LeetCode精选好题(三)

选进来的,都是我二刷之后确定我自己会做的。
1、矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。
示例 1:
输入:
[
[1,1,1],
[1,0,1],
[1,1,1]
]
- 1
- 2
- 3
- 4
- 5
- 6
输出:
[
[1,0,1],
[0,0,0],
[1,0,1]
]
- 1
- 2
- 3
- 4
- 5
- 6
示例 2:
输入:
[
[0,1,2,0],
[3,4,5,2],
[1,3,1,5]
]
- 1
- 2
- 3
- 4
- 5
- 6
输出:
[
[0,0,0,0],
[0,4,5,0],
[0,3,1,0]
]
- 1
- 2
- 3
- 4
- 5
- 6
进阶:
一个直接的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。 一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。 你能想出一个常数空间的解决方案吗?
- 1
- 2
- 3
思路:
也不想多说,直接暴力O(1)解法吧。
在遍历过程中,遇到零,就把那一行那一列中不为零的部分设为INT_MIN.
第二遍遍历时把值为INT_MIN的设为0。
不过条件判断和循环嵌套会很繁琐。
代码实现:
class Solution {
void setZeroes(vector<vector<int>>& matrix) { int R = matrix.length; int C = matrix[0].length; for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { if (matrix[r][c] == 0) { // We modify the corresponding rows and column elements in place. // Note, we only change the non zeroes to MODIFIED for (int k = 0; k < C; k++) { if (matrix[r][k] != 0) { matrix[r][k] = INT_MIN; } } for (int k = 0; k < R; k++) { if (matrix[k][c] != 0) { matrix[k][c] = INT_MIN; } } } } } for (int r = 0; r < R; r++) { for (int c = 0; c < C; c++) { // Make a second pass and change all INT_MIN elements to 0 """ if (matrix[r][c] == INT_MIN) { matrix[r][c] = 0; } } }
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2、字母异位词分组
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
- 1
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
- 1
- 2
- 3
- 4
- 5
- 6
说明:
所有输入均为小写字母。 不考虑答案输出的顺序。
- 1
- 2
思路:
将字符串进行排序之后作为map的键值,将原字符串作为实值填入map当中,之后遍历map将值取出。
Map<string,vector>
代码实现:
vector<vector<string>> groupAnagrams(vector<string>& strs) { vector<vector<string>> res; map<string,vector<string>> vec; if(strs.empty()) return res; for(int i=0;i<strs.size();i++) { string temp=strs[i]; sort(temp.begin(),temp.end()); vec[temp].push_back(strs[i]); } map<string,vector<string>>::iterator it; for(auto it=vec.begin();it!=vec.end();it++) { res.push_back(it->second); } return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3、无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
- 1
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
- 1
- 2
示例 2:
输入: "bbbbb"
- 1
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
- 1
- 2
示例 3:
输入: "pwwkew"
- 1
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
- 1
- 2
- 3
思路:
这道题主要用到思路是:滑动窗口
什么是滑动窗口?
其实就是一个队列,比如例题中的 abcabcbb,进入这个队列(窗口)为 abc 满足题目要求,当再进入 a,队列变成了 abca,这时候不满足要求。所以,我们要移动这个队列!
如何移动?
我们只要把队列的左边的元素移出就行了,直到满足题目要求!
一直维持这样的队列,找出队列出现最长的长度时候,求出解!
时间复杂度:O(n)
代码实现:
class Solution {
public: int lengthOfLongestSubstring(string s) { if(s.size() == 0) return 0; unordered_set<char> lookup; int maxStr = 0; int left = 0; for(int i = 0; i < s.size(); i++){ while (lookup.find(s[i]) != lookup.end()){ lookup.erase(s[left]); left ++; } maxStr = max(maxStr,i-left+1); lookup.insert(s[i]); } return maxStr; }
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4、两数相加
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
- 1
- 2
- 3
代码实现:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) { ListNode *dummyHead = new ListNode(0); ListNode *p = l1, *q = l2, *curr = dummyHead; int carry = 0; while (p != NULL || q != NULL) { int x = (p != NULL) ? p->val : 0; int y = (q != NULL) ? q->val : 0; int sum = carry + x + y; carry = sum / 10; curr->next = new ListNode(sum % 10); curr = curr->next; if (p != NULL) p = p->next; if (q != NULL) q = q->next; } if (carry > 0) { curr->next = new ListNode(carry); } return dummyHead->next; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
提高篇:如果链表是顺序存储的呢?
