MySQL见闻录 - 入门之旅

在网上翻来覆去找不到一套适合新手自学的书,于是买了课,急急忙忙上完了课,又发现全还给老师了。
这一系列文放在这里,从下载软件开始,记录一条MySQL入门之旅。 新手也可以跟着这条路走,一条道走到黑。 粉丝可见,愿者上钩。
有任何疑问,参考三篇上课笔记,或者私信我。
文章目录
-
-
- 1、我的上课笔记
- 2、软件下载选择
- 3、示例数据库
- 4、DOS界面用户登录方式
- 5、取消语句
- 6、数据库操作
- 7、数据表操作
- 8、往数据表中插入数据
- 9、从表中检索数据
- 10、sampdb数据库资料
- 11、当前服务器下存储引擎
- 12、各存储引擎特性
- 13、如何选择合适的存储引擎
- 14、存储引擎设定
- 15、创建临时数据表
- 16、从其他表中创建新表
- 17、删除数据表
- 18、为数据表编制索引
- 19、删除索引
- 20、Alter 改变数据表的结构
- 21、获取数据库里的元数据
- 22、使用视图
- 23、事务处理
- 24、使用事务保存点
- 25、外键使用
- 26、数值类型
- 27、MySQL如何处理非法数据
- 28、操作符
- 29、复合语句与语句分隔符
- 30、触发器
- 31、索引的使用
- 索引为什么能提高查询效率?
- 挑选索引
- 32、MySQL的查询优化程序
- 33、使用explain 语句来验证优化器操作
- 34、其他话
- 35、C++语言使用MySQL
-
1、我的上课笔记
2、软件下载选择
相比于5代版本,这款跨越6、7代版本的8代版本有许多的好评,当然我也没体验过5代版本,反正要用就用最新的嘛。
3、示例数据库
示例数据库是人家书里面的,有书总比没书好。
示例数据库的链接会在后面给出。
打开MySQL客户端(如果已经配置好了系统路径也可以直接打开DOS界面),登录之后配置一个新用户:
create user 'sampadm'@'localhost' identified by 'secret';
grant all on sampdb.* to 'sampadm'@'localhost';
- 1
- 2
- 3
完成对新用户 sampadm的配置,本用户只能在localhost上登录。
完成配置后,就可以用账号:sampadm 密码:secret登录该账户了。
4、DOS界面用户登录方式
首先你要配置路径。
然后,登录指令:mysql -h hostname -p -u username;
或者:mysql -p -u username; //本机登录当然可以这样了
退出会话可以使用:quit;
5、取消语句
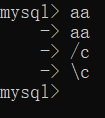
当你输入了好几条语句,但是又不想执行,你会发现删不掉,这时候就需要使用 \c
意会一下:
6、数据库操作
创建数据库,名字叫sampdb:create database sampdb;
查询当前使用数据库:select database();
查看当前服务器下所有数据库:show databases;
指定当前使用数据库为sampdb:use sampdb;
一条龙服务:

7、数据表操作
创建数据表:
方式1:代码编写
create table president
(
last_name varchar(15) not null,
first_name varchar(15) not null,
suffix varchar(5) null,
city varchar(20) not null,
state varchar(2) not null,
birth date not null,
death date null
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
方式2:.sql文件导入
先进入sampdb文件夹下,然后:source create_president.sql;
查看当前数据库下数据表:
查看某一张表的列:desc tablename;
查看某些列:desc president '%name';
查看当前数据库下所有表:show tables;
查看指定数据库下所有表:show tables from sampdb;
8、往数据表中插入数据
普通插入一条数据:insert into student values('Kyle','M',NULL);
一次插入多条数据:insert into grade_event values('2008-09-03','Q',NULL),('2008-09-04','Q',NULL),('2008-09-05','Q',NULL);
往指定列(不可为空的列必须插上数据)插入数据:insert into member(member_id,last_name,first_name) values(20,'linfeng','wu');
一条龙服务:

文件导入法:
source insert_president.sql;
接下来来这么一波配置,先把数据库搭建好开始干别的了:

9、从表中检索数据
一干查询语句我就不再细叙,这篇写好了基础的查询语句:SQL语句学习
需要实操的时候,可以先用select *查出表中所有数据,然后再进行实操设计。
删和改的语句也在里面了。
还需多加练习熟练各项基本操作,本章的操作和数据库在在后续章节将持续被使用。
10、sampdb数据库资料
链接:sampdb
提取码:4td8
11、当前服务器下存储引擎
1.使用show engines;以查看当前系统下所有引擎,如图:

圈出来那一行,yes就是有,no就是没有,default就是系统默认的,一般是开着的,disabled就是有,但是被关了。
你每创建一个数据表,MySQL就会创建一个硬盘文件来保存该数据表的格式(也就是它的定义),这个格式文件的基本名和数据表的名字一样, 扩展名是. frm.
比如说,如果数据表的名字是t,其格式文件的名字就将是t. frm。你创建的数据表属于哪个数据库,服务器就会在该数据库的数据库子目录里创建这个文件。
. frm文件的内容是不变的,不管是哪一个存储引擎在管理数据表,每个数据表也只有-一个相应的. frm文件。如果数据表的名字字符在文件名里会引起麻烦,SQL 语句里使用的数据表的名字有可能与相应的. frm文件的基本名(表名)不致具体到某个特定的存储引擎,它还会为数据表再创建几个特定的文件以存储其内容。
对于给定的数据表,与之相关的所有文件都集中存放在这个数据表所在的数据库的数据库子目录里。
存储引擎有什么重要作用呢?开头那三篇里面有介绍啦。
12、各存储引擎特性

