浅谈神经网络改进小技巧----学习率衰减

前言
今天我们来谈下学习率衰减,利用学习率衰减来的到我更好的预测效果。简单实现了几个。
github地址
https://github.com/yanjingke/learn_rate
什么是学习率衰减
在训练神经网络时,使用学习率控制参数的更新速度.学习率较小时,会大大降低参数的更新速度;学习率较大时,会使搜索过程中发生震荡,导致参数在极优值附近徘徊.
为此,在训练过程中引入学习率衰减,使学习率随着训练的进行逐渐衰减.
在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、指数衰减、多项式衰减、自然指数衰减、余弦衰减、余弦退火衰减、余弦退火衰减更新版
分段常数衰减
分段常数衰减需要事先定义好的训练次数区间,在对应区间置不同的学习率的常数值,一般情况刚开始的学习率要大一些,之后要越来越小,要根据样本量的大小设置区间的间隔大小,样本量越大,区间间隔要小一点。下图即为分段常数衰减的学习率变化图,横坐标代表训练次数,纵坐标代表学习率。
在keras中的实现为ReduceLROnPlateau:
ReduceLROnPlateau的主要参数有:
1、factor:在某一项指标不继续下降后学习率下降的比率。
2、patience:在某一项指标不继续下降几个时代后,学习率开始下降。
代码:
# 导入ReduceLROnPlateau
from keras.callbacks import ReduceLROnPlateau
# 定义ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1)
# 使用ReduceLROnPlateau
model.fit(X_train, Y_train, callbacks=[reduce_lr])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

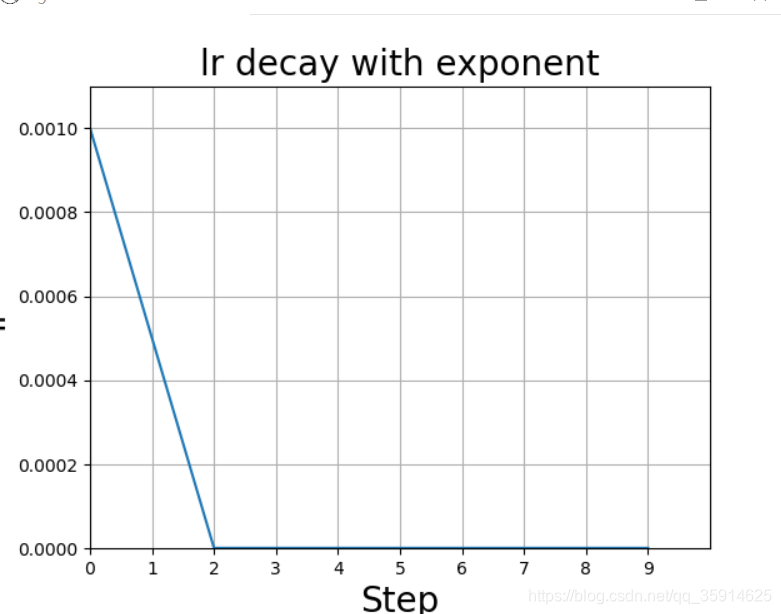
指数衰减
以指数衰减方式进行学习率的更新,学习率的大小和训练次数指数相关,其更新规则为:

1、learning_rate指的是当前的学习率。
2、learning_rate_base指的是基础学习率。
3、decay_rate指的是衰减系数。
代码:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten, Conv2D, Dropout, Input, Dense, MaxPooling2D
from keras.models import Model
def exponent(global_epoch, learning_rate_base, decay_rate, min_learn_rate=0, ): learning_rate = learning_rate_base * pow(decay_rate, global_epoch) # print("learning_rate_base:" + str(learning_rate_base)) # print("learning_rate:" + str(learning_rate)) # print("e:" + str(np.e ** ((-decay_rate) / (global_epoch)))) learning_rate = max(learning_rate, min_learn_rate) return learning_rate
class ExponentDecayScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, decay_rate, global_epoch_init=0, min_learn_rate=0, verbose=0): super(ExponentDecayScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 全局初始化epoch self.global_epoch = global_epoch_init self.decay_rate = decay_rate # 是否打印显示 self.verbose = verbose # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] # 加入进去方便画图,并且设置学习率 def on_epoch_end(self, epochs, logs=None): self.global_epoch = self.global_epoch + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr) # 更新学习率 def on_epoch_begin(self, batch, logs=None): lr = exponent(global_epoch=self.global_epoch, learning_rate_base=self.learning_rate_base, decay_rate=self.decay_rate, min_learn_rate=self.min_learn_rate) self.learning_rate_base=lr K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_epoch + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# -----------------------------#
# 创建模型
# -----------------------------#
inputs = Input([28, 28, 1])
x = Conv2D(32, kernel_size=5, padding='same', activation="relu")(inputs)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Conv2D(64, kernel_size=5, padding='same', activation="relu")(x)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs, out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
init_epoch = 0
# 每一次训练使用多少个Batch
batch_size = 31
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 学习率
exponent_lr = ExponentDecayScheduler(learning_rate_base=learning_rate_base, global_epoch_init=init_epoch, decay_rate=0.9, min_learn_rate=1e-6,verbose=1 )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[exponent_lr])
plt.plot(exponent_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, epochs, 0, learning_rate_base * 1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('lr decay with exponent', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120