我的想法:原地逆置。
5、奇偶链表
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
- 1
- 2
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
- 1
- 2
说明:
应当保持奇数节点和偶数节点的相对顺序。 链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。
- 1
- 2
思路
快慢指针,对点交换,没有压力。
哦,不,不是交换,我中了交换算法的毒。应该把快指针的节点直接提到前边去就好。
代码实现:
ListNode* oddEvenList(ListNode* head) { if (head == NULL) return head; ListNode* fast = head; //快 ListNode* slow = head; //慢 ListNode* temp = head; //临时 int flag = 1; while (1) { for (int i = flag; i > 0 && fast->next != NULL; i--) { fast = fast->next; } if (fast->next != NULL) { temp = fast->next; fast->next = temp->next; temp->next = slow->next; slow->next = temp; fast = temp; slow = temp; flag++; } else { break; } } return head;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
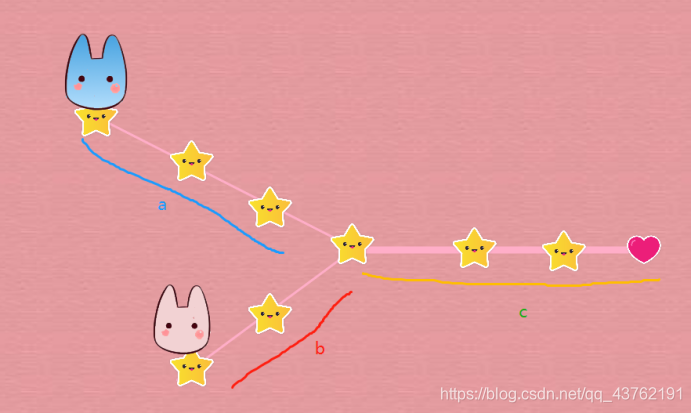
6、相交链表
编写一个程序,找到两个单链表相交的起始节点。
如下面的两个链表:
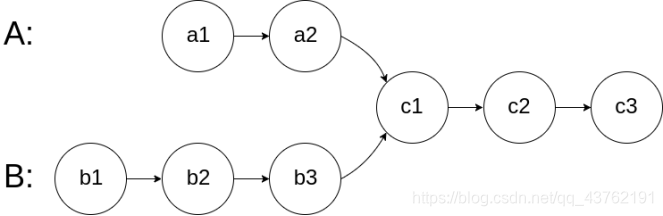
在节点 c1 开始相交。
示例 1:
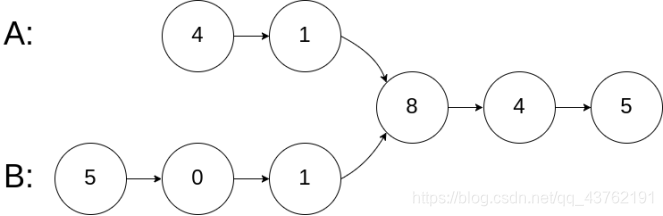
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
- 1
- 2
输入解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
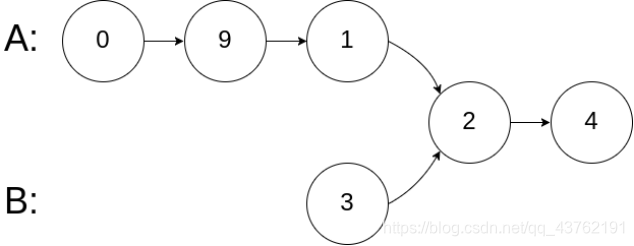
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
- 1
- 2
输入解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
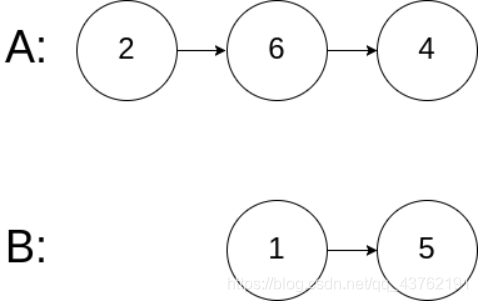
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
- 1
- 2
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null. 在返回结果后,两个链表仍须保持原有的结构。 可假定整个链表结构中没有循环。 程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
- 1
- 2
- 3
- 4
思路:
看这题目哔哔一堆,翻转过来不就结了嘛。
然后,就出问题了。。。
在“注意”里面,还安排了这一条小字:在返回结果后,两个链表仍须保持原有的结构。
草率了。。。
所以我们换一个解法吧,正面应战。
1、先把两条链表到底有多长摸清楚。
2、两条链表从等长的地方开始匹配。
然后,我们再看一下图和题目:是相交链表,就是说,后半部分其实是共用地址的,前面俩解法一直把这两条链表当成了值相同的两条不相干的链表。所以,就有另一种说法了,想一想链表成环的时候寻找入环点怎么找。
又草率了。。。
所以我们再换一种更简单的解法吧:
一种比较巧妙的方式是,分别为链表A和链表B设置指针A和指针B,然后开始遍历链表,如果遍历完当前链表,则将指针指向另外一个链表的头部继续遍历,直至两个指针相遇。
最终两个指针分别走过的路径为:
指针A :a+c+b
指针B :b+c+a
明显 a+c+b = b+c+a,因而如果两个链表相交,则指针A和指针B必定在相交结点相遇。
代码实现:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { ListNode *a = headA, *b = headB; while(a != b) { a = a? a->next : headB; //为NULL时,将值置为另一个链表的起点 b = b? b->next : headA; } return a; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/107670727

- 点赞
- 收藏
- 关注作者
评论(0)