MySQL题集

文章目录
题一(组合两个表)
表1: Person
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+-------------+---------+
PersonId 是上表主键
> 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/combine-two-tables
> 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
表2: Address
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+-------------+---------+
AddressId 是上表主键
> 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/combine-two-tables
> 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
FirstName, LastName, City, State
- 1
题解
我没题解,我菜。
方法:使用 outer join
因为表 Address 中的 personId 是表 Person 的外关键字,所以我们可以连接这两个表来获取一个人的地址信息。
考虑到可能不是每个人都有地址信息,我们应该使用 outer join 而不是默认的 inner join。
select FirstName, LastName, City, State
from Person left join Address
on Person.PersonId = Address.PersonId
;
> 作者:LeetCode
> 链接:https://leetcode-cn.com/problems/combine-two-tables/solution/zu-he-liang-ge-biao-by-leetcode/
> 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意:如果没有某个人的地址信息,使用 where 子句过滤记录将失败,因为它不会显示姓名信息。
收获
题解没有,要是连收获都没有那不是白忙活一场。
多表联结
涉及到多表查询,需要用到联结。
多表的联结又分为以下几种类型:
1)左联结(left join),联结结果保留左表的全部数据
2)右联结(right join),联结结果保留右表的全部数据
3)内联结(inner join),取两表的公共数据
- 1
- 2
- 3
- 4
- 5
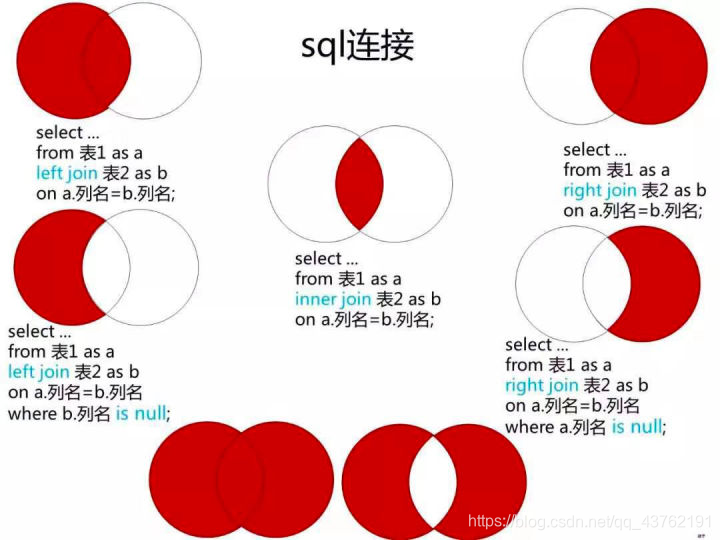
底下那俩,各位自行实现,反正我是实现了。
题二:第二高的薪水
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
> 来源:力扣(LeetCode)
> 链接:https://leetcode-cn.com/problems/second-highest-salary
> 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
题解
方法:使用 IFNULL 和 LIMIT 子句
解决 “NULL” 问题的另一种方法是使用 “IFNULL” 函数,如下所示。
SELECT IFNULL( (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1 OFFSET 1), NULL) AS SecondHighestSalary
> 作者:LeetCode
> 链接:https://leetcode-cn.com/problems/second-highest-salary/solution/di-er-gao-de-xin-shui-by-leetcode/
> 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
收获
IFNULL(expression, alt_value)
如果第一个参数的表达式 expression 为 NULL,则返回第二个参数的备用值(此题中是返回null)。
expression是table的时候要加括号
distinct:
去重一样的Salary
limit:限返回的个数
offset:跳过几个
limit 1 offset 1:返回一个结果,跳过一个
例如返回第三高就是:limit 1 offset 2
题三:第N高的薪水
可以说是对上一题的巩固拓展吧。
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
- 1
- 2
- 3
- 4
- 5
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/nth-highest-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN SET n = N-1;
RETURN ( # Write your MySQL query statement below. select IFNULL( ( select DISTINCT Salary from Employee order by Salary DESC limit 1 offset n ), NULL )
);
END
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
收获
怎么说呢,昨天刷了一道这样的题,没记太清楚,今天再做一题,把格式记住了。
leetcode两题选手 - MySQL类题目(一)
这里不多做赘述。
题四:分数排名
编写一个 SQL 查询来实现分数排名。
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
重要提示:对于 MySQL 解决方案,如果要转义用作列名的保留字,可以在关键字之前和之后使用撇号。例如 Rank
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/rank-scores
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
select score, dense_rank() over(order by Score desc) as Ranking
from Scores;
- 1
- 2
- 3

我就想说这不是为难我这个新手吗?这是要保留两位数?这也没说啊。。。
解题思路
排名是数据库中的一个经典题目,实际上又根据排名的具体细节可分为3种场景:
连续排名,例如薪水3000、2000、2000、1000排名结果为1-2-3-4,体现同薪不同名,排名类似于编号
同薪同名但总排名不连续,例如同样的薪水分布,排名结果为1-2-2-4
同薪同名且总排名连续,同样的薪水排名结果为1-2-2-3
