画张图,就能秒级洞察千亿复杂关系

在数据规模越来越大、数据结构越来越复杂的大数据时代,传统的关系型数据暴露出了建模缺陷、水平伸缩等问题,于是具有更强大表达能力的图数据受到业界极大的重视。如果把关系数据模型比做火车的话,那么现在的图数据建模可比做高铁。
什么是图呢?
图(Graph),将信息中的实体,以及实体之间的关系,分别抽象表达成为顶点以及顶点间的边这样的结构数据。
像Facebook和Twitter这样的社交网络,其数据天生就适合于图表示法。诸多典型的大数据应用易于通过图来进行建模,如交通网络、CDR通话图、用户与产品之间的二分图、论文中作者之间的合作关系网、文章之间的索引关系、金融交易网络等等。
于是,基于图数据的分析技术—关系分析(图计算)应运而生。图计算系统就是针对图结构数据处理的系统,并在这样的数据上进行针对性优化的高效计算。
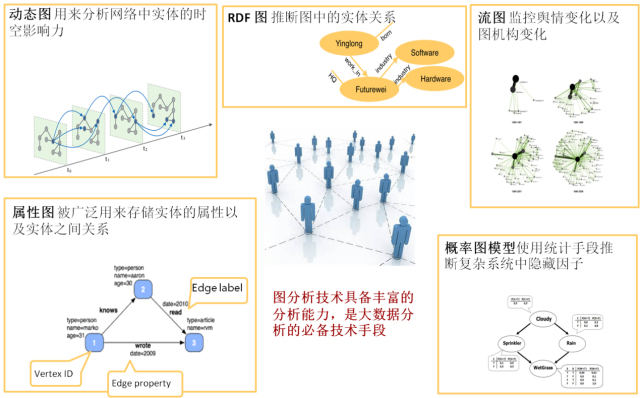
我们可以用图这个通用的、富有表现力的结构来建模各种场景,从宇宙火箭的建造到道路系统,从食物的供应链及原产地追踪到人们的病历。
在许多实际场合中我们都能找到图分析的应用。例如:
在金融风控中,将多种变量(如账号、交易、资金)之间的关系通过图联系在一起,共同分析其对金融安全的影响,典型的金融异构系统,如洗钱、庞氏骗局等都能反映出特定的图结构。
比如在大图上做环路检测可以有效识别循环转账,帮助预防信用卡诈骗;
分析可疑人物的近邻好友和基于属性图的社团发现可以进一步挖掘出骗子团伙或者僵尸账号。
知识图谱通过图来建立知识概念之间的联系,并在此基础上设计推理算法。知识图谱常用来进行知识推理,从语义层面理解用户意图,改进搜索质量。LinkedIn的知识图谱对会员显式输入的技能,比如“分布式系统”、“Hadoop”等,自动推理出其他技能,比如“产品管理”、“NoSQL”等。特别是AI和机器学习中需要处理很多由实体和关系构成的信息。例如,在推荐系统中,用户和电影就是实体,他们之间的喜好构成了实体间的关系;搜索查询和商品也是实体,他们之间的点击率构成了实体间的关系。
业界洞察
整个图计算领域可进一步细分为查询分析、计算引擎、存储管理、可视化等子方向。目前并没有一种涵盖所有子方向的图引擎。例如图数据库Neo4j、Titan等擅长于图数据的实时查询,但并不能高效地对图数据进行离线分析;分析引擎Turi、GraphX侧重图数据的离线分析和挖掘,却不能对属性图进行管理,且不支持实时查询。
同时,图计算领域也面临大数据环境下带来的巨大挑战。就当前的社交网络而言,对全网做查询分析就意味着对数十亿节点(人物)数百亿边(关系)的大图进行操作。而规模更大的互联网、物联网可达到百亿节点千亿边甚至以上。在如此巨大数据量的情况下,实现高效高并发的查询是当前一大难点。
一方面,鉴于图数据结构的稀疏性,并不能通过GPU等硬件手段上取得很好的加速。
另一方面,图的局部性也有别于传统机器学习系统的数据组织形式。
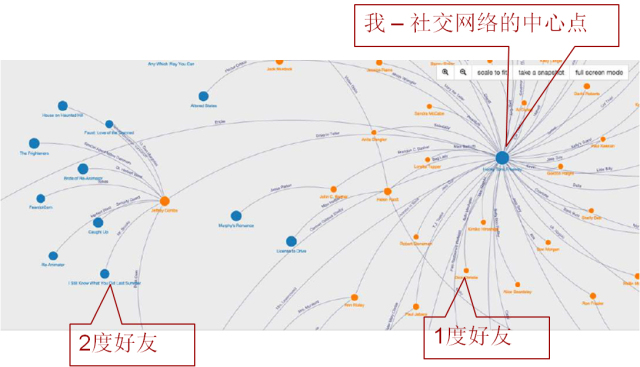
如下图所示,社交网络中一个人的平均好友数达到数百,那他的2度好友就会达到数十万之多,于是探索一个人ego-net(对图中某节点做扩线查询得到的子图)往往会遍历上千万甚至更多条边。
在多机环境下,这些边往往分布在不同的机器上,进一步增大了遍历的难度。此外,随着数据复杂性的增加,节点和边往往带有属性信息。这些信息既可以是固有属性(如年龄、性别等),也可以是计算得到的结果(如介数中心度、pagerank值等),这些计算结果往往又是下一次查询的输入。属性管理与交互式计算查询,是图领域的另一大挑战。
华为关系网络分析解决方案
华为人工智能平台上的EYWA图引擎提供了从底层的图存储和管理、核心的高性能计算引擎、直到面向上层的图分析和图查询,一整套的关系网络分析解决方案,其基本特征如下:
大规模
EYWA通过分布式优化Parallel Sliding Window(PSW)的图计算框架,支持百亿节点千亿边规模的超大图计算和查询。系统性能随数据规模几乎线性扩展,能够满足诸多业务的需要,例如电信网规网优(路径规划、主备路径优化)、社会安全监督(社团发现、关键人识别、潜在关系发现、潜在嫌疑人识别)、金融风控(洗钱模型、虚假交易、风险评估)等多个应用场景。
高性能
EYWA基于边集流的块状数据组织兼顾了图计算与图数据查询的性能要求,并集成了多种面向行业领域的优化算法。它通过优化的prefetch策略降低磁盘的IO操作的性能损耗,同时也通过松弛BSP模型来降低通信IO带来的性能损耗。相比Powergraph, GraphX, Powerlyra等计算速度提速4~10倍以上,而图数据查询的性能提升更加明显,具备秒级多跳实时查询的强大性能。
通用性
Eywa对接标准的图查询接口TinkerPop和图查询语言Gremlin,通过服务化API将图引擎能力开放给业务。基于通用接口和查询语言,可以很容易的进行二次开发(供行业应用、可视化前端、与机器学习集成来吸引领域客户)。
一体化
EYWA实现图计算、图查询和图存储的一体化:提供基于属性图模型的数据存储,支持基本查询(点查、边查、遍历、属性过滤等),常用的图算法(PageRank, SSSP, K-core, graph metrics等)可以基于图的结构和属性进行计算,并将结果回写到图的某一属性中便于后续查询。