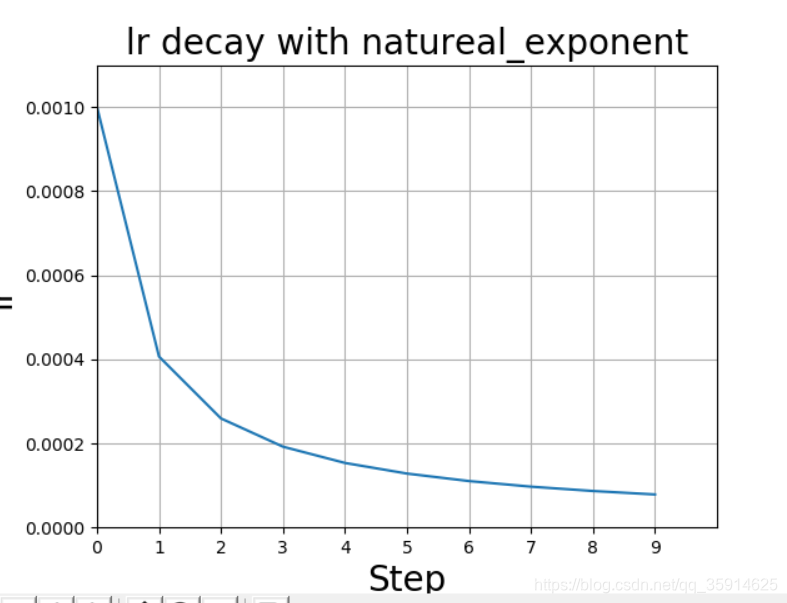
自然指数衰减
它与指数衰减方式相似,不同的在于它的衰减底数是ee,故而其收敛的速度更快,一般用于相对比较
容易训练的网络,便于较快的收敛,其更新规则如下:

1、learning_rate指的是当前的学习率。
2、learning_rate_base指的是基础学习率。
3、decay_rate指的是衰减系数
代码:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten, Conv2D, Dropout, Input, Dense, MaxPooling2D
from keras.models import Model
import numpy as np
def exponent(global_epoch, learning_rate_base, decay_rate, min_learn_rate=0, ): if global_epoch!=0: learning_rate = learning_rate_base * np.e ** ((-decay_rate) / (global_epoch)) print("learning_rate_base:"+str(learning_rate_base)) print("learning_rate:" + str(learning_rate)) print("e:"+str(np.e ** ((-decay_rate) / (global_epoch)))) else: learning_rate = learning_rate_base learning_rate = max(learning_rate, min_learn_rate) return learning_rate
class ExponentDecayScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, decay_rate, global_epoch_init=0, min_learn_rate=0, verbose=0): super(ExponentDecayScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 全局初始化epoch self.global_epoch = global_epoch_init self.decay_rate = decay_rate # 是否打印显示 self.verbose = verbose # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] # 加入进去方便画图,并且设置学习率 def on_epoch_end(self, epochs, logs=None): self.global_epoch = self.global_epoch + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr) # 更新学习率 def on_epoch_begin(self, batch, logs=None): lr = exponent(global_epoch=self.global_epoch, learning_rate_base=self.learning_rate_base, decay_rate=self.decay_rate, min_learn_rate=self.min_learn_rate) self.learning_rate_base = lr K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_epoch + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# -----------------------------#
# 创建模型
# -----------------------------#
inputs = Input([28, 28, 1])
x = Conv2D(32, kernel_size=5, padding='same', activation="relu")(inputs)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Conv2D(64, kernel_size=5, padding='same', activation="relu")(x)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs, out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
init_epoch = 0
# 每一次训练使用多少个Batch
batch_size = 31
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 学习率
exponent_lr = ExponentDecayScheduler(learning_rate_base=learning_rate_base, global_epoch_init=init_epoch, decay_rate=0.9, min_learn_rate=1e-6,verbose=1 )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[exponent_lr])
plt.plot(exponent_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, epochs, 0, learning_rate_base * 1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('lr decay with natureal_exponent', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
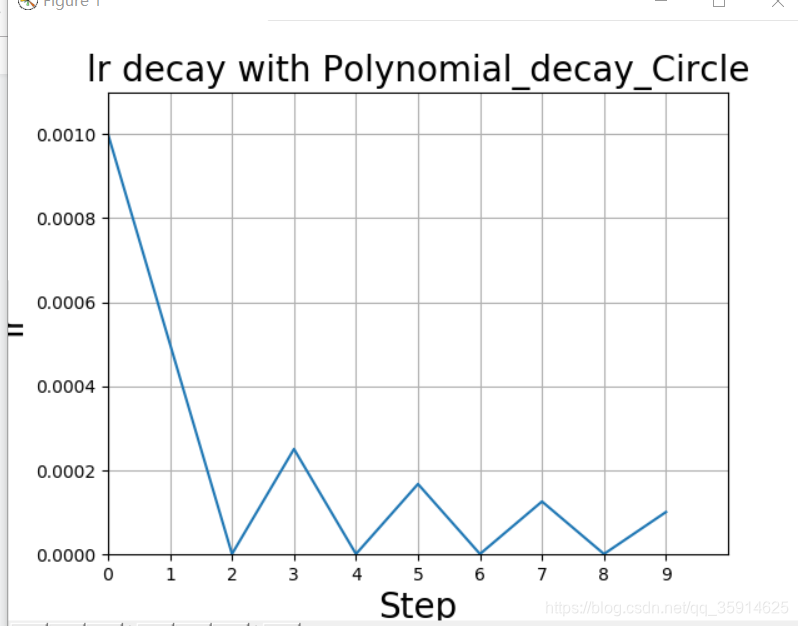
多项式衰减
应用多项式衰减的方式进行更新学习率,这里会给定初始学习率和最低学习率取值,然后将会按照给定的衰减方式将学习率从初始值衰减到最低值。
1、decayg_learning_rate指的是当前的学习率。
2、learning_rate_base指的是基础学习率。
3、end_lerarning_rate指最小学习率。
4、global_step指用于衰减计算的全局步数,非负,用于逐步计算衰减指数
5、decay_steps指衰减步数,必须是正值,决定衰减周期
参数cycle决定学习率是否在下降后重新上升,若cycle为Flase,不在上升。其更新规则如下式所示:

若cycle为True,则学习率下降后重新上升;使用decay_steps的倍数,取第一个大于global_steps的结果.


