静态代码分析工具评估指标及方法

原文为本人在infoq上分析的文章,链接:https://xie.infoq.cn/article/0e3fc6b85f0be1bd8ab30815d
0. 前言
当前,在企业的SDL和DevSecOps实践中,静态代码分析工具,作为一种缺陷检测技术,被大量采用。因为缺陷发现的时间越晚,其修复成本就越高,几乎呈指数增长。因为代码静态分析技术,尤其是面向源代码的静态代码分析技术,位于编码阶段,而且具有全自动运行、不需要执行代码即可检测,被大量应用到企业的构建流程中。
为了能够尽可能发现代码中存在的问题,企业都会选用静态代码分析工具。而静态代码分析工具的选用,不管是通过自研开发还是通过外部采购,对静态代码分析工具的评估都显得非常重要。主要体现在如下方面:
1) 为静态代码分析工具的选择提供依据
不同的静态代码分析工具,原理不同,能解决的问题也有所区别。一般基本的分析方法有词法分析、语法分析、类型分析、控制流和数据流分析等,形式化的分析方法还有抽象解释、符号执行、定理证明等。不同的实现,对应的能力会有很大区别,选择一款或者几款符合自己能力要求的工具就非常重要;
2) 为静态代码分析工具使用优化提供依据
即使是已经采购到的工具,也需要能够全面了解该工具的能力,识别对自己关心的能力的覆盖情况,方便对工具的能力进行扩展,有效的静态代码分析工具的能力评估可以为工具开发和维护人员改善工具使用、提高工具检测精度、降低误报和漏报提供重要的依据;
3) 为静态代码分析工具集成使用提供依据
一般单一一款静态代码分析工具受技术制约,很难独立满足企业在查全率和查准率方面的需求,需要同时采购多款静态代码分析工具,结合多种工具的长处,通过相互印证和相互补充,可以有效降低单一工具存在的误报、漏报的问题,这也依赖了对静态代码分析工具能力的有效评估;
4) 不同工具的能力评估和对比
一般静态代码工具的使用有两个目的:①看护公司的编码规范(包括安全编码规范和通用编码规范),②识别代码漏洞并修复。因此,从这两个目标的达成来看工具测评,就需要关注不同的工具对公司编码规范的覆盖的达成度,及对已知漏洞的识别能力,或者是对标业界优秀的工具的能力的对比。
下面将从静态代码评估的指标、用例集和自动化测试平台等三方面分别对静态代码分析工具的评估进行简单介绍。
1. 静态代码分析工具评估指标
下面将从两方面对评估进行介绍。第一部分介绍如何从一个更高层面上,评估一款静态代码分析工具是否适合自己使用(为选择提供依据),第二部分介绍最重要的关于如何评估一款静态代码分析工具能力的相关指标。
1.1 静态代码分析工具选用衡量指标
为了能够选择一款适合自己公司内部使用的静态代码分析工具,需要从多个方面对静态代码分析工具进行评估。下面介绍几个比较重要的方面,供大家参考(企业也需要结合自己的关切,增加自己的评估指标,才能采购到符合自己要求的工具)。
1) 工具嵌入公司SDL流程和日常构建流程的难易程度
这个指标我们一般也称为易集成性或可集成性,因为静态代码分析,一般是嵌入在公司的日常开发流程中(IDE级在开发时检查、代码上库时作为门禁检查、每日版本级定时构建),这样才能方便用户使用,如果无法方便快捷地嵌入到公司的日常构建流程,那么使用起来就会有较大成本。
一般在如下的一些流程中体现:
① 触发分析的方式,例如命令行方式触发或者api调用触发分析,是否支持多任务同时分析等;
② 缺陷的展示方式,是否方便统一的进行管理;
③ 缺陷跟踪方式,是否支持缺陷的跟踪处理;
④ 扩展规则的管理方式,是否可以支持集中管理等。
当然,如果企业财大气粗,可以和静态代码分析工具厂商提定制化需求。
2) 效率和机器性能约束
这个指标一般也称为可用性,指在一定的性能的机器(例如8U16G、16U32G等性能机器)上面,在符合用户要求的时间内完成扫描的能力。
如前面所述,静态代码分析一般会在IDE本地开发、代码上库、每日定时构建等几种情况下使用,尤其是IDE本地开发和代码上库的门禁检查,都有非常高的性能指标要求,要求在分钟级甚至秒级完成分析,否则就会有非常差的用户体验。
3) 分析工具本身分析能力
即静态代码分析工具本身提供的能力,主要包含两方面的内容:
① 静态代码分析工具的实现原理,一般静态代码分析工具的技术和可以检查的缺陷类型是相关的,通过了解静态代码分析工具使用的技术,可以粗略分析静态代码分析工具的能力。
② 通过静态代码分析工具能力测评,评估静态代码分析工具能力,相关指标参考1.2节的内容,测评时使用的用例集和方法参考第2章和第3章内容。
4) 二次开发扩展能力
这个指标是指静态代码分析工具自定义规则开发扩展的能力,主要评估几方面的内容:
① 自定义规则的扩展能力和内置规则的差距。部分静态代码分析工具,自定义规则和原生内置规则可以实现的能力是一致的,甚至两者实现方式是完全一样的(比如Fortify工具,自定义规则和内置规则实现方式类似),但是有些工具提供的自定义规则的能力比原生内置规则的能力差,能实现的能力有差别。
② 自定义规则的开发方式。有些静态代码分析工具,自定义规则需要较大的门槛,例如,原来Coverity基于SDK的开发方式,是C++语言开发的,如果要开发Coverity SDK规则,就需要有C++基础;而后来的CodeXM规则,开发门槛就比较低。比较舒服的是提供基于DSL的开发方式,例如 Semmle的Code QL(https://help.semmle.com/QL/learn-ql/),类似于 SQL 的规则写法,就比较容易入门。
③ 自定义规则的保存方式。自定义规则的保存方式,是否利于集成到公司的平台,是否利于统一维护。
1.2 静态代码分析工具能力评估指标
1.2.1 基本测评数据
评估静态代码分析工具,首先需要使用工具对缺陷进行分析,获取下表中的一些数据(混淆矩阵):

对上面的表进行简单的介绍:
TP(true positive):工具报告有缺陷,并且实际上有缺陷,即正确报告缺陷数量;
FP(false positive):工具报告有缺陷,但是实际上没有缺陷,即误报的数量;
TN(true negative):工具没有检查出来缺陷,并且实际也确实没有缺陷;
FN(false negative):工具没有检查出来缺陷,但是实际上有缺陷,即漏报的数量。
1.2.2 基本能力评估指标
下面介绍几种静态代码分析中非常重要的一些评测指标:
1) 精确度(Precision)
精确度为缺陷报告中的正确告警的数量与总缺陷数量的比,如下:
精确度描述的是工具的查准率,表达了工具缺陷报告的可信度。如果精确度很高,则说明工具缺陷报告中的误报个数很少,工具缺陷报告的可信度高。反之,则说明工具缺陷报告中误报很多,噪音大。这会影响缺陷报告的使用价值;使用者将在甄别正报缺陷和误报缺陷的工作中花费大量的时间,严重影响工具缺陷报告的易用性、可用性。
精确度同时反映了误报率,精确度越高,误报率相应会比较低,但是,误报率真正的计算方式,却有两种,一种计算方法以检查出来的误报和检查出来的所有缺陷的比值(这种计算方法,在实际工具使用场景下比较有意义),计算方式如下:
另一种计算方法,则是以检查出来的误报和总的good case的比值,计算方式如下:
我们可以看出,上面的计算方法更适合真实代码检查场景,因为无法明确good case情况,而下面的计算方法,更适合统计学意义的统计及测试(测试集已经知道了所有的good case 的情况)。
2) 召回率(Recall)
召回率,也称为查全率,为工具检查的报告中的正确告警的个数和测试集中真实存在的缺陷个数的比例,召回率的计算公式如下:
召回率表达了工具缺陷报告对于测试集真实缺陷个数的覆盖程度,召回率高,表示工具报出了该测试集较多的缺陷,说明工具的漏报率低;而召回率低,则表示工具只检测出来了该测试集少量的缺陷,也就是说存在大量的漏报。
召回率反映了工具的漏报情况,召回率和漏报率的和为1:
3) F-Score
F-Score 是基于精确度和召回率的综合指标,是精确度和召回率的调和平均值(精确度和召回率任何一项很高,都不能说对该规则支持很好。例如,如果对某条规则,没有任何漏报,但是误报非常高,或者没有误报,但是漏报非常高,都不能说支持得很好),该指标的值总分布在精确度和召回率之间,F-Score 可以用于综合评估工具的检测能力。F-Score的计算公式如下:
4) 覆盖度(Coverage)
覆盖度是工具检测出来的缺陷类型数量和测试集中缺陷类型总数的比值。在此,缺陷类型由用户关心的缺陷类型来确定,比如缺陷类型总数可以为测试人员所在公司的编码规范,以测试对编码规范的支持程度。当前业界比较著名的测试用例集Juliet,是基于CWE来进行区分的,CWE是一种业界通用的安全类型的缺陷分类标准,例如如果我们以Total_CWE_Num表示测试用例集中总的CWE缺陷类型数量,以Detected_CWE_Num表示工具检查出来的CWE缺陷类型数量,则以CWE覆盖为例,覆盖率可表示为:
覆盖率是一项非常关键的静态代码分析工具指标,因为覆盖率回答了“工具支持多少种缺陷类型”这个问题,而且一直也是静态代码分析工具厂商很重要的宣传点,代表了工具能力的广度。当然,具体到每种缺陷类型的支持情况,就会有很大差别。
5) 交叉度(Overlap)
交叉度不属于单个工具能力的评测范围。用来评估不同工具能力的相似度。交叉度是被多个工具检测出来的缺陷个数占这些工具所有缺陷个数的比例,也就是工具的缺陷交集和缺陷并集的比。工具之间的交叉度越高,表明各工具共同找出来的缺陷越多;则两种工具就越相似。
交叉度的测评,主要有如下两点意义:
(1) 用于工具替代的能力测评
例如希望采购一款工具替代当前使用的工具,则可以通过计算两款工具的交叉度来确定替代的可行性;或者是希望检测某一款工具和另一款工具的对比情况,例如自研和商用工具的对比。
(2) 用于工具集成优化
在多工具集成优化时交叉度高将可能提升缺陷报告的精确度;而交叉度低,将在工具集成过程中找到更多的缺陷,从而提高缺陷报告的召回率。
1.2.3 ROC曲线
如下左图(图中ROC曲线,来自于https://www.cnblogs.com/dlml/p/4403482.html)所示,以 false positive rate(统计学意义,上面误报率统计的第二种算法)为横轴,以true positive rate(上面的召回率) 为纵轴画出来的曲线。
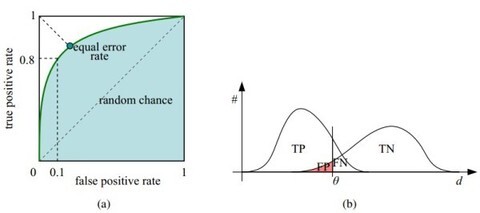
如上图,在ROC曲线中,越靠近左上角,检查效果越好,越靠近右下角则说明检查效果越差。
一般在静态代码分析工具完成测评后,针对所有的规则(关心的能力项,例如CWE)计算出来false positive rate 和 true positive rate,然后在ROC图中划出相关的散点(表示每个能力项),则可以比较直观地查看整体上的工具的能力。
2. 用例集选择和使用
2.1 用例集概述
用例集是用来评估静态代码分析工具能力的。自然最朴素的想法,就会有如下的一些要求:
1) 包含尽可能多的缺陷类型,最好可以把所有的缺陷都给包进来,跑一次通吃天下;
2) 每种缺陷的位置,good case 和 bad case 的数量、位置等,我都可以知道,这样统计起来就可以非常方便;
3) 最好是真正项目中的代码,可以反映出来真实业务场景中的漏洞,而不是简单梳理几个用例来忽悠人。
当然,我们自己也知道,要满足上面的需求,根本不可能,每个方向,都只能尽可能地往上面靠。
从用例集的构建方式来看,用例集可以分为用户构建用例集和真实项目用例集两类。
用户构建用例集,就是用户构建的用例集,例如Juliet用例集(https://samate.nist.gov/SRD/testsuite.php),就是一种典型的用户构建用例集。一般来说,用户构建的用例集,支持的用例会更全,但是相应的,在代码复杂度上面,会明显弱于真实项目代码,从而无法真正体现出来工具能力,同时,因为用户构建用例集时,是根据缺陷类型来构建的,因此用例集无法体现出来真实项目用例集中缺陷的比例。
真实项目用例集,就是以业界真实项目作为测试用例来进行测试,例如拿OpenSSL的源码来进行测试,这时候,OpenSSL就是真实项目用例集。使用真实项目用例集,所带来的问题是显而易见的,对于工具的每一条告警,我们都需要分析是否真正的告警,而且不知道good case 和 bad case 的全集,不方便统计,不知道每个缺陷发生的真正原因,而且真实项目用例集,缺陷种类不全,限制了测试的范围。主要还是适合多种工具的对比测试。