EYWA已经在百亿节点和千亿边的大规模图实践上验证了其高并发、低时延的能力。
其中一份实验用到的公开数据集是基于斯坦福大学SNAP研究组提供的Friendster, 来自真实的社会网络。我们用全球计算机排名Graph500提供的Kronecker代码在对该数据集进行扩展,形成了具有2.5亿点110亿边的大图和5.2亿点和1011亿边的超大图。通过扩线查询模拟对社交网络节点的ego-net的探索,我们的实验结果显示在百亿边图100并发下的3跳扩线查询总响应时间基本在0.1秒以内。
以下是针对不同并发请求数EYWA系统的响应时间(上:并发状态下单个请求的执行时间;下:所有并发请求执行完成的总时间);千亿边图100并发下3跳扩线查询总响应时间在0.5~3秒(随种子节点不同而变化)


EYWA图引擎支持基于属性图模型的复杂属性管理、内置了20余种拓扑度量和基本图分析算法,并通过服务化API将图引擎的能力开放出去,提供全方位的关系网络洞察。
在电信网络等行业实践中,利用EYWA我们很自然地表达了各类交换机、路由器、终端设备等网元构成的物理通信网络,以及在其上抽象出来的逻辑网络,并在此基础上运行复杂的网络规划仿真算法,极大提升了业务工作效率;
在金融、公共安全等行业实践中,利用EYWA可表达大量的人物、账户、商家、手机等相互关联的不同实体,并通过顶点和边上的属性(如人物的年龄、性别,账户的创建时间,人和商家之间的交易金额等)精细描述真实世界的信息。基于EYWA大规模高并发的支持,以及内置的最短路径、中间人查找、回路分析、邻居子图等分析功能,客户能够高效地进行反欺诈、团伙发现等业务计算、帮助业务人员发现大量关联数据背后有价值的隐藏信息。
本文属于转载文章,原作者享有本文一切权利。

- 点赞
- 收藏
- 关注作者
评论(0)