玩转数据结构(2)


思维导图在这个系列写的差不多的时候再整理吧。
指针和动态内存分配
指针是C语言的基本概念,C语言中指针无处不在。实际上,每种数据类型,都有相应的指向T的指针类型。
指针类型变量存放的值,实际上就是内存地址。指针类型有两个最基本的操作:
&:取地址操作
*:去引用 (间接引用)操作
- 1
- 2
引用&
首先,&不是地址运算符,而是类型标识符的一种,就像*也不是指针运算符一样。
就像char* 意为指向char的指针一样,int& 意为指向int 的引用。
栗子来一颗:
int a;
int &at = a;
//上述声明允许将at和a互换,它们指向相同的值和内存单元,就像连体婴一样。
- 1
- 2
- 3
上面这个栗子其实很有内涵在里面
我为什么不写成下面这个形式呢?
int a;
int &at;
at = a;
- 1
- 2
- 3
在指针中是可以的,但是&不允许,&必须在声明时将其初始化。
引用经常被用作函数参数,使得函数中的变量名成为调用程序中变量的别名。这种调用方法我一直搞得晕晕的,正好这次一次性根除。这种传递参数的方法称为按引用传递。按引用传递允许被调用函数能够访问调用函数中的变量。这是C++相比C的一个超越。
来个经典的栗子:
void swap_a(int &a,int &b)
{
int temp;
temp = a;
a = b;
b = temp;
}
//顺便来个指针的
void swap_b(int *a,int *b)
{
int temp;
temp = *a; //a,b是指针,*a,*b才是int
*a = *b;
*b = temp;
}
int main()
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
swap_a(a,b); //看仔细咯,这个是引用调用
swap_b(&a,&b); //看仔细咯,这个是指针调用
//如果理解不了,这样理解:参数中的*和&只是走个过场,告诉人家那个参数是什么类型的
//调用函数时的参数是a,不是*a,也不是&a
//所以&a传的这个a是一个int类型,而*a的这个a就是指针,地址,所以要取地址传给它
//虽然我语文不好,但是都讲到这份上了那应该是可以理解了
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
如果你的意图是让函数使用传给它的信息,又不想把这些信息进行改动,那么应该使用const。
将引用参数声明为const数据的好处有这些:
防止无意中被修改。
使用const参数可以兼容非const传参。
- 1
- 2
将引用用于结构
C++引入引用主要就是为了和结构和类。
它还通过让函数返回指向结构的引用而增添了一个有趣的特点,这与返回结构有所不同。
//代码太长,放段伪代码吧
struct Str
{
};
Str& test(Str &a,const Str &b)
{
//从b中取值,对a进行填充
return a;//其实可以做void类型,没必要多此一举
}
int main()
{
Str a,b,c;
//b是有初值的,这是伪代码
c = test(a,b);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
如果test函数返回一个结构,而不是指向结构的引用,相当于把整个结构体复制到一个临时位置,再将这个拷贝复制给c,但是现在返回值为引用,将直接将a复制到c,效率更高。
返回引用时最重要的一点是:应避免返回函数终止时将不再存在的内存单元的引用。
下面是一个反面教材:
Str& test(const Str &d)
{
Str &e;
···
return e;
}
- 1
- 2
- 3
- 4
- 5
- 6
何时使用引用参数?
程序员能够修改调用函数中的数据对象。
通过传递引用而不是整个数据对象,可以提高程序的运行速度。
- 1
- 2
指针
指针和const
将const用于指针有一些很微妙的地方。
可以用两种不同的方式将const关键字用于指针。
int age = 20; const int * pt = &age;
//该声明指出,pt指向一个const int,因此不能使用pt来修改这个值。
//现在来看一个很微妙的问题:其实age并不是一个常量,只是对于pt来说,它是一个常量。
//就是说age可以改,只不过不能用pt来改而已。
- 1
- 2
- 3
- 4
注意点:不允许将常量数据赋值给非常量指针,个中理由就不用多解释了吧。
const int age = 20; int * pt = &age;
int sloth = 80; int * const finger = &sloth;
#这种声明格式使得这个指针只能指向sloth,不过可以通过这个指针修改sloth的值。
- 1
- 2
- 3
- 4
通过指针返回字符串的函数
现在,假设需要一个返回字符串的函数,是的,函数无法返回一个字符串,但是可以返回字符串的地址,这样效率更高。
void test(char *rc)
{
···
memset(rc,字符串);
···
}
- 1
- 2
- 3
- 4
- 5
- 6
相当于是使用回调函数,我个人比较喜欢这一套模式。
通过指针返回结构
具体操作参考第二点。
当然,这里还有另外的应用场景:
void test2(const JieGouTi1 *a,JieGouTi2 *b)
{
//将a中的某些值赋值给b
}
//这里有一个注意点,传进去赋值的结构体指针最好用const.
