【redis】redis内存管理、淘汰机制、内存优化

配置redis
如果想要运行一个内存高效的 Redis 数据库,首先需要理解那些在 redis.conf 配置文件中所有内存相关的指令。redis.conf 文件为大多数指令提供了丰富的内联文档,使得一些复杂的内存优化选项易于理解、更改和测试。
传送门:redis.conf翻译与配置内存管理部分
大多数 Redis 配置指令可以在运行时通过 CONFIG SET 命令进行设置。
最大内存限制
Redis使用 maxmemory 参数限制最大可用内存,默认关闭。
限制内存的目的主要 有:
用于缓存场景,当超出内存上限 maxmemory 时使用 LRU 等删除策略释放空间。
防止所用内存超过服务器物理内存。
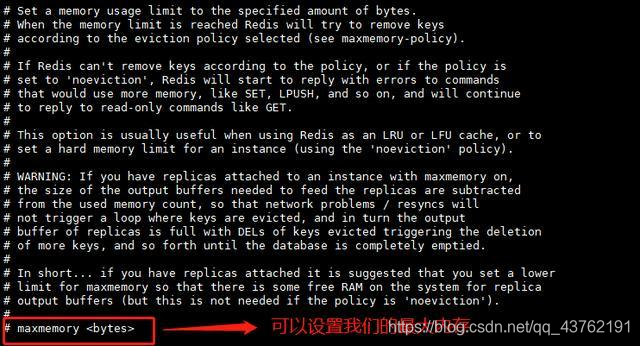
maxmemory 限制的是Redis实际使用的内存量,也就是 used_memory统计项对应的内存。由于内存碎片率的存在,实际消耗的内存 可能会比maxmemory设置的更大,实际使用时要小心这部分内存溢出。redis.conf翻译与配置(内存碎片部分)
Redis默认无限使用服务器内存,为防止极端情况下导致系统内存耗 尽,建议所有的Redis进程都要配置maxmemory。 在保证物理内存可用的情况下,系统中所有Redis实例可以调整 maxmemory参数来达到自由伸缩内存的目的。
查看redis内存相关信息:INFO memory
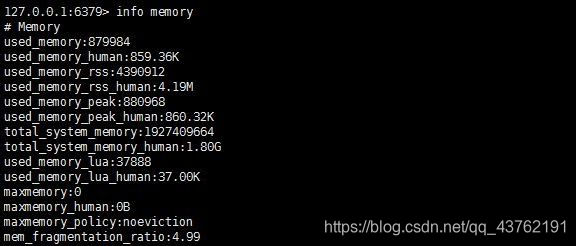
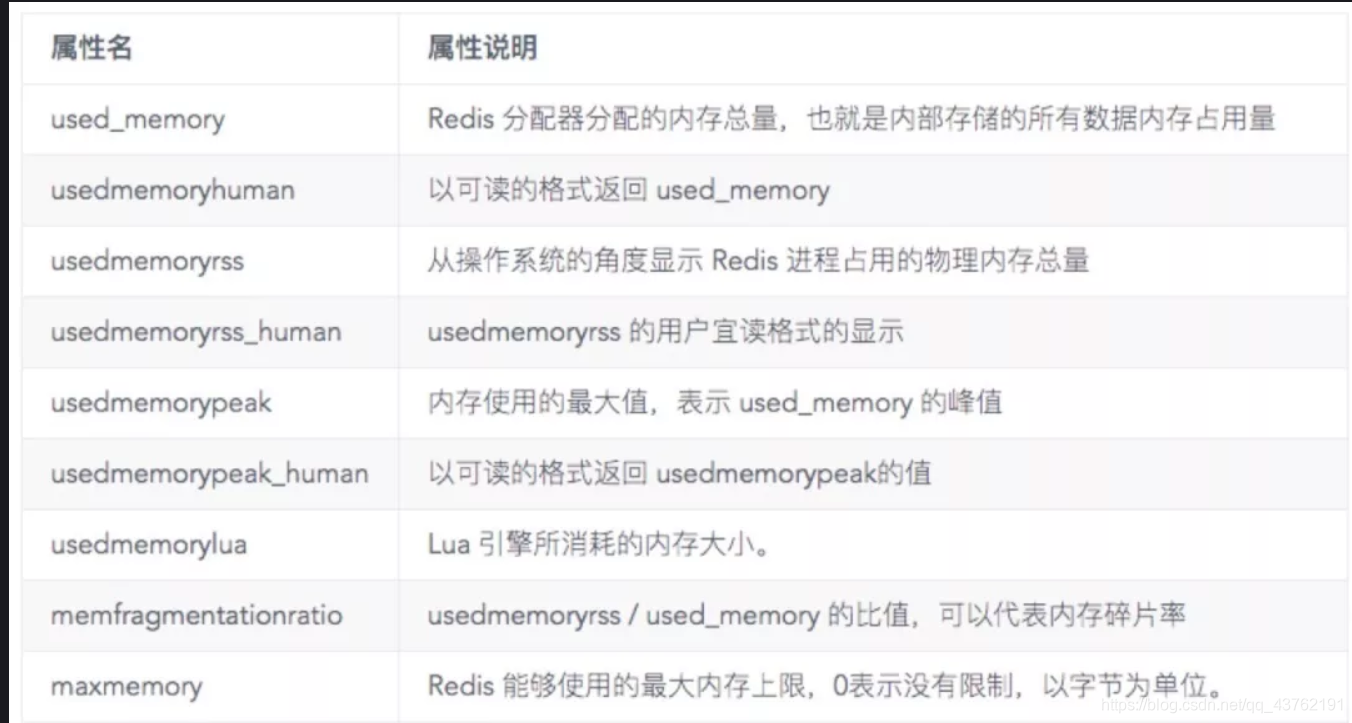
当 memfragmentationratio > 1 时,说明有部分内存并没有用于数据存储,而是被内存碎片所消耗,如果该值很大,说明碎片率严重。当 memfragmentationratio < 1 时,这种情况一般出现在操作系统把 Redis 内存交换 (swap) 到硬盘导致,出现这种情况要格外关注,由于硬盘速度远远慢于内存,Redis 性能会变得很差,甚至僵死。
当 Redis 内存超出可以获得内存时,操作系统会进行 swap,将旧的页写入硬盘。从硬盘读写大概比从内存读写要慢5个数量级。used_memory 指标可以帮助判断 Redis 是否有被swap的风险或者它已经被swap。