13、如何选择合适的存储引擎
选择标准:根据应用特点选择合适的存储引擎,对于复杂的应用系统可以根据实际情况选择多种存储引擎进行组合。
下面是常用存储引擎的适用环境:
MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一
InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持。
Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。
Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
- 1
- 2
- 3
- 4
14、存储引擎设定
创建数据表时设定存储引擎:create table temp(i int) engine = innoDB;
这里插几条,
warning查看方法
有时候虽然执行语句没报错,不过会有警告,但是警告不主动显示。
如果我们想看,就要主动让它显示:show warnings;
只创建不存在的数据表
create table if not exit tablename;
- 1
重复创建表是会报错的。
15、创建临时数据表
临时数据表会在与服务器断开连接时自动销毁。
创建方式:create temporary table tablename;
临时表的表名可以和已存在的表相同,不过在临时表存在期间那个永久表会被隐藏。
不过无法创建两个同名的临时表。
什么时候使用临时表:比如说要做实验的时候,你导入一个外部文件,但是你又不知道里面数据安全不安全,是吧。
16、从其他表中创建新表
1、create table tablename like othertable; 将另一个表的数据复制到新表中。
2、create table tablename select ...以查询结果建表。
17、删除数据表
1、删除一张表:drop table tablename;
2、删除多张表:自己想
18、为数据表编制索引
1.存储引的索引特性
MySQL提供了多种灵活的索引创建办法,如下所示。
你可以为单个数据列编制索引,也可以为多个数据列构造复合索引。
索引可以只包含独-无二的值,也可以包含重复的值。
你可以为同一个数据表创建多个索引并分别利用它们来优化基于不同数据列的查询。
对于ENUM和SET以外的字符串数据类型,可以只为数据列的-一个前缎创建索引,也就是为对最左边的n个字符(对二进制字符串类型来说就是最左边的n个字节)创建索引。(对于BLOB和TEXT数据列,你只有在指定了前缀长度的情况下才能创建-一个索引。)如果数据列在前缀长度范围内具有足够的独一无二性,查询性能通常不会受到影响,而是会得到改善:为数据列前缀而不是整个数据列编索引可以让索引本身更小并加快访问速度。
2.创建索引
MySQL可以创建好几种索引,如下所示。
唯一索引。这种索引不允许索引项本身出现重复的值。对只涉及-一个数据列的素引来说,这意味着该数据列不能包含重复的值。对涉及多个数据列的索引(复合索引)来说,这意味着那几个数据列的值的组合在整个数据表的范围内不能出现重复。
普通(非唯一)索引。这种索引的优点(从另一方面看是缺点) 是允许索引值出现重复。0 FULLTEXT索引。用来进行全文检索。这种索引只适用于MyISAM数据表。如果你想了解更多信息,请参阅2.15节。
SPATIAL索引。这种索引只适用于MyISAM数据表和空间(spatial) 数据类型,对这种数据类型的描述见第3章。(对于其他支持空间数据类型的存储引擎,你可以创建非SPATTAL索引.)
HASH索引。这是MEMORY数据表的默认索引类型,但你可以改用BTREE索引来代替这个默认索引。
alter table tablename add index index_name(index_columns);
- 1
tablename:要加索引的数据表
index_name:索引名
index_columns:要加索引的单列或多列,如果是多列要用逗号隔开。
- 如果是一个primary key索引或spatial索引,则带索引的列必须为not null。
- 每个数据表只能有一个primary key。
索引干嘛用?开头那三篇里面讲的详细了。
19、删除索引
drop index index_name on tablename;
- 1
20、Alter 改变数据表的结构
alter语法:alter table tablename action ...;
示例:
改变数提列的数据类型。如果想改变某个数据列的数据类型,可以使用CHANGE或MODIFY子句。假设mytbl数据表里的某个数据列的数据类型是SMALLIT UNSIGNED,你想把它改成MEDIUMITUNSIGNEID。下面两条命令都可以达到目的:
ALTER TABLE mytbl MODIFY i MEDIUMINT UNSIGNED;
ALTER TABLB mytbl CHANGB i i MEDIUMINT UNSIGNED;
- 1
- 2
- 3
为什么在使用CHANGE子句时需要写两遍数据列的名字呢?因为CHANGE子句能够(而MODIFY子句不能)做到的事情是在改变其数据类型的同时重新命名一个数据列。如果想在改变其数据类型的同时把数据列i重新命名为k,你可以这样做:
ALTER TABLE mytbl CHANGE i k MEDIUMINT UNSIGNED;
- 1
在CHANGE子句里,需要先给出想改动的数据列的名字,然后给出它的新名字和新定义。因此,即使不想重新命名那个数据列,也需要把它的名字写两遍。
如果只想改变数据列的名字,不改变它的数据类型,先写出CHANGE o1d name new_ name、再写出数据列的当前定义即可。
重新命名-个数据表。用RENAME子句给数据表起-个新名字:
ALTER TABLE tbl name RENAME TO new_ tbl_ name;
- 1
另一个办法是使用RENAMB TABLE 语句来重新命名数据表。下面是它的语法:
RENAME TABLE old name TO new_ name;
- 1
ALTER TABLE语句每次只能重新命名一个数据表,而RENAME TABLE语句可以一次重新命名多个数据表。比如说,你可以像下面这样交换两个数据表的名字:
RENAME TABLE t1 TO tmp, t2 TO t1, tmp TO t2;
- 1
如果在重新命名个数据表时在它的名字前面加上了数据库名前级,就可以把它从一个数据库移动到另一个数据库。下面两条语句都可以把数据表t从sampdb数据库移到test数据库去:
ALTER TABLE sampdb.t RENAME TO test. t;
RENAME TABLE sampdb.t TO test.t:
- 1
- 2
- 3
不能把一个数据表重新命名为一个已有的名字。
如果重新命名的某个MyISAM数据表是某个MERGE数据表的成员,你必须重新定义那个MERGE数据表,让它使用那个MyISAM数据表的新名字。
21、获取数据库里的元数据
前面讲的杂乱无章,整理一下:
show databases;
show create database sampdb; //建库语句查询
show tables;
show create table score; //建表语句查询
show columns from student;
show index from student;
show table status; //查看数据表的描述性信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
22、使用视图
视图是一种虚表,它是从数据表或其他视图中抽取出数据形成的临时表,用来提供查看数据的另一种方式,可以简化应用程序。
创建视图:
create view view_name as
select column1,column2... from table_name;
- 1
- 2
查询视图的方法和效果与普通数据表一样,使用视图时,你只能引用当前视图中存在的数据列。
视图可以用来自动完成必要的数学运算,我们可以把视图运算放在一个视图定义里运行。
23、事务处理
事务是作为一个不可分割的逻辑单元而被执行的一组SQL语句,如有必要,它们的执行效果可以被撤销。
并非所有的语句每次都能被执行成功。
事务的处理是通过提交和回滚功能实现的。如果某个事务里的语句都执行完成了,提交该事务将把那些执行效果永久的记录到数据库里。如果在事务过程中发生错误,回滚该事务将把发生错误之前已经执行的语句全部撤销。
事务的另一个用途就是确保某个操作所设计的数据行在你正在使用它们的时候不会被其他客户所修改。
MySQL在执行每一条SQL语句时都会自动的对该语句所设计的资源进行锁定以避免个语句之间相互干扰,但这仍不足以保证每一个数据库操作总是能得到预期的结果。要知道,有的数据库操作需要多条语句才能完成,而在此期间,不同的客户就有可能互相干扰。
通过把多条语句组合成一个执行单元,事务机制可以防止多客户环境里可能发生的并发问题。
使用事务处理为数据库提供了强有力的保证,但这需要增加CPU、内存和硬盘空间等方面的开销作为代价。
想要使用事务,就必须选择一个支持事务的存储引擎,如innoDB。


