【C++ STL】停下你到处找 hash_map 使用教程的手,看我的就好了


这是我耗时最长的文章,因为资料少,水货又多,我又傻。
没事,前人栽树。我要把这篇写全面,省的你们到处去找。
① 你是windows系统还是Linux系统?
这个问题很重要啊,要区分清楚。如果是Linux,那可以认真看一下,毕竟博主写的也不容易嘛。如果是windows系统,那我建议可以去搜一下unordermap,我接下来也会去写那篇。因为如果在windows系统上跑hash_map/hashtable等一系列非STL标准库的话,它会提示你不让用,直接报错。理由如下:
error C2338: <hash_map> is deprecated and will be REMOVED. Please use <unordered_map>. You can define _SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS to acknowledge that you have received this warning.
#ifndef _SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS
static_assert(false, "<hash_map> is deprecated and will be REMOVED. " "Please use <unordered_map>. You can define " "_SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS " "to acknowledge that you have received this warning.");
#endif /* _SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS */
hash_map是C++非标准STL,因为标准化的推进,hash_map属于非标准容器,未来将要用unordered_map替代之。建议我们使用unorder_map替代hash_map
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个代码在文件hashmap中,如果有兴趣可以自己去找。(故意写错一下就找到了)
如果是在Linux下运行的话,使用的名空间不一样。
using namespace __gnu_cxx;
- 1
还是上面那段代码,不过报错变警告了。
当然,如果你非要在windows下使用的话,也是可以的,改一下上面那一块,可以直接把报错删掉,也可以把报错变警告,只要你能把修改保存进去就行,反正我改完是存不回去了。
② 为什么要使用hash_map
那当然是因为它快啊
hash_map的底层实现是哈希表,通过哈希函数,它的查找效率可以达到常数O(1)。
最好的情况是这样的,最坏的情况也是O(n),这个情况的好坏就取决于哈希函数的优劣了,所以好的哈希函数对于hash_map来说至关重要。
③ 使用代码示例
看你要在什么系统上用咯,如果是windows,命名空间是:using namespace stdext; Linux的命名空间上面有。
后面的内容难度就要拔高了,所以先把代码放这里了,如果不想拔高,可以拿码去测试了。
#include <hash_map>
#include <string>
#include <iostream>
using namespace std;
//define the class
class ClassA{ public: ClassA(int a):c_a(a){} int getvalue()const { return c_a;} void setvalue(int a){c_a;} private: int c_a;
};
//1 define the hash function
struct hash_A{ size_t operator()(const class ClassA & A)const{ // return hash<int>(classA.getvalue()); return A.getvalue(); }
};
//2 define the equal function
struct equal_A{ bool operator()(const class ClassA & a1, const class ClassA & a2)const{ return a1.getvalue() == a2.getvalue(); }
};
int main()
{ hash_map<ClassA, string, hash_A, equal_A> hmap; ClassA a1(12); hmap[a1]="I am 12"; ClassA a2(198877); hmap[a2]="I am 198877"; cout<<hmap[a1]<<endl; cout<<hmap[a2]<<endl; return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
以下内容属于拔高部分
④hash_map原理
hash_map基于hash table(哈希表)。 哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。
其基本原理是:使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数,也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标,hash值)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方,称为桶。
但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。 总的来说,“直接定址”与“解决冲突”是哈希表的两大特点。
hash_map,首先分配一大片内存,形成许多桶。是利用hash函数,对key进行映射到不同区域(桶)进行保存。其插入过程是:
得到key
通过hash函数得到hash值
得到桶号(一般都为hash值对桶数求模)
存放key和value在桶内。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其取值过程是:
得到key
通过hash函数得到hash值
得到桶号(一般都为hash值对桶数求模)
比较桶的内部元素是否与key相等,若都不相等,则没有找到。
取出相等的记录的value。
hash_map中直接地址用hash函数生成,解决冲突,用比较函数解决。这里可以看出,如果每个桶内部只有一个元素,那么查找的时候只有一次比较。当许多桶内没有值时,许多查询就会更快了(指查不到的时候).