circle为Flase:
circle为Ture
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten, Conv2D, Dropout, Input, Dense, MaxPooling2D
from keras.models import Model
def exponent(global_epoch, decay_steps, learning_rate_base, decay_rate, min_learn_rate=0, power=1, cycle=False ): # learning_rate = (learning_rate_base - min_learn_rate) * pow((1 - global_step / decay_steps) ,power) + min_learn_rate if cycle==True: global_step = global_epoch if global_step > 0: decay_steps = decay_steps * np.ceil(global_step / decay_steps) learning_rate = (learning_rate_base - min_learn_rate) * pow((1 - global_step / decay_steps), power) + min_learn_rate else: learning_rate = learning_rate_base else: if global_epoch> 0: global_step = min(global_epoch, decay_steps) learning_rate = (learning_rate_base - min_learn_rate) * pow((1 - global_step / decay_steps), power) + min_learn_rate else: learning_rate = learning_rate_base learning_rate = max(learning_rate, min_learn_rate) return learning_rate
class PolynomiaDecayScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, decay_rate, decay_steps, global_epoch_init=0, min_learn_rate=0.001, power=1, verbose=0, cycle=False): super(PolynomiaDecayScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 全局初始化epoch self.global_epoch = global_epoch_init self.power=power self.decay_rate = decay_rate # 是否打印显示 self.verbose = verbose self.decay_steps = decay_steps # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] self.cycle=cycle # 加入进去方便画图,并且设置学习率 def on_epoch_end(self, epochs, logs=None): self.global_epoch = self.global_epoch + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr) # 更新学习率 def on_epoch_begin(self, batch, logs=None): lr = exponent(global_epoch=self.global_epoch, decay_steps=self.decay_steps, learning_rate_base=self.learning_rate_base, decay_rate=self.decay_rate, min_learn_rate=self.min_learn_rate, power=self.power, cycle=self.cycle ) # self.learning_rate_base = lr K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_epoch + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# -----------------------------#
# 创建模型
# -----------------------------#
inputs = Input([28, 28, 1])
x = Conv2D(32, kernel_size=5, padding='same', activation="relu")(inputs)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Conv2D(64, kernel_size=5, padding='same', activation="relu")(x)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs, out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
init_epoch = 0
# 每一次训练使用多少个Batch
batch_size = 31
# 最大学习率
learning_rate_base = 0.001
sample_count = len(x_train)
# 学习率
exponent_lr = PolynomiaDecayScheduler(learning_rate_base=learning_rate_base, global_epoch_init=init_epoch, decay_rate=0.9, min_learn_rate=1e-6, verbose=1, decay_steps=2, power=1, cycle=True )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[exponent_lr])
plt.plot(exponent_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, epochs, 0, learning_rate_base * 1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('lr decay with Polynomial_decay_Circle', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
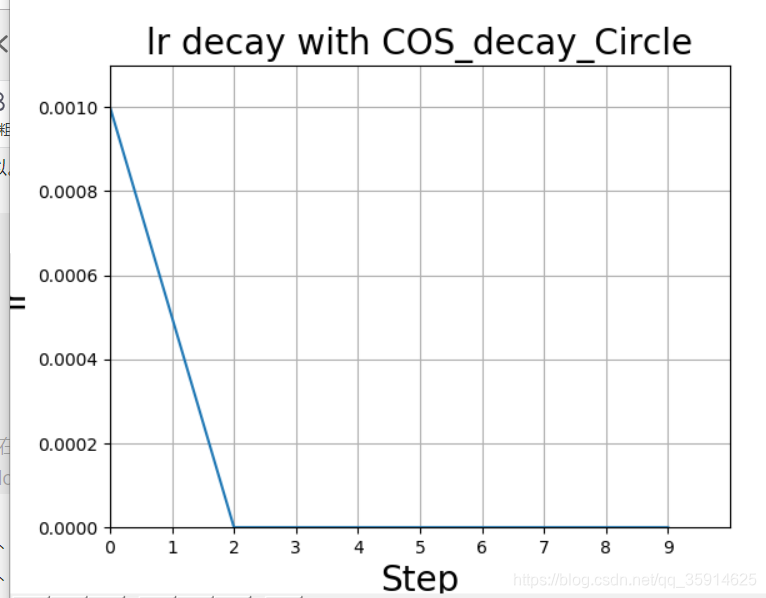
余弦衰减
余弦衰减就是采用余弦的相关方式进行学习率的衰减,衰减图和余弦函数相似。其更新机制如下式所示:

1、learning_rate:标初始学习率.
2、global_step:用于衰减计算的全局步数.
3、decay_steps:衰减步数.
3、alpha(min_learn_rate):最小学习率(learning_rate的部分)。
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten, Conv2D, Dropout, Input, Dense, MaxPooling2D
from keras.models import Model
def exponent(global_epoch, decay_steps, learning_rate_base, min_learn_rate=0, ): if global_epoch> 0: global_step = min(global_epoch, decay_steps) # linear_decay =(decay_steps-global_step)/decay_steps cosine_decay = 0.5 * (1 +np.cos(np.pi * global_step / decay_steps)) decayed = (1 - min_learn_rate) * cosine_decay + min_learn_rate learning_rate = learning_rate_base* decayed else: learning_rate = learning_rate_base learning_rate = max(learning_rate, min_learn_rate) return learning_rate
class COSScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, decay_rate, decay_steps, global_epoch_init=0, min_learn_rate=0.001, verbose=0, ): super(COSScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 全局初始化epoch self.global_epoch = global_epoch_init self.decay_rate = decay_rate # 是否打印显示 self.verbose = verbose self.decay_steps = decay_steps # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] # 加入进去方便画图,并且设置学习率 def on_epoch_end(self, epochs, logs=None): self.global_epoch = self.global_epoch + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr) # 更新学习率 def on_epoch_begin(self, batch, logs=None): lr = exponent(global_epoch=self.global_epoch, decay_steps=self.decay_steps, learning_rate_base=self.learning_rate_base, min_learn_rate=self.min_learn_rate, ) # self.learning_rate_base = lr K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_epoch + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# -----------------------------#
# 创建模型
# -----------------------------#
inputs = Input([28, 28, 1])
x = Conv2D(32, kernel_size=5, padding='same', activation="relu")(inputs)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Conv2D(64, kernel_size=5, padding='same', activation="relu")(x)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs, out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
init_epoch = 0
# 每一次训练使用多少个Batch
batch_size = 31
# 最大学习率
learning_rate_base =1e-3
sample_count = len(x_train)
# 学习率
exponent_lr =COSScheduler(learning_rate_base=learning_rate_base, global_epoch_init=init_epoch, decay_rate=0.9, min_learn_rate=1e-8, verbose=1, decay_steps=2, )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[exponent_lr])
plt.plot(exponent_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, epochs, 0, learning_rate_base * 1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('lr decay with COS_decay_Circle', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
上面那个因为epoch太小,所以不平滑。如下图是我找到图片,感觉平混点。红色即为标准的余弦衰减曲线。