- 1
- 2
- 3
- 4
- 5
函数指针
关于为什么要使用函数指针,我的理解还不是很深刻,毕竟功力不足。但是我知道那些回调函数都是用函数指针的,所以对函数指针必须要理解好。
这叫啥,“但行好事,莫问为啥”。
函数指针完成任务的流程是这样的:
获取函数的地址
声明一个函数指针
使用函数指针来调用函数
获取函数地址
获取函数地址那是比较简单的事,如果说 void Hanshu();这是一个函数,那么它的地址就是 Hanshu。
如果函数Hanshubaba();要调用这个函数,是这样的:Hanshubaba(Hanshu);
切记不能写成:Hanshubaba(Hanshu());
声明函数指针
假设现在有这么一个函数:int test3(void *arg); //这个arg参数,回调函数里面用,要解释有点长。
现在要将之改成函数指针形式:int (*test3)(void *arg);
首先,将test3更换成(*test3),因此,(*test3)也是函数,那么test3就是函数指针。
为声明优先级,需要将 *test3 括号起来。
函数指针用武之地
如果你非要我说函数指针存在的意义,那我也真不好给你扯个所以然出来,那我就,举几个用得到的地方吧:
自定义排序/搜索
不同的模式(如策略,观察者)
回调
- 1
- 2
- 3
- 4
- 5
关于指针的一些思考
前面说到,将指针作为参数传入,在函数内部对指针进行修改,函数结束后指针的修改将被保留。
因为指针传参代表着地址传参。
解惑:如何让对指针参数的修改不被保存。
看个栗子:
class B {
char* b;
public:
B() {
b = new char[5];
strcpy(b,"aaaa");
}
char* get_b() { return b; }
};
class A {
private:
char* a;
public:
A(B* temp) { a = temp->get_b(); };
void set_A() { strcpy(a, "kkkk"); //顶替掉了
}
};
int main() {
B* b = new B();
A* a = new A(b);
a->set_A();
cout << b->get_b() << endl;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
结局打印出来的 b,就是“kkkk”。
那为什么会这样?前面解释过了,a、b都是对内存地址的映射,对a进行修改,就是对地址上的数据进行修改,而b只不过是地址的一个映射而已,读取b,就是读取地址上的东西,那本质已经被改了,读出来的东西自然不一样。
再看个例子:
void Del (POINT_T * the_head, int index)
{
POINT_T *pFree=NULL; POINT_T *pNode=the_head;
int flag=0;
while (pNode->next!=NULL)
{
if(flag==index-1)
{ pFree=pNode->next; //再指向数据域就爆了 pNode->next=pNode->next->next; free(pFree->pData); free(pFree); break;
}
pNode=pNode->next;
flag++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这是链表的一个例子,那可能会纳闷儿,为什么对 pNode执行了 pNode=pNode->next;操作,而the_head却没有跟着变呢?
原因很简单,pNode->next也是一个映射地址,这句话的意思就是用一个新的地址映射,顶替掉那个旧的,使得指针pNode指向一块新的地址,和the_head失去联系。
联合体union
联合体,又叫共用体,很直接,就是多个数据共同使用同一块空间。
分配空间准则:分配共用体中最大数据类型的空间大小。
内存共用准则:
- 同等大小的数据视为同一数据(这个要小心,例如long int 和int共存时,修改一个另一个就会随之改变)
- 大类型优先初始化。看示例:
#include<iostream>
using namespace std;
union var{ long int l; //4个字节 double i; //8个字节
};
int main(){ union var v; v.i = 6.2; v.l = 5;
// v.i = 6.2; //如果放在这里,会将v.l覆盖 cout<<v.i<<endl; cout<<v.l<<endl; return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
可以拿去测试。
根据union固定首地址和union按最大需求开辟一段内存空间两个特征,可以发现,所有表面的定义都是虚的,所谓联合体union,就是在内存给你划了一个足够用的空间,往里边扔什么数据谁管得到?