不同的应用场景可能需要不同的排名结果,也意味着不同的查询策略。
值得一提的是:在Oracle等数据库中有窗口函数,可非常容易实现这些需求,而MySQL直到8.0版本也引入相关函数。
row_number(): 同薪不同名,相当于行号,例如3000、2000、2000、1000排名后为1、2、3、4
rank(): 同薪同名,有跳级,例如3000、2000、2000、1000排名后为1、2、2、4
dense_rank(): 同薪同名,无跳级,例如3000、2000、2000、1000排名后为1、2、2、3
ntile(): 分桶排名,即首先按桶的个数分出第一二三桶,然后各桶内从1排名,实际不是很常用
- 1
- 2
- 3
- 4
显然,本题是要用第三个函数。
另外这三个函数必须要要与其搭档over()配套使用,over()中的参数常见的有两个,分别是
partition by,按某字段切分
order by,与常规order by用法一致,也区分ASC(默认)和DESC,因为排名总得有个依据
- 1
- 2
收获
涉及到排名的问题,都可以使用窗口函数来解决。记住rank, dense_rank, row_number排名的区别。
MySQL窗口函数
题五:连续出现的数字
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
+----+-----+
| Id | Num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
- 1
- 2
- 3
- 4
- 5
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/consecutive-numbers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
这题一看我就没有题解了。。。
SELECT DISTINCT l1.Num AS ConsecutiveNums
FROM Logs l1, Logs l2, Logs l3
WHERE l1.Id = l2.Id - 1 AND l2.Id = l3.Id - 1 AND l1.Num = l2.Num AND l2.Num = l3.Num
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
题六:超过经理收入的员工
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
+----------+
| Employee |
+----------+
| Joe |
+----------+
- 1
- 2
- 3
- 4
- 5
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/employees-earning-more-than-their-managers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
这题就友好多了,这题我会写。
就分两张表,然后比对嘛,不过格式上还有那么点生疏。
select a.Name AS 'Employee'
FROM Employee AS a, Employee AS b
WHERE a.ManagerId = b.Id and a.Salary>b.Salary
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
收获
听说这个叫自连接:
运用到自连接
1、先把这张表看成员工表 e
2、再把这张表看成管理者表 m
3、用e表的ID去连接m表的ID,关联两张表
4、设定where条件即可
select e.Name as Employee
from Employee e
join Employee m on e.managerid=m.id
where e.salary>m.salary;
> 作者:xiao-bai-bai-o
> 链接:https://leetcode-cn.com/problems/employees-earning-more-than-their-managers/solution/zi-lian-jie-by-xiao-bai-bai-o/
> 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
题七:从不订购的客户
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+
| Id | Name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Orders 表:
+----+------------+
| Id | CustomerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
- 1
- 2
- 3
- 4
- 5
- 6
例如给定上述表格,你的查询应返回:
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/customers-who-never-order
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
要不怎么说简单题做的有感觉呢,这两题我还是有思路的。
方法:使用子查询和 NOT IN 子句
如果我们有一份曾经订购过的客户名单,就很容易知道谁从未订购过。
我们可以使用下面的代码来获得这样的列表。
select customerid from orders;
- 1
然后,我们可以使用 NOT IN 查询不在此列表中的客户。
select Name as 'Customers'
from Customers
where Customers.Id not in( select CustomerId from orders
)
;
- 1
- 2
- 3
- 4
- 5
- 6
收获
还有的题解是使用左连接的:也挺好
将两张表join一下
找到join后顾客没有购物的
select A.Name as Customers
from Customers A left join Orders B
on A.Id = B.CustomerId
where B.Id is null
- 1
- 2
- 3
- 4
题八:查找重复的电子邮箱
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
根据以上输入,你的查询应返回以下结果:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
- 1
- 2
- 3
- 4
- 5
说明:所有电子邮箱都是小写字母。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/duplicate-emails
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解:
select Email
from Person
group by Email
having count(Email)>1
;
- 1
- 2
- 3
- 4
- 5
收获
方法:使用 GROUP BY 和 HAVING 条件
向 GROUP BY 添加条件的一种更常用的方法是使用 HAVING 子句,该子句更为简单高效。
题九:各部门工资最高的员工
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
+----+-------+--------+--------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Department 表包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
- 1
- 2
- 3
- 4
- 5
- 6
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
- 1
- 2
- 3
- 4
- 5
- 6
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/department-highest-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
思路是相同的,奈何写出来一直编译不过。。。
真让人无话可说。。。
SELECT Department.name AS 'Department', Employee.name AS 'Employee', Salary
FROM Employee JOIN Department ON Employee.DepartmentId = Department.Id
WHERE (Employee.DepartmentId , Salary) IN ( SELECT DepartmentId, MAX(Salary) FROM Employee GROUP BY DepartmentId
)
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
收获
解题方法
方法:使用 JOIN 和 IN 语句
因为 Employee 表包含 Salary 和 DepartmentId 字段,我们可以以此在部门内查询最高工资。
SELECT DepartmentId, MAX(Salary)
FROM Employee
GROUP BY DepartmentId;
- 1
- 2
- 3
- 4
- 5
注意:有可能有多个员工同时拥有最高工资,所以最好在这个查询中不包含雇员名字的信息。
| DepartmentId | MAX(Salary) |
|--------------|-------------|
| 1 | 90000 |
| 2 | 80000 |
- 1
- 2
- 3
- 4
然后,我们可以把表 Employee 和 Department 连接,再在这张临时表里用 IN 语句查询部门名字和工资的关系。
作者:LeetCode
链接:https://leetcode-cn.com/problems/department-highest-salary/solution/bu-men-gong-zi-zui-gao-de-yuan-gong-by-leetcode/
来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题十:各部门工资前三高的员工
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Department 表包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
- 1
- 2
- 3
- 4
- 5
- 6
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/department-top-three-salaries
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
解题方法:
使用 JOIN 和子查询
公司里前 3 高的薪水意味着有不超过 3 个工资比这些值大。
select e1.Name as 'Employee', e1.Salary
from Employee e1
where 3 >
( select count(distinct e2.Salary) from Employee e2 where e2.Salary > e1.Salary
)
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个代码里,我们统计了有多少人的工资比 e1.Salary 高,所以样例的输出应该如下所示。
| Employee | Salary |
|----------|--------|
| Henry | 80000 |
| Max | 90000 |
| Randy | 85000 |
- 1
- 2
- 3
- 4
- 5
然后,我们需要把表 Employee 和表 Department 连接来获得部门信息。
SELECT d.Name AS 'Department', e1.Name AS 'Employee', e1.Salary
FROM Employee e1 JOIN Department d ON e1.DepartmentId = d.Id
WHERE 3 > (SELECT COUNT(DISTINCT e2.Salary) FROM Employee e2 WHERE e2.Salary > e1.Salary AND e1.DepartmentId = e2.DepartmentId )
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
收获
我觉得我得去系统的学一下SQL语句了。。。
其实我的想法是这样的:dense_rank()
奈何我写出来的一直编译不过啊,我也很苦恼啊。。。
题十一:删除重复的电子邮箱
编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
+----+------------------+
| Id | Email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person 表应返回以下几行:
+----+------------------+
| Id | Email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
提示:
执行 SQL 之后,输出是整个 Person 表。
使用 delete 语句。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/delete-duplicate-emails
