Spark快速入门系列(7) | Spark环境搭建—standalone(4) 配置Yarn模式

大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是Spark环境搭建—standalone(4) 配置Yarn模式模式。


一. 准备工作
官方文档地址:http://spark.apache.org/docs/latest/running-on-yarn.html

1. 安装启动Hadoop(需要使用HDFS和YARN,已经ok)
此步如果不会的话,可以参考博主以往博文一文教你快速了解伪分布式集群搭建(超详细!)只需查看如何配置HDFS即可
2. 安装单机版Spark(不需要集群)
-
1. 把安装包上传到
/opt/software/下 -
2. 解压文件到
/opt/module/目录下
[bigdata@hadoop002 software]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module
- 1
- 3. 复制刚刚解压得到的目录, 并命名为
spark-local
[bigdata@hadoop002 module]$ cp -r spark-2.1.1-bin-hadoop2.7 spark-local
- 1
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
二. Yarn 模式概述
Yarn有 client 和 cluster 两种模式,主要区别在于:Driver 程序的运行节点不同。
- client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
- cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)上,适用于生产环境。
1. cluster模式
在企业生产环境中大部分都是cluster部署模式运行Spark应用
Spark On YARN的Cluster模式 指的是Driver程序运行在YARN集群上
Driver是什么?
The process running the main() function of the application and creating the SparkContext
运行应用程序的main()函数并创建SparkContext的进程。

注意:
之前我们使用的spark-shell是一个简单的用来测试的交互式窗口,下面的演示命令使用的是spark-submit用来提交打成jar包的任务
- 示例运行
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上述标记的含义如下图:

2. client模式(学习测试的时候用)
Spark On YARN的Client模式 指的是Driver程序运行在提交任务的客户端

- 示例运行
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
- 1
- 2
- 3
- 4
- 5
- 6
3. 两种运行方式的区别
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里
其中,就直接的区别就是:
- 运行在YARN集群中就是Cluster模式,
- 运行在客户端就是Client模式
当然,还有由本质区别延伸出来的区别:
cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中
- 应用的运行结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个进程中, 如果出现问题,yarn会重启ApplicattionMaster(Driver)
client模式:
- Driver运行在Client上的SparkSubmit进程中
- 应用程序运行结果会在客户端显示
三. 工作模式介绍


四. Yarn 模式配置
- 1. 修改 hadoop 配置文件 yarn-site.xml
由于咱们的测试环境的虚拟机内存太少, 防止将来任务被意外杀死, 配置所以做如下配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

- 2. 修改后分发配置文件
// copy到hadoop003
scp /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml hadoop003:/opt/module/hadoop-2.7.2/etc/hadoop/
// copy到hadoop004
scp /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml hadoop004:/opt/module/hadoop-2.7.2/etc/hadoop/
- 1
- 2
- 3
- 4
- 5

- 3. 修改
spark-evn.sh文件名
[bigdata@hadoop002 spark]$ cd conf/
[bigdata@hadoop002 conf]$ mv spark-env.sh.template spark-env.sh
- 1
- 2
- 3

- 3.修改
spark-evn.sh文件
SPARK_MASTER_HOST=hadoop002
SPARK_MASTER_PORT=7077
// 添加如下配置: 告诉 spark 客户端 yarn 相关配置
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
// 如果是集群的话需要分发一下
[bigdata@hadoop002 spark]$ scp /opt/module/spark/conf/spark-env.sh hadoop003:/opt/module/spark/conf/
[bigdata@hadoop002 spark]$ scp /opt/module/spark/conf/spark-env.sh hadoop004:/opt/module/spark/conf/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

五. 运行结果及查看
- 1.
client模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
- 1
- 2
- 3
- 4
- 5

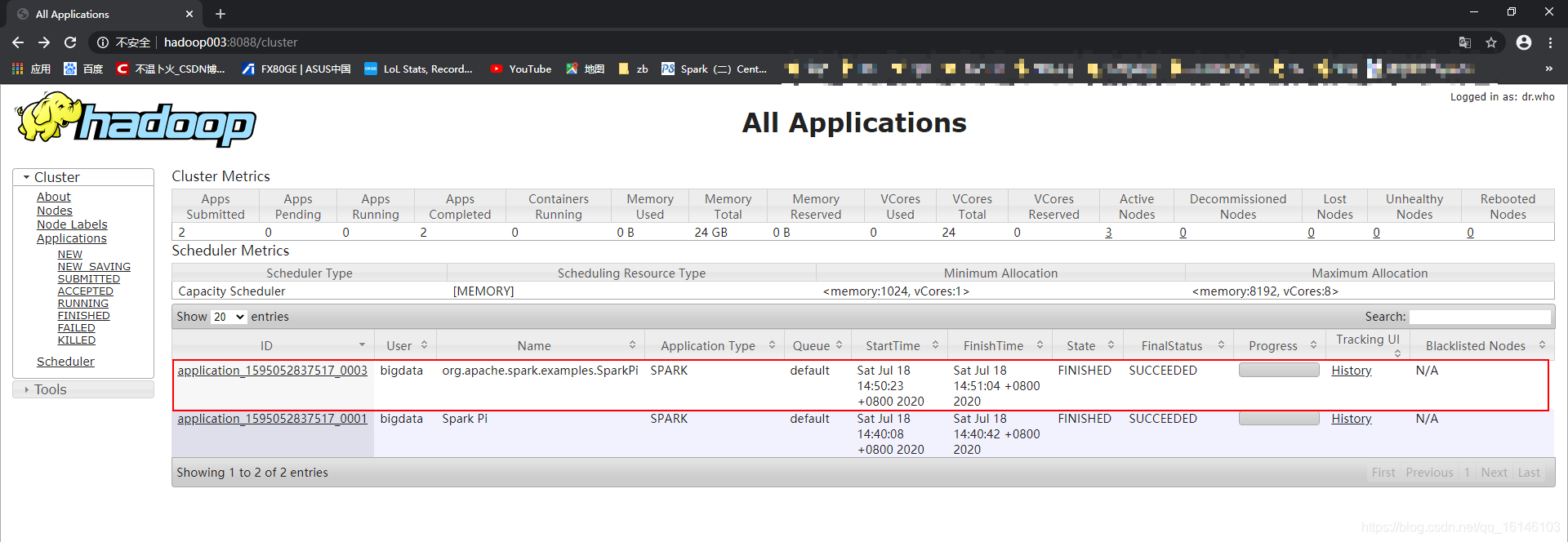
UI查看:
http://hadoop003:8088/cluster

- 2.
cluster模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!


文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/107405613

- 点赞
- 收藏
- 关注作者
评论(0)