由此可见,要实现哈希表, 和用户相关的是:hash函数和比较函数。这两个参数刚好是我们在使用hash_map时需要指定的参数。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
⑤ hash_map数据结构扼要
hash_map类声明
template <class _Key, class _Tp, class _HashFcn = hash<_Key>,
class _EqualKey = equal_to<_Key>,
class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class hash_map
{ ...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
也就是说,在上例中,有以下等同关系:
…
hash_map<int, string> mymap;
//等同于:
hash_map<int, string, hash<int>, equal_to<int> > mymap;
- 1
- 2
- 3
alloc 不用过份关注,是STL的空间配置器,很精华的一部分。如果有兴趣,可以去我主页找,置顶了,大概一万字。
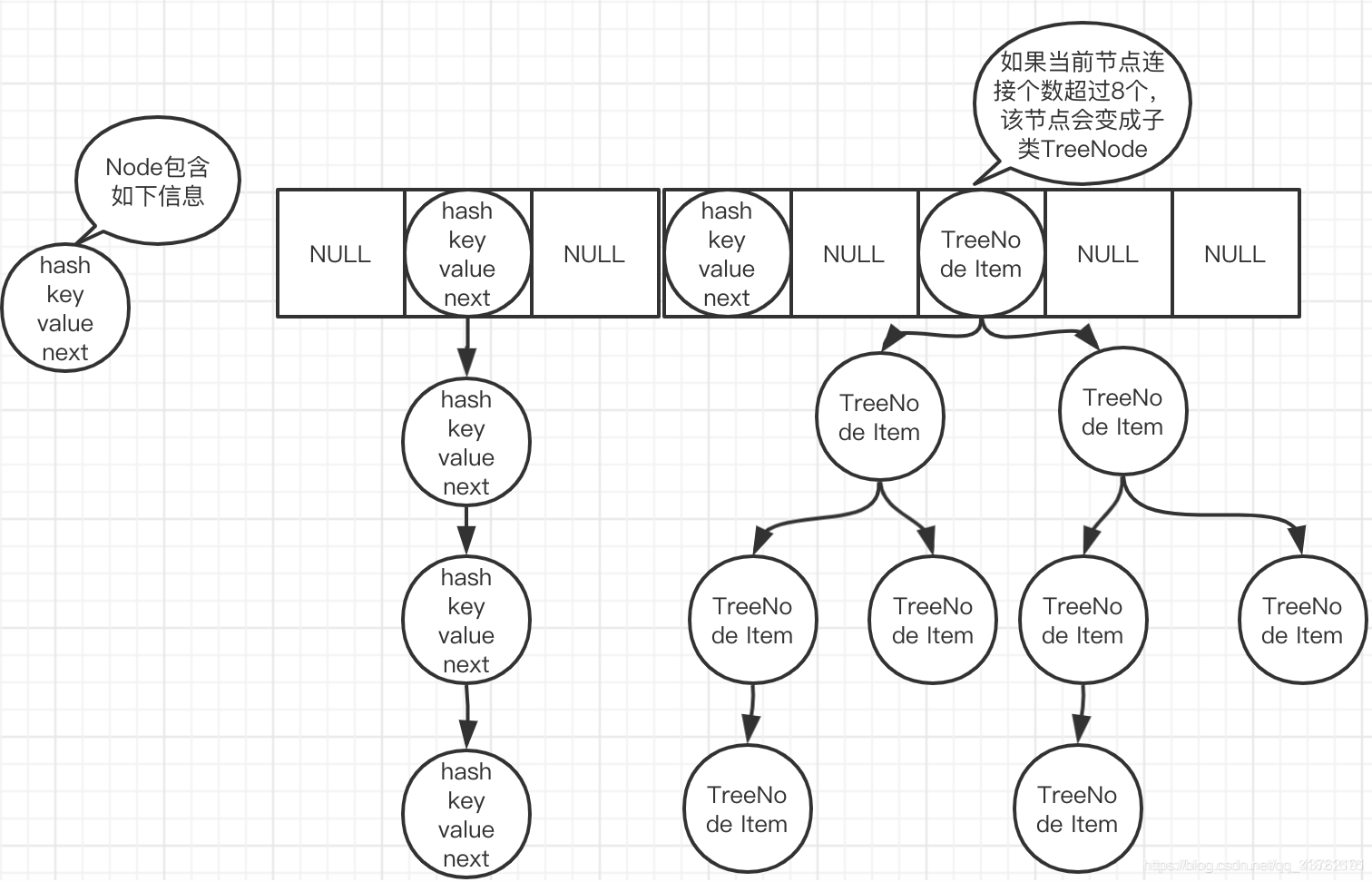
hash_map是一个聚合类,它继承自_Hash类,包括一个vector,一个list和一个pair,其中vector用于保存桶,list用于进行冲突处理,pair用于保存key->value结构,简要地伪码如下:
class hash_map<class _Tkey, class _Tval>
{
private: typedef pair<_Tkey, _Tval> hash_pair; typedef list<hash_pair> hash_list; typedef vector<hash_list> hash_table;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
当然,这只是一个简单模型。
下面是一张开链的哈西散列表:
⑥ 哈希函数:hash< int> (第三个参数)
struct hash<int> { size_t operator()(int __x) const { return __x; }
};
- 1
- 2
- 3
是个函数对象。
在SGI STL中,提供了以下hash函数:
struct hash<char*>
struct hash<const char*>
struct hash<char>
struct hash<unsigned char>
struct hash<signed char>
struct hash<short>
struct hash<unsigned short>
struct hash<int>
struct hash<unsigned int>
struct hash<long>
struct hash<unsigned long>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
也就是说,如果你的key使用的是以上类型中的一种,你都可以使用缺省的hash函数。当然你自己也可以定义自己的hash函数。对于自定义变量,你只能如此,例如对于string,就必须自定义hash函数。
第六点到此为止,太难了,以我现在的水平也写不出案例,要对底层进行调用。
以下属于hash_map类方法分析
⑧ 构造函数
简单变量作为索引。
这个,意会啊。
比方说这样:
hash_map<int, int> IntHash; IntHash[1] = 123; IntHash[2] = 456; int val = IntHash[1]; int val = IntHash[2];
- 1
- 2
- 3
- 4
- 5
- 6
再比方说这样:
hash_map<const char*, int> CharHash;
CharHash["a"] = 123;
CharHash["b"] = 456;
- 1
- 2
- 3
对这个栗子要避免这样用:
char szInput[64] = "";
scanf("%s", szInput);
int val = CharHash[szInput];
- 1
- 2
- 3
- 4
最终的结果就是无论输入任何字符串,都无法找到对应的整数值。因为输入的字符串指针是szInput指针,和"a"或"b"字符串常量指针的大小是绝对不会相同。
- 1
当然如果是会写仿函数的大佬另当别论。
⑨ 设置大小
hash_map(size_type n)
如果讲究效率,这个参数是必须要设置的。n 主要用来设置hash_map 容器中hash桶的个数。桶个数越多,hash函数发生冲突的概率就越小,重新申请内存的概率就越小。n越大,效率越高,但是内存消耗也越大。
⑩ 查找
const_iterator find(const key_type& k) const
用查找,输入为键值,返回为迭代器。
⑪ 下标定位
data_type& operator[](const key_type& k)
特别方便,可像使用数组一样使用。不过需要注意的是,当你使用[key ]操作符时,如果容器中没有key元素,这就相当于自动增加了一个key元素。因此当你只是想知道容器中是否有key元素时,你可以使用find。如果你希望插入该元素时,你可以直接使用[]操作符。
⑫ 插入
insert 函数。
在容器中不包含key值时,insert函数和[]操作符的功能差不多。但是当容器中元素越来越多,每个桶中的元素会增加,为了保证效率,hash_map会自动申请更大的内存,以生成更多的桶。因此在insert以后,以前的iterator有可能是不可用的。
⑬ 删除
erase 函数。在insert的过程中,当每个桶的元素太多时,hash_map可能会自动扩充容器的内存。但在sgi stl中是erase并不自动回收内存。因此你调用erase后,其他元素的iterator还是可用的。
以下属于拓展部分
⑭hash_map是线程不安全的
hash_map的线程不安全主要是发生在扩容函数中。
可以看一下这篇:hash_map与线程安全
⑮ hash_map与hashtable的区别
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
- 1
HashMap内存储数据的Entry数组默认是16,如果没有对Entry扩容机制的话,当存储的数据一多,Entry内部的链表会很长,这就失去了HashMap的存储意义了。所以HasnMap内部有自己的扩容机制。
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable是线程安全的,能用于多线程环境中。
- 1
⑯ 自定义数据类型
本篇不直接提供自定义类型部分,前面提到过,我现在的水平还不够。
但是,既然说来了我这儿就不用在去百度了,那也不是开玩笑的。
如果想使用自定义类型作为hash_map的键值,可以参考这篇博客:
自定义hash_map数据类型
太难了,写这篇,让我想起了当初写空间配置器的感觉。
如果觉得还不错,你就收藏一下慢慢看,后面我会出unordermap的博客。

文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/106315033

- 点赞
- 收藏
- 关注作者
评论(0)