建议要设置和内存一样大小的交换区,如果没有交换区,一旦 Redis 突然需要的内存大于当前操作系统可用内存时,Redis 会因为 out of memory 而被 Linix Kernel 的 OOM Killer 直接杀死。虽然当 Redis 的数据被换出 (swap out) 时,Redis的性能会变差,但是总比直接被杀死的好。:建议自:https://redis.io/topics/admin
内存都去哪儿了?还没好好使用,就爆了

1.自身内存:redis自身运行所消耗的内存,一般很小。
2.对象内存:这是redis消耗内存最大的一块,存储着用户所有的数据。
3.缓冲内存:缓冲内存主要包括:客户端缓冲、复制积压缓冲区、AOF缓冲区。
客户端缓冲:是指客户端连接redis之后,输入或者输出数据的缓冲区,其中输出缓冲可以通过配置参数参数client-output-buffer-limit控制。
复制积压缓冲区:一个可重用的固定大小缓冲区用于实现部分复制功能,根据repl-backlog-size参数控制,默认1MB。对于复制积压缓冲区整个主节点只有一个,所有的从节点共享此缓冲区,因此可以设置较大的缓冲区空间,如100MB,这部分内存投入是有价值的,可以有效避免全量复制。
AOF缓冲区:这部分空间用于在Redis重写期间保存最近的写入命令,AOF缓冲区空间消耗用户无法控制,消耗的内存取决于AOF重写时间和写入命令量,这部分空间占用通常很小。
4.内存碎片:当然,这是所有内存分配器无法避免的通病,但是可以优化。
如果对这方面有想法的话:走近STL – 空间配置器,STL背后的故事
内存回收策略
Redis 回收内存大致有两个机制:一是删除到达过期时间的键值对象;二是当内存达到 maxmemory 时触发内存移除控制策略,强制删除选择出来的键值对象。
过期键值
Redis如何淘汰过期的keys
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
测试随机的20个keys进行相关过期检测。
删除所有已经过期的keys。
如果有多于25%的keys过期,重复步奏1.