要注意,有些语句时不能成为事务的一部分的,所以在事务中出现了这些语句,系统会自动将事务提交,如:
ALTER TABLE
CREATEINDEX
DROP DATABASE
DROP INDEX
DROP TABLE
LOCK TABLES
RENAME TABLE
SET autocommit = 1 (if not already set to 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
每个版本的情况略有偏差,具体还得看官方文档。
24、使用事务保存点
MySQL使你能够对一个事务进行部分回滚,这就需要你在事务过程中使用savepoint语句设置一些称为”保存点“的标记。在后续的事务里,如果你想回滚到某个特定的保存点,在rollback语句里给出该保存点的位置即可。
有图有真相:

25、外键使用
利用外键(foreign key)关系可以在某个数据表里声明与另一个数据表里的某个索引相关联的索引。还可以把你想施加在数据表上的约束条件放到外键关系里,让系统根据这个关系里的规则来维护数据的引用完整性。比如说,sampdb 数据库里的score数据表包含-一个student_ id 数据列,我们要用它把score数据表里的考试成绩与student数据表里的学生联系在-起。当我们在第1章里创建这些数据表时,我们在它们之间建立了一些明确的关系,其中之一-是把score. student_ id数据列定义为student. student_ id数据列的-一个外键。这可以确保只有那些在studnt数据表里存在student_ id值的数据行才能被插人到score数据表里。换句话说,这个外键可以确保不会出现为一名并不存在的学生输入了成绩的错误。
外键不仅在数据行的插人操作中很有用,在删除和更新操作中也很有用。比如说,我们可以建立这样-一个约束条件:在把某个学生从student数据表里删除时,score 数据表里与这个学生有关的所有数据行也将自动被删除。这被称为级联删除(cascaded delete), 因为删除操作的效果就像瀑布(cascade)那样从一一个数据表“流淌”到另外-一个数据表。级联更新也是可能的。比如说,如果利用瀑布式更新在student数据表里改变了某个学生的student_ id, score 数据表里与这个学生相对应的所有数据行的这个值也应该发生相应的改变。
外键可以帮我们维护数据的一致性,它们用起来也很方便。如果不使用外键,就必须由你来负责保证数据表之间的依赖关系和维护它们的致性,而这意味着你的应用程序必须增加一-些必要的代码。在某些情况下,这只需要你额外发出几条DELETE语句以确保当你删除某个数据表里的数据行时,其他数据表里与之相对应的数据行也将随之一起被删除。但额外工作毕竟是额外工作,而且既然数据库引擎能够替你进行数据一致性检查,为什么不让它干呢?要是你的数据表有非常复杂的关系,由你在你的应用程序里通过代码去检查这些依赖关系就会变得很麻烦,而数据库系统提供的自动检查能力往往要比你本人考虑得更周全和更细致,也更简明实用。
示例:

26、数值类型
数值类别
MySQL能够识别和使用的数据值包括数值、字符串值、日期/时间值、坐标值和空值(NULL)。
特殊字符串处理
SQL标准对于字符串的两端规定为单引号。
MySQL可以识别出字符串中的转义序列,这就很尴尬:

那怎么办?
首先,这表里的转义序列是区分大小写的。
从上面这个表来看,可以使用\来转义\。
也可以使用转义字符来转义字符串中的单引号和双引号。
当然,处理字符串中引号还有别的办法:
1、如果引号与字符串两端引号相同,双写该引号,如:
‘I can ’ ’ t.’
“He said,” “I can 't.” " "
2、用不同引号把该字符串包起来,如:
’ “I can’t .” ’
" He said,'I can ‘t.’ "
27、MySQL如何处理非法数据
在默认的情况下,MySQL按照以下规则处理“数据越界”和其他非正常数据:
-
对于数值数据列或TIME数据列,超出合法范围的值将被截短到最近的取值范围边界,然后把结果值存人数据库。
-
对于字符串数据列(不包括ENUM和SET),太长的字符串将被截短到数据列的最大长度。
-
对ENUM和SET数据列的赋值操作取决于在数据列定义里给出的合法取值列表。如果你赋值给某个ENUM数据列的值不是合法成员,MySQL 将把“出错”成员(也就是与零值成员相对应的空字符串)赋值给该数据列。如果你赋值给某个SET数据列的值包含非合法子字符串,MySQL将删除那些子字符串而只把剩下来的东西赋值给该数据列。
-
对于日期和时间数据列,非法值将被转换为该类型的“零值”。
-
如果在执行INSERT、REPLACE、 UPDATE、 LOAD DATA和ALTER TABLE等语句时发生上述转换,MySQL将生成一条警告消息。 在这几种语句执行完毕之后,你可以用SHOW WARNINGS语句去查看警告消息的内容。
-
如果需要在插人或更新数据时进行更严格的检查,可以启用以下两种SQL模式之- :
mysql> SET sql_ mode = ' STRICT_ALL_TABLES';
mysql> SET sql_ mode = ' STRICT_TRANS_TABLES';
- 1
- 2
28、操作符
算术操作符

逻辑运算符

比较运算符

29、复合语句与语句分隔符
走到这一步了,也该知道MySQL的执行,如果没什么特殊说明都是一个分号一句的,不过有些语句需要形成一个语句块,就像函数的那个{}一样。
在MySQL语句中,也有这样的分隔符:
- 复合语句由begin开头,由end结尾。
- 使用delimiter命令把mysql程序的语句分隔符定义为另一个字符或字符串,它必须是在存储例程的定义里没有出现过的。这样-来, mysql程序就不会把分号解释为语句终止符了,它将把整个对象定义作为一条语 句传递给服务器。在定义完存储程序之后,可以把mysql程序的语句终止符重新定义为分号。下面的例子在定义一一个存储过程时把mysq1程序的默认分隔符临时改变为$,然后在恢复了mysql程序的默认分隔符之后执行了那个存储过程:

30、触发器
触发器是与特定数据表相关联的存储过程,当相应的数据表被INSERT、DELETE 或UPDATE语句修改时,触发器将自动执行。触发器可以被设置成在这几种语句处理每个数据行之前或之后触发。触发器的定义包括一-条将在触发器被触发时执行的语句。
触发器要用CREATE TRIGGER语句来创建。在触发器的定义里需要表明它将由哪种语句(INSERT、UPDATE或DELETE)触发,是在数据行被修改之前还是之后被触发。触发器创建语句的基本语法如下所示:
CREATE TRIGGER trigger_ name # the trigger name
{BEFORE | AFTER} # when the trigger activates
{INSERT | UPDATE | DELETE } # what statement activates it
ON tbl_ name # the associated table
FOR EACH ROW trigger_ stmt; # what the trigger does
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
来个栗子看看:
CREATE TABLE t (percent INT, dt DATETIME);
- 1
delimiter $
CREATE TRIGGER bi_t BEFORE INSERT ON t
FOR EACH ROW BEGIN
SET NEW.dt = CURRENT TIMESTAMP;IF NEW.percent < 0 THEN
SET NEW.percent= 0;
ELSEIF NEW.percent> 100 THEN
SET NEW.percent = 100;
END IF;
ENDS
mysql> delimiter ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
关于存储程序就弄一个触发器吧。
31、索引的使用
索引为什么能提高查询效率?
查找算法了解多少?
树、B树、红黑时、哈希表了解多少?了解的话自然就知道了。不了解的话,就去了解吧哈哈哈,辣个是基础,不了解怎么行。
用来加快查询的技术有很多,其中最重要的是索引。通常,能够造成查询速度最大差异的是索引的正确使用。很多时候,当查询速度很慢时,添加上索引后就能迅速解决问题。但情况也不总是这样,因为优化并不总是- -件简单的事情。然而,在许多情况下,假如你不使用索引,那么试图通过其他途径来提高性能则纯粹是浪费时间。你应该首先使用索引来最大程度地改进性能,然后再看是否还有其他技术可以采用。
挑选索引
创建、删除索引第二篇说过了,现在学习一下如何 “因时制宜” 地挑选索引
尽量为用来搜索、分类或分组的数据列编制索引,不要为用来输出的数据列编制索引。
你懂得。
尽量为短小的值建立索引,或者说,建立索引的值,要尽量短小。
你懂得。
要是不懂那我讲得清楚点:
1、索引是不是也要匹配?
2、索引是不是也要一张索引表来存储?
3、调用索引是是不是要调用索引表?
为字符串的前缀设置索引
利用慢查询日志找出拖慢进度的SQL语句

具体看上面三节课的笔记中的第二节。
32、MySQL的查询优化程序
当你发出一个选取数据行的查询语句时,MySQL就会分析它,并考虑是否可以对它进行优化以加快查询。
那么,我们要如何来配合这个查询优化程序的工作呢?
33、使用explain 语句来验证优化器操作
explain语句放在select之前,

34、其他话
尽量使用数据类型相同的数据列进行比较
对带有索引的数据进行比较时,如果它们的数据类型相同,查询性能就会高一些,如果它们的数据类型不同,查询性能就会低一些。
尽量不要在like模式的开始位置使用通配符
避免过多使用MySQL的自动类型转换功能
emmm,难搞哦。。。