这个如果有兴趣的朋友可以自己去试一下将共用体对象强转。
LeetCode精选题集
1、引用传参
先来看个题目:
等下也是用这个题目
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
- 1
- 2
- 3
- 4
- 5
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
- 1
- 2
- 3
- 4
- 5
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
for (int i = 0; i < len; i++) { print(nums[i]);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
以前只知道指针有这种骚操作,现在知道引用也有这种骚操作了。
2、快慢指针
对于上面这题的题解,便可以采用快慢指针的办法。

不用快慢指针也可以,不过本文不是为了说谁的办法优秀,这题也不能体现出快慢指针的多少优越性,但是重要的是学到这个思路不是吗。
可以考虑一下下面这道题:
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
- 1
- 2
- 3
- 4
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/3sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
3、map、set的使用
以下是一个使用set的示例:
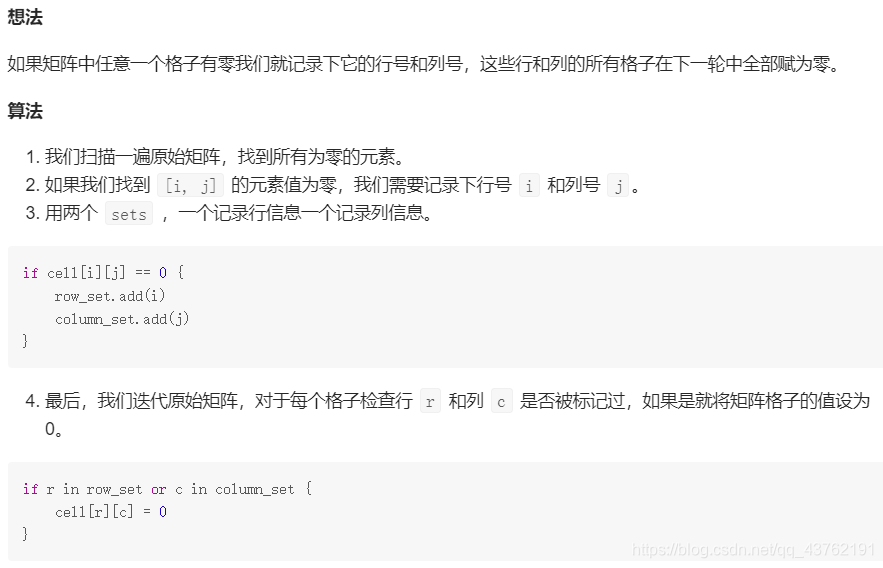
给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。
示例 1:
输入:
[
[1,1,1],
[1,0,1],
[1,1,1]
]
- 1
- 2
- 3
- 4
- 5
输出:
[
[1,0,1],
[0,0,0],
[1,0,1]
]
- 1
- 2
- 3
- 4
- 5
示例 2:
输入:
[
[0,1,2,0],
[3,4,5,2],
[1,3,1,5]
]
- 1
- 2
- 3
- 4
- 5
输出:
[
[0,0,0,0],
[0,4,5,0],
[0,3,1,0]
]
- 1
- 2
- 3
- 4
- 5
进阶:
一个直接的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
你能想出一个常数空间的解决方案吗?
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/set-matrix-zeroes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
我的解法:
void setZeroes(vector<vector<int>>& matrix) { if(matrix.empty()) return; int r = matrix.size(); int c = matrix[0].size(); set<int> rs; set<int> cs; set<int>::iterator sit; //将有0的行列提取出来 for (int i = 0; i < r; i++) { for (int j = 0; j < c; j++) { if (matrix[i][j] == 0) { rs.insert(j); cs.insert(i); } } } if (!cs.empty()) { int a = c; vector<int> temp; while (a > 0) { temp.push_back(0); a--; } //将行清零 for (sit = cs.begin(); sit != cs.end(); sit++) { matrix[*sit] = temp; } } //将列清零 if (!rs.empty()) { for (sit = rs.begin(); sit != rs.end(); sit++) { for (int k = 0; k< r; k++) { matrix[k][*sit] = 0; } } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
思路:
接下来是一个map的使用示例:
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
说明:
所有输入均为小写字母。
不考虑答案输出的顺序。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/group-anagrams
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
我的解法:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{ vector<vector<string>> res; map<string,vector<string>> vec; if(strs.empty()) return res; for(int i=0;i<strs.size();i++) { string temp=strs[i]; sort(temp.begin(),temp.end()); vec[temp].push_back(strs[i]); } map<string,vector<string>>::iterator it; for(auto it=vec.begin();it!=vec.end();it++) { res.push_back(it->second); } return res;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
思路:

自己试一题:
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
- 1
- 2
- 3
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
- 1
- 2
- 3
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
- 1
- 2
- 3
- 4
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/111414347

- 点赞
- 收藏
- 关注作者
评论(0)