为了获得正确的行为而不牺牲一致性,当一个key过期,DEL将会随着AOF文字一起合成到所有附加的slaves。在master实例中,这种方法是集中的,并且不存在一致性错误的机会。
然而,当slaves连接到master时,不会独立过期keys(会等到master执行DEL命令),他们任然会在数据集里面存在,所以当slave当选为master时淘汰keys会独立执行,然后成为master。
内存移除控制策略
8个解决方方案
当maxmemory限制达到的时候Redis会使用的行为由 Redis的maxmemory-policy配置指令来进行配置。
在redis.conf中提出了8个解决方法。
volatile-lru ->退出使用近似的LRU,仅使用设置了过期值的键。
allkeys-lru ->使用近似的LRU驱逐任何密钥。
volatile-lfu ->使用近似的LFU逐出,仅使用具有过期集的键。
allkeys-lfu ->使用近似的LFU驱逐任何密钥。
volatile-random ->删除一个具有过期设置的随机键。
allkeys-random ->删除一个随机键,任意键。
volatile-ttl ->删除最近过期时间的密钥(较小的TTL)
noeviction ->不驱逐任何东西,只是在写操作时返回一个错误。
LRU表示最近最少使用
LFU表示使用频率最低
LRU、LFU和volatile-ttl都是使用近似随机算法实现的。
注意:使用上述任何策略,当没有合适的键用于驱逐时,Redis会在写操作时返回一个错误。
一般的经验规则:
使用allkeys-lru策略:当你希望你的请求符合一个幂定律分布,也就是说,你希望部分的子集元素将比其它其它元素被访问的更多。如果你不确定选择什么,这是个很好的选择。.
使用allkeys-random:如果你是循环访问,所有的键被连续的扫描,或者你希望请求分布正常(所有元素被访问的概率都差不多)。
使用volatile-ttl:如果你想要通过创建缓存对象时设置TTL值,来决定哪些对象应该被过期。
allkeys-lru 和 volatile-random策略对于当你想要单一的实例实现缓存及持久化一些键时很有用。不过一般运行两个实例是解决这个问题的更好方法。
为了键设置过期时间也是需要消耗内存的,所以使用allkeys-lru这种策略更加高效。
回收进程如何工作
理解回收进程如何工作是非常重要的:
一个客户端运行了新的命令,添加了新的数据。
Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
一个新的命令被执行,等等。
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
近似LRU算法
Redis的LRU算法并非完整的实现。
Redis为什么不使用真实的LRU实现是因为这需要太多的内存。
内存优化
使用32位的redis
使用32位的redis,对于每一个key,将使用更少的内存,因为32位程序,指针占用的字节数更少。但是32的redis整个实例使用的内存将被限制在4G以下。
使用make 32bit命令编译生成32位的redis。RDB和AOF文件是不区分32位和64位的(包括字节顺序),所以你可以使用64位的reidis恢复32位的RDB备份文件,相反亦然。
位级别和字级别的操作
Redis 2.2引入了位级别和字级别的操作: GETRANGE, SETRANGE, GETBIT 和 SETBIT.使用这些命令。
对位操作不熟的话,可以看一下这两篇:
位运算 - 初见
位图 - 海量数据处理
尽可能使用散列表
小散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。
先到这儿吧,也该去吃饭了。

文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/108215037

- 点赞
- 收藏
- 关注作者
评论(0)