2.2 用例集构建和扩充
用例集的选择、使用及不断扩充,对于静态代码分析工具评测非常重要。目前主要的一些补充用例的方向包括但不仅限于:
(1) 社区共建,提供用例的上传机制(代码、漏洞描述、代码标准规范等),扩充用例集(难点在于减轻不同用户上传的用例可能存在的相互影响,从而最大可能的体现原测试用例的测试意图);
(2) 通过对缺陷管理系统(JIRA、GitHub等)、信息披露系统的信息爬取,获取漏洞信息,然后通过patch梳理,补充用例集;
(3) 整合业界不同的用例集,包括已经开源的用例集,工具提供的正反例等;
(4) 通过对一些特定场景的用例,进行混淆扩充成为新的用例,通过这种方式,甚至可以实现用例的翻倍扩充。
3. 静态代码分析工具评估实现
如果涉及到了大规模的测评工作,并且需要进行大量、长期的测试,则开发一个自动化的测评系统就显得很有价值。
通过一个自动化的测评系统,从下面的维度实现统一的管理:
1) 实现对用例集的统一管理
每种用例集的基本信息,good case和bad case的基本情况,支持用例集的共建扩展(及上面列出的扩展方法)等;
2) 编码规范管理
或者企业关心的其他的度量维度,例如可以直接针对CWE规范管理、CVE漏洞管理等,可以针对多角度的规范管理;
3) 工具及工具规则的统一管理
待评测的工具,需要进行规范统一管理,支持对工具的管理,例如新增、删除等,支持工具规则的管理,工具规则和CWE的映射、编码规范的映射等,方便后续的指标计算;
4) 实现工具的自动化分析和结果解析
能够针对用例集进行适应,支持统一的缺陷管理,支持模块化的工具集成(需要结合工具的使用方式,最好工具集成,能够适配各种不同用例集的使用)和解析,方便动态增加新的工具;
5) 实现工具的能力指标计算
包括TN、FN、TP、FP等的自动化对比识别(例如,能够识别特定工具缺陷的报告方式,并结合用例中针对特定缺陷的标注,对比得到TN、FN、TP和FP等信息)和计算,前面1.2节介绍的相关指标,企业关心的其他指标等;
一般在TN、FN、TP、FP计算上,需要有所取舍,下面是一些可行的对比方式:
① 在good case 上,一般如果有误报,并且报出来多条,都认为是误报(比如在 good case 上,报出5条相关缺陷,就认为有5条误报),而bad case上,如果报出来多条,则需要合并,只认为正报了1条;
② 在缺陷种类是否匹配上,有几种方式,一种是事先对工具规则进行标注;二是根据CWE等统一分类标注;三是经过一定的相似度计算方法,比如匹配描述信息等,都可以结合使用;
③ 在很多基于数据流分析的规则中,都会有trace信息,而且工具报缺陷的方式各不相同,有些报在source点,有些报在sink点,有些报在source点所在函数中调用到sink点所在函数的位置,这样就给匹配带来了很多难度,此时可以对用例中的trace进行有效标注,只要工具报的位置和用例中的trace标注有命中,就认为是匹配到。
6) 实现测评数据(指标)的统一呈现
例如通过ROC图(TP、FP等)、柱状图(比如区分度等)、饼图(比如覆盖度)等各种方式,实现相关的度量指标的查看,同时,企业内部肯定有其他的一些度量指标和维度,关心的内容各不相同;
7) 支持人工干预
例如在自动化的计算前,先基于自动化规则计算TN、FN、TP、FP,要能够支持人工干预,针对计算错误的点进行修正。
一般来说,一个自动化的测评系统,可以很大程度减轻静态代码工具的评估的工作量。当然,如果企业这方面就是一两次测试,也没必要开发个系统。
上面只是大概进行了一些介绍,到企业实际开发中,弹性非常大,和业务目标强相关,可以选择部分模块,也可以完全开发并和其他业务系统联动。
4. 总结
如上的介绍,静态代码分析工具评测,主要涉及到几方面的工作:
1) 用例集的使用和扩充
2) 测评的实施及指标计算结果呈现
3) 自动化测评系统开发
上面介绍的,只是理论上的一些场景,在实践中,需要根据企业目标进行调整和增减,并且可以和其他的业务系统整合一起使用,以期达到更好的应用效果。

- 点赞
- 收藏
- 关注作者
评论(0)