院指导性案例和高级法院参考性案例,前者7页,后者52页,下面我们通过请求最高法院指导案件来举例, 通过F12打开控制台,打开该网站点击各链接后,从网络链接侦测中,很容易就发现接口链接为:https://splcgk.court.gov.cn/gzfwww//qwallist,甚至把该链接直接放在浏览器里就可以显示出返回的数据,通过控制台,我们可以找到请求这个链接用的是post方法,涉及的四个参数分别为:
"fbdw": '最高人民法院', #选择最高法院还是高级法院的参数
'lx': 'lzdx', #我也不知道什么含义,原样保留就可以
'bt': '', #同上
'pageNum':'1' #页码第二步:发现无反爬策略。其实大部分网站运营者都不需要制定反爬虫措施,一来本身数据量并没有那么大,爬虫并步会影响到网站的顺畅运行,二来公开的数据尤其法律法规也无知识产权的问题。因此,利用爬虫技术绝大多数情况下不会遇到法律问题,但是具体情况具体分析,这里不对法律做深入讨论,有兴趣的可以参看我前面对爬虫的法律文章,接下来看具体的爬虫代码:
session = requests.Session() #实例化一个session对象 需要提前引入requests库
session.headers.update({ #设置请求头部,这里我将请求的Origin 设置为了他们主站网站,其实不设置也没关系
"Origin": "https://splcgk.court.gov.cn"
})
list_url = 'https://splcgk.court.gov.cn/gzfwww//qwallist' #我们要请求的网站,即接口地址
# 最高法院指导案例的参数 start
data = {
"fbdw": '最高人民法院',
'lx': 'lzdx',
'bt': '',
'pageNum':'1'
}
# 最高法院指导案例的参数 end
response = session.post(list_url, data=data, timeout=(60, 60)) #发出post请求,设置超时为60秒
result = response.text #获得返回的内容上面的result最后的结果是下面这种json格式的一大串字符串。
{"list":[{"aymc":"","cBh":"ff8080816c22fc85016cd60bf4220de7","cBt":"指导案例112号:阿斯特克有限公司申请设立海事赔偿责任限制基金案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd60b3fb80de6","cBt":"指导案例111号:中国建设银行股份有限公司广州荔湾支行诉广东蓝粤能源发展有限公司等信用证开证纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd60a54a00de5","cBt":"指导案例110号:交通运输部南海救助局诉阿昌格罗斯投资公司、香港安达欧森有限公司上海代表处海难救助合同纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd609848b0de4","cBt":"指导案例109号:安徽省外经建设(集团)有限公司诉东方置业房地产有限公司保函欺诈纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd608b3d30de3","cBt":"指导案例108号:浙江隆达不锈钢有限公司诉A.P.穆勒-马士基有限公司海上货物运输合同纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd607d6b80de2","cBt":"指导案例107号:中化国际(新加坡)有限公司诉蒂森克虏伯冶金产品有限责任公司国际货物买卖合同纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd6027e140de0","cBt":"指导案例106号:谢检军、高垒、高尔樵、杨泽彬开设赌场案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd60122580ddf","cBt":"指导案例105号:洪小强、洪礼沃、洪清泉、李志荣开设赌场案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5febc250dde","cBt":"指导案例104号:李森、何利民、张锋勃等人破坏计算机信息系统案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5fc213c0ddc","cBt":"指导案例103号:徐强破坏计算机信息系统案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5fdd14d0ddd","cBt":"指导案例102号:付宣豪、黄子超破坏计算机信息系统案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5fac3790ddb","cBt":"指导案例101号:罗元昌诉重庆市彭水苗族土家族自治县地方海事处政府信息公开案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5f89b7b0dda","cBt":"指导案例100号:山东登海先锋种业有限公司诉陕西农丰种业有限责任公司、山西大丰种业有限公司侵害植物新品种权纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5f7e3e70dd9","cBt":"指导案例99号:葛长生诉洪振快名誉权、荣誉权纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5f39b490dd8","cBt":"指导案例98号:张庆福、张殿凯诉朱振彪生命权纠纷案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016cd5f2be250dd7","cBt":"指导案例97号:王力军非法经营再审改判无罪案","cFymc":"最高人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-28","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016c75c59e0d0a6e","cBt":"广东高院发布“全民禁毒工程”十大典型案例","cFymc":"广东省高级人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-09","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016c75c6116e0a6f","cBt":"广东高院发布服务保障民