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
delete p1 from
Person p1,Person p2
where( p1.Email = p2.Email and p1.Id>p2.Id
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
终于有能自己写的题目了。
收获
使用 DELETE 和 WHERE 子句
我们可以使用以下代码,将此表与它自身在电子邮箱列中连接起来。
然后我们需要找到其他记录中具有相同电子邮件地址的更大 ID。所以我们可以像这样给 WHERE 子句添加一个新的条件。
因为我们已经得到了要删除的记录,所以我们最终可以将该语句更改为 DELETE。
其实重要的是,我学会了这种写法:
delete p1 from
Person p1,Person p2
- 1
- 2
在实际生产中,面对千万上亿级别的数据,连接的效率往往最高,因为用到索引的概率较高。
题十二:上升的温度
给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
例如,根据上述给定的 Weather 表格,返回如下 Id:
+----+
| Id |
+----+
| 2 |
| 4 |
+----+
- 1
- 2
- 3
- 4
- 5
- 6
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/rising-temperature
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
SELECT w2.Id
FROM Weather w1, Weather w2
WHERE DATEDIFF(w2.RecordDate, w1.RecordDate) = 1
AND w1.Temperature < w2.Temperature
- 1
- 2
- 3
- 4
收获
其实思路很明确,就是输在了那个日期判断的函数上,我的函数是这样的:
-- select W1.Id from
-- Weather W1,Weather W2
-- where(
-- W1.RecordDate = W2.RecordDate+1
-- and
-- W1.Temperature > W2.Temperature
-- );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
题十三:最大的国家
这里有张 World 表
+-----------------+------------+------------+--------------+---------------+
| name | continent | area | population | gdp |
+-----------------+------------+------------+--------------+---------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
| Albania | Europe | 28748 | 2831741 | 12960000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000 |
| Andorra | Europe | 468 | 78115 | 3712000 |
| Angola | Africa | 1246700 | 20609294 | 100990000 |
+-----------------+------------+------------+--------------+---------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果一个国家的面积超过300万平方公里,或者人口超过2500万,那么这个国家就是大国家。
编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
+--------------+-------------+--------------+
| name | population | area |
+--------------+-------------+--------------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
+--------------+-------------+--------------+
- 1
- 2
- 3
- 4
- 5
- 6
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/big-countries
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
这题其实很简单的。
select name,population,area
from World
where population>25000000 or area>3000000;
- 1
- 2
- 3
题十四:超过五名学生的课
有一个courses 表 ,有: student (学生) 和 class (课程)。
请列出所有超过或等于5名学生的课。
例如,表:
+---------+------------+
| student | class |
+---------+------------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
应该输出:
+---------+
| class |
+---------+
| Math |
+---------+
- 1
- 2
- 3
- 4
- 5
Note:
学生在每个课中不应被重复计算。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/classes-more-than-5-students
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
本来也是个简单题,但是吧,遇到了有的学生一个课选几次的情况。
SELECT class
FROM courses
GROUP BY class
HAVING COUNT(DISTINCT student) >= 5
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
收获
方法:使用 GROUP BY 子句和子查询
先统计每门课程的学生数量,再从中选择超过 5 名学生的课程。
使用 GROUP BY 和 COUNT 获得每门课程的学生数量。
SELECT class, COUNT(DISTINCT student)
FROM courses
GROUP BY class
;
- 1
- 2
- 3
- 4
- 5
- 6