35、C++语言使用MySQL
我也是个新手,所以这个整理的可能会比较杂,蛮看,等入门之后在拿个小项目练一下就熟悉了。
1、Linux下的MySQL环境搭建
使用命令(安装mysql):
sudo apt-get install mysql-server
sudo apt-get install mysql-client
sudo apt-get install libmysqlclient-dev
sudo apt-get install emma
- 1
- 2
- 3
- 4
- 5
- 6
这要安不上,度娘在边上。
2、头文件
//Linux下
//mysqltest.cpp 代码如下:
#include <stdio.h>
//确保在/usr/include/mysql下有mysql.h文件
#include "mysql/mysql.h"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
//windows下
#include <WinSock2.h> // 进行网络编程需要winsock2.h
#include <mysql.h>
#pragma comment(lib, “libmysql.lib”)
- 1
- 2
- 3
- 4
- 5
- 6
后面的示例代码是一份windows下的,不过建议大家熟悉之后改成Linux版本的,毕竟咱这学C++的嘛,跟Linux感情还是好一点。
3、初见庐山真面目
/*连接句柄 整个MYSQL开发的核心*/
MYSQL * mysql;
/*初始化*/
MYSQL *mysql_init(MYSQL *mysql);
/*设置连接选项*/
int mysql_options(MYSQL *mysql, enum mysql_option option, const char *arg);
/*打开连接*/
MYSQL *mysql_real_connect(MYSQL *mysql, const char *host, const char *user, const char *passwd, const char *db,
unsigned int port, const char *unix_socket, unsigned long client_flag);
/*执行SQL语句*/
int mysql_real_query(MYSQL *mysql, const char *query, unsigned long length);
/*如果SQL语句是C风格字符串,可以直接用下面的函数*/
int mysql_query(MYSQL *mysql, const char *query);
/*SQL语句一般只能是一条语句,如果你想在一个函数调用中执行多个SQL语句,需要以;隔开,并且设置在打开连接时设置属性*/
CLIENT_MULTI_STATEMENTS
/*或者对已经打开的连接进行以下函数调用设置,其中mysql为MYSQL的指针*/
mysql_set_server_option(mysql,MYSQL_OPTION_MULTI_STATEMENTS_ON);
/*如果执行的是一个有返回结果的语句,可以用下列函数获取结果*/
MYSQL_RES *mysql_use_result(MYSQL *mysql);
MYSQL_RES *mysql_store_result(MYSQL *mysql);
/*其中前一个函数只是初始化MYSQL_RES结构体,并不真正从服务器获取结果,后一个函数直接将全部数据读取到客户端*/
/*MYSQL_RES结构体可以通过以下函数获得数据*/
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);
/*该函数返回的MYSQL_ROW类型实际为 char** 类型,通过下标操作可以取得每一列的值*/
/*可以通过以下函数获得结果集的列数*/
unsigned int mysql_field_count(MYSQL *mysql);
unsigned int mysql_num_fields(MYSQL_RES *result);
/*获得结果集的行数*/
my_ulonglong mysql_num_rows(MYSQL_RES *result);
/*使用完结果集后一定要记得释放*/
void mysql_free_result(MYSQL_RES *result);
/*如果执行的SQL语句是无返回结果的,比如DELETE INSERT等,可以使用以下函数获取影响行数*/
my_ulonglong mysql_affected_rows(MYSQL *mysql);
/*最后使用完连接后需要释放*/
void mysql_close(MYSQL *mysql);
/*错误处理*/
/*MYSQL的函数基本都遵循C语言的编程习惯,当返回值为整数时,0代表成功,非0代表失败,当返回指针时,NULL代表失败*/
/*如果函数执行失败,你可以通过下列函数获得信息*/
unsigned int mysql_errno(MYSQL *mysql);//错误代号
const char *mysql_error(MYSQL *mysql);//英文错误信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
4、拨开迷雾,看下一层迷雾
①调用mysql_real_connect函数连接Mysql数据库。
mysql_real_connect函数的原型如下:
MYSQL * STDCALL mysql_real_connect(MYSQL *mysql, const char *host,const char *user,const char *passwd,const char *db,unsigned int port,const char *unix_socket,unsigned long clientflag);
