Python3 Scrapy框架学习二:爬取豆瓣电影Top250

【摘要】 打开项目里的items.py文件,定义如下变量,
import scrapyfrom scrapy import Item,Field class DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() movie = Field() yea...
打开项目里的items.py文件,定义如下变量,
-
import scrapy
-
from scrapy import Item,Field
-
-
-
class DoubanItem(scrapy.Item):
-
# define the fields for your item here like:
-
# name = scrapy.Field()
-
movie = Field()
-
year = Field()
-
star = Field()
-
vote = Field()
-
quote = Field()
然后打开项目里的spiders文件夹内的doubanTop250.py文件。
-
# -*- coding: utf-8 -*-
-
import scrapy
-
from douban.items import DoubanItem
-
-
-
class Doubantop250Spider(scrapy.Spider):
-
name = 'doubanTop250'
-
#allowed_domains = ['movie.douban.com/top250/'] 这里需要修改下,涉及爬取下一页的关键
-
allowed_domains = ['movie.douban.com']
-
start_urls = ['http://movie.douban.com/top250/']
-
-
def parse(self, response):
-
infos = response.css('.info')
-
for info in infos:
-
item = DoubanItem()
-
item['movie'] = info.css('.title::text').extract_first().strip()
-
item['year'] = info.css('div p[class = ""]::text').re_first('\d+') #正则的用法
-
item['vote'] = info.css('.rating_num::text').extract_first().strip()
-
item['star'] = info.css('.star span::text').extract()[-1].strip() #获取最后一项
-
item['quote'] = info.css('.inq::text').extract_first().strip()
-
yield item
-
-
next = response.css('.next a::attr("href")').extract_first() #查找下一页的链接
-
url = response.urljoin(next)
-
yield scrapy.Request(url = url,callback = self.parse) #解析下一页
打开settings.py文件,加入如下两行代码:
-
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
-
FEED_EXPORT_ENCODING = 'gbk'
然后在命令提示符输入:
scrapy crawl doubanTop250 -o douban.csv
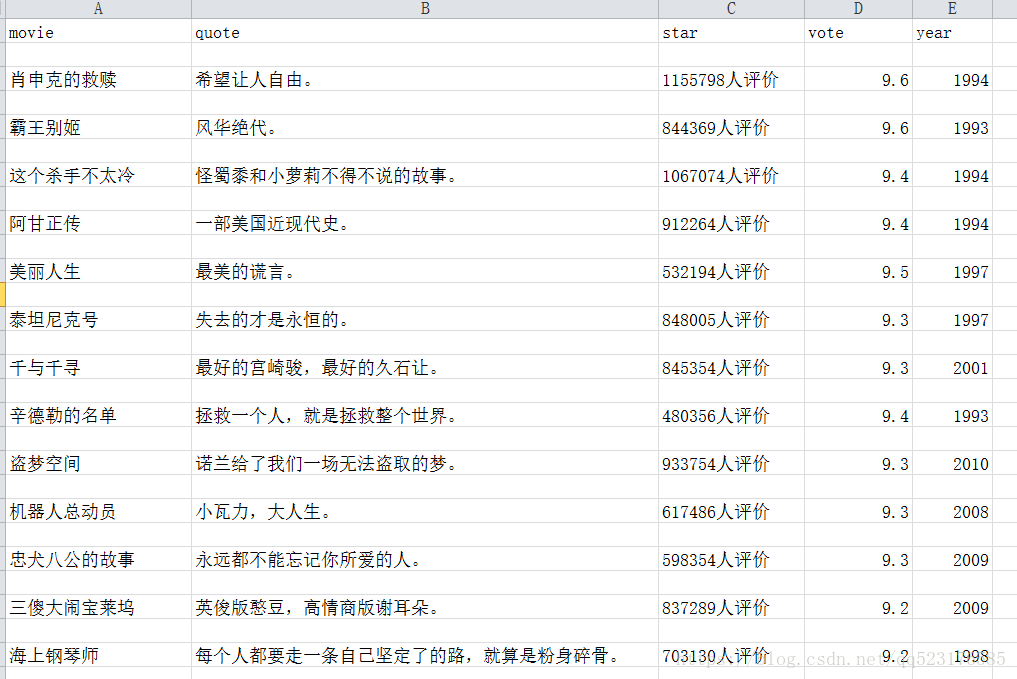
爬取结束后会生成一个csv文件,效果图如下:
文章来源: blog.csdn.net,作者:悦来客栈的老板,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq523176585/article/details/82935403

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)