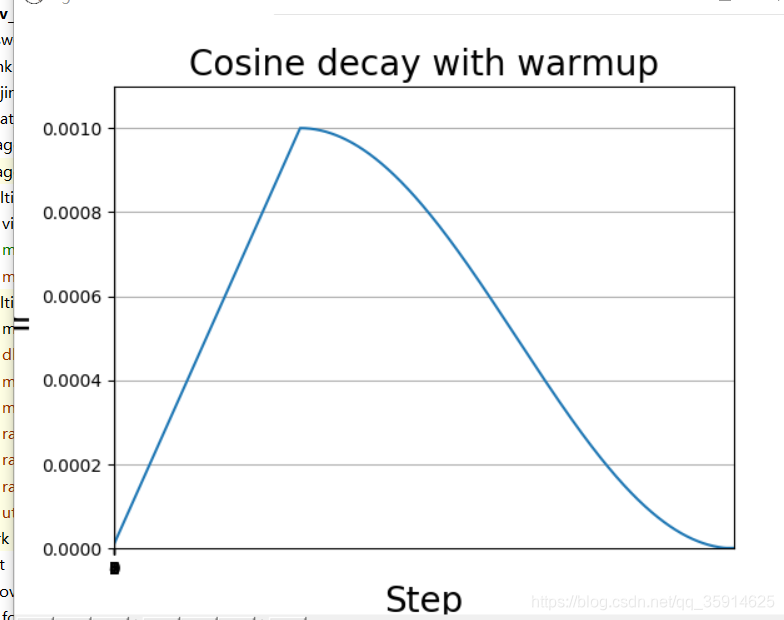
余弦退火衰减
余弦退火衰减法,学习率会先上升再下降。上升的时候使用线性上升,下降的时候模拟cos函数下降。附上退火算法详解。
余弦退火衰减有几个比较必要的参数:
1、learning_rate_base:学习率最高值。
2、warmup_learning_rate:最开始的学习率。
3、warmup_steps:多少步长后到达顶峰值。
4、learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。
5、total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数)
6、 hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降
代码:
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten, Conv2D, Dropout, Input, Dense, MaxPooling2D
from keras.models import Model
def cosine_decay_with_warmup(global_step, learning_rate_base, total_steps, warmup_learning_rate=0.0, warmup_steps=0, hold_base_rate_steps=0, min_learn_rate=0, ): """ 参数: global_step: 上面定义的Tcur,记录当前执行的步数。 learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。 total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数) warmup_learning_rate: 这是warm up阶段线性增长的初始值 warmup_steps: warm_up总的需要持续的步数 hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降 """ if total_steps < warmup_steps: raise ValueError('total_steps must be larger or equal to ' 'warmup_steps.') # 这里实现了余弦退火的原理,设置学习率的最小值为0,所以简化了表达式 learning_rate = 0.5 * learning_rate_base * (1 + np.cos(np.pi * (global_step - warmup_steps - hold_base_rate_steps) / float( total_steps - warmup_steps - hold_base_rate_steps))) # 如果hold_base_rate_steps大于0,表明在warm up结束后学习率在一定步数内保持不变 if hold_base_rate_steps > 0: learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps, learning_rate, learning_rate_base) if warmup_steps > 0: if learning_rate_base < warmup_learning_rate: raise ValueError('learning_rate_base must be larger or equal to ' 'warmup_learning_rate.') # 线性增长的实现 slope = (learning_rate_base - warmup_learning_rate) / warmup_steps warmup_rate = slope * global_step + warmup_learning_rate # 只有当global_step 仍然处于warm up阶段才会使用线性增长的学习率warmup_rate,否则使用余弦退火的学习率learning_rate learning_rate = np.where(global_step < warmup_steps, warmup_