注:使用 DISTINCT 防止在同一门课中学生被重复计算。
| class | COUNT(student) |
|----------|----------------|
| Biology | 1 |
| Computer | 1 |
| English | 1 |
| Math | 6 |
- 1
- 2
- 3
- 4
- 5
- 6
使用上面查询结果的临时表进行子查询,筛选学生数量超过 5 的课程。
SELECT class
FROM (SELECT class, COUNT(DISTINCT student) AS num FROM courses GROUP BY class) AS temp_table
WHERE num >= 5
;
> 作者:LeetCode
> 链接:https://leetcode-cn.com/problems/classes-more-than-5-students/solution/chao-guo-5ming-xue-sheng-de-ke-by-leetcode/
> 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
题十五:有趣的电影
某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。
作为该电影院的信息部主管,您需要编写一个 SQL查询,找出所有影片描述为非 boring (不无聊) 的并且 id 为奇数 的影片,结果请按等级 rating 排列。
例如,下表 cinema:
+---------+-----------+--------------+-----------+
| id | movie | description | rating |
+---------+-----------+--------------+-----------+
| 1 | War | great 3D | 8.9 |
| 2 | Science | fiction | 8.5 |
| 3 | irish | boring | 6.2 |
| 4 | Ice song | Fantacy | 8.6 |
| 5 | House card| Interesting| 9.1 |
+---------+-----------+--------------+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
对于上面的例子,则正确的输出是为:
+---------+-----------+--------------+-----------+
| id | movie | description | rating |
+---------+-----------+--------------+-----------+
| 5 | House card| Interesting| 9.1 |
| 1 | War | great 3D | 8.9 |
+---------+-----------+--------------+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/not-boring-movies 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
- 1
- 2
题解
简单题
select * from cinema
where id%2=1 and description!='boring'
order by rating desc;
- 1
- 2
- 3
题二:换座位
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的,小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
示例:
+---------+---------+
| id | student |
+---------+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+---------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
假如数据输入的是上表,则输出结果如下:
+---------+---------+
| id | student |
+---------+---------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+---------+---------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/exchange-seats
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解
SELECT (CASE WHEN MOD(id, 2) != 0 AND counts != id THEN id + 1 WHEN MOD(id, 2) != 0 AND counts = id THEN id ELSE id - 1 END) AS id, student
FROM seat, (SELECT COUNT(*) AS counts FROM seat) AS seat_counts
ORDER BY id ASC;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
收获
原来可以用分支语句
方法:使用 CASE
对于所有座位 id 是奇数的学生,修改其 id 为 id+1,如果最后一个座位 id 也是奇数,则最后一个座位 id 不修改。对于所有座位 id 是偶数的学生,修改其 id 为 id-1。
首先查询座位的数量。
SELECT COUNT(*) AS counts
FROM seat
- 1
- 2
- 3
- 4
然后使用 CASE 条件和 MOD 函数修改每个学生的座位 id。
SELECT (CASE WHEN MOD(id, 2) != 0 AND counts != id THEN id + 1 WHEN MOD(id, 2) != 0 AND counts = id THEN id ELSE id - 1 END) AS id, student
FROM seat, (SELECT COUNT(*) AS counts FROM seat) AS seat_counts
ORDER BY id ASC;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
作者:LeetCode
链接:https://leetcode-cn.com/problems/exchange-seats/solution/huan-zuo-wei-by-leetcode/
来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/108864180

- 点赞
- 收藏
- 关注作者
评论(0)