- 1
参数释义:
mysql:前面定义的MYSQL变量;
host:MYSQL服务器的地址;
user:登录用户名;
passwd:登录密码;
db:要连接的数据库;
port:MYSQL服务器的TCP服务端口;
unix_socket:unix连接方式,为NULL时表示不使用socket或管道机制;
clientflag:Mysql运行为ODBC数据库的标记,一般取0。
连接失败时该函数返回0。
②调用mysql_real_query函数进行数据库查询。
mysql_real_query函数的原型如下:
int STDCALL mysql_real_query(MYSQL *mysql, const char *q, unsigned long length);
- 1
参数释义:
mysql:前面定义的MYSQL变量;
q:SQL查询语句;
length:查询语句的长度。
查询成功则该函数返回0。
③通过调用mysql_store_result或mysql_use_result函数返回的MYSQL_RES变量获取查询结果数据。
两个函数的原型分别为:
MYSQL_RES * STDCALL mysql_store_result(MYSQL *mysql);
MYSQL_RES * STDCALL mysql_use_result(MYSQL *mysql);
- 1
- 2
- 3
这两个函数分别代表了获取查询结果的两种方式。
第一种,调用mysql_store_result函数将从Mysql服务器查询的所有数据都存储到客户端,然后读取;
第二种,调用mysql_use_result初始化检索,以便于后面一行一行的读取结果集,而它本身并没有从服务器读取任何数据,这种方式较之第一种速度更快且所需内存更少,但它会绑定服务器,阻止其他线程更新任何表,而且必须重复执行mysql_fetch_row读取数据,直至返回NULL,否则未读取的行会在下一次查询时作为结果的一部分返回。
故经常我们使用mysql_store_result。
④调用mysql_fetch_row函数读取结果集数据。
上述两种方式最后都是重复调用mysql_fetch_row函数读取数据。mysql_fetch_row函数的原型如下:
MYSQL_ROW STDCALL mysql_fetch_row(MYSQL_RES *result);
- 1
参数释义:
result就是mysql_store_result或mysql_use_result的返回值。
该函数返回MYSQL_ROW型的变量,即字符串数组,假设为row,则row[i]为第i个字段的值。当到结果集尾部时,此函数返回NULL。
⑤结果集用完后,调用mysql_free_result函数释放结果集,以防内存泄露。
mysql_free_result函数的原型如下:
void STDCALL mysql_free_result(MYSQL_RES *result);
- 1
⑥不再查询Mysql数据库时,调用mysql_close函数关闭数据库连接。
void STDCALL mysql_close(MYSQL *sock);
- 1
5、看个实例融会贯通一下
就是个实例,也不是我写的,我也是刚入门。
#include <WinSock2.h> #include <mysql.h>
#include <iostream> #pragma comment(lib, “libmysql.lib”) using namespace std; int main(){ MYSQL mysql; MYSQL_RES *res; MYSQL_ROW row; // 初始化MYSQL变量 mysql_init(&mysql); // 连接Mysql服务器,本例使用本机作为服务器。访问的数据库名称为“msyql”,参数中的user为你的登录用户名,***为登录密码,需要根据你的实际用户进行设置 if (!mysql_real_connect(&mysql, “127.0.0.1”, “user”, “123”, “mysql”, 3306, 0, 0)){ cout << “mysql_real_connect failure!” << endl; return 0; } // 查询mysql数据库中的user表 if (mysql_real_query(&mysql, “select * from user”, (unsigned long)strlen(“select * from user”))) { cout << “mysql_real_query failure!” << endl; return 0; } // 存储结果集 res = mysql_store_result(&mysql); if (NULL == res) { cout << “mysql_store_result failure!” << endl; return 0; } // 重复读取行,并输出第一个字段的值,直到row为NULL while (row = mysql_fetch_row(res)) { cout << row[0] << endl; } // 释放结果集 mysql_free_result(res); // 关闭Mysql连接 mysql_close(&mysql); return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
本篇也是本次入门之旅的最后一篇,之后更要多加练习
码字不易,确定不来个三连加关注吗?一周后,你会惊奇的发现,成了粉丝可见了。。。
顺手收藏一波好习惯,划着划着,可就找不到了。


文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/108858689

- 点赞
- 收藏
- 关注作者
评论(0)