营企业健康发展典型案例(二)","cFymc":"广东省高级人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-09","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016c75c664ed0a70","cBt":"广东高院发布环境资源审判典型案例","cFymc":"广东省高级人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-09","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""},{"aymc":"","cBh":"ff8080816c22fc85016c75c514400a6d","cBt":"广东高院发布“全民禁毒工程”十大典型案例","cFymc":"广东省高级人民法院","cNr":"","cZw":"417A","dtCreatetime":"","dtUpdatetime":"2019-08-09","esFymc":"","fymc":"","lckx":"","lm":"","lx":"","lzdx":"","nZt":"","qzpx":0,"ssSf":"","ssxq":"","tNr":""}],"listCorp":"","pageNum":1,"pageSize":0,"pages":59,"size":0,"total":1162}第三步 处理数据并存储:Python不能直接处理json格式的字符串,需要进行转化,一般我们都将其转换为字典格式,这里要用到json库。转化为字典后,取出我们要的字段,并将字段的内容分别存储进数据库,至此,我们除了内容全文外,其他我们想要的信息,如案例名称,发布单位,发布时间,案例编号(docid)都获取到了。
result = json.loads(result) #将json字符串转为字典格式
_list = result['list'] 获取字典中键为list的值,得到了我们想要的结果列表
for item in _list: #遍历列表,将列表中的数据提取并存储到mysql数据库中
title = unescape(item['cBt']) # 这个item['cBt']是详情页的url
public_org = unescape(item['cFymc'])
docid = item['cBh'] #docid是每个案例的编号,这个编号加上地址前缀就可以获得详情页的地址
public_date = item['dtUpdatetime']
#查找数据库中是否有同样docid的内容
sql='select * from '+self.config['table']+' where docid=%s'
cursor.execute(sql, (docid))
row_1 = cursor.fetchone()
#如果没有的话就将这些信息存入数据库,这里包含了案例名称,发布单位,发布日期等内容
if row_1 is None:
sql="INSERT INTO "+self.config['table']+" (name,public_org,public_date,class,docid,rawdata) " \
"VALUES (%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (title, public_org, public_date, _class, docid, str(item)))
db.commit()
success = success + 1 #计数,每成功一次success增加一次获取了案例列表后,下一步就是获取详情。通过前面的步骤,我们很快就知道详情的请求连接为: https://splcgk.court.gov.cn/gzfwww//qwal/qwalDetails?id= 加上我们之前获得的docid,通过get方式就可以轻松获得详情页面
url = 'https://splcgk.court.gov.cn/gzfwww//qwal/qwalDetails?id='
_url = url + row_1['docid'] #row_1['docid']是我之前存储在数据库里的案例列表中每个案例的docid
session = requests.Session()
session.headers.update({
"Origin": "https://splcgk.court.gov.cn",
"Referer": "https://splcgk.court.gov.cn/gzfwww//qwal"
})
respond = session.get(_url, timeout=(45, 45)) # proxies=proxies,
content = respond.text这里的content就是我们要的结果数据,不过我们有时候为了精简或者美化数据,会做进一步的处理,笔者一般选择正则表达式,来进一步筛选我需要的数据,因为正则表达式比较复杂,我这里就暂时不叙述。简单看一下:
p_detail = '<div class="fd-fix">(.*?)<div class="fd-file-tips" >' #正则表达式规则
res_detail = re.search(p_detail, content, re.M | re.I | re.S) #查询是否有符合正则表达式的内容
#有就更新进数据库,没有就失败
if res_detail is not None:
_detail = res_detail.groups()[0]
cursor.execute("update guidecase set content=%s where docid=%s", (_detail, row_1['docid']))
db.commit()
success = success + 1
print('插入成功,success', success)
else:
fail = fail + 1
bad = bad + ',' + row_1['docid']
print('fail,focid=', row_1['docid'])
print('bad:', bad) 因为提前知道了案例的页数,通过将上面的内容根据页数进行循环,我们就将所有的指导案例存储进了数据库,今后随时可以使用了。
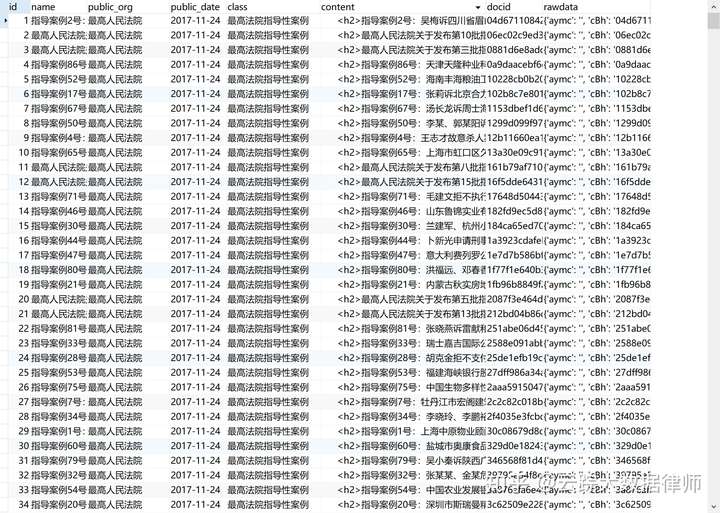
本文的场景其实并不是一个常用的场景,但是掌握这个基础爬虫工具的使用,在面对更大数量级的数据的时候,会发挥非常大的作用。尤其是在做一些搜集信息的尽调工作的时候,或者需要获取某个网站公开的大量信息的时候,可以省去我们非常多的时间。应该说,学习好爬虫,是学习python的必经之路。爬虫只是一个工具,通过与其他工具的相互组合,可以玩出更多的花样,可以参考我之前的爬虫网络取证的案例。

- 点赞
- 收藏
- 关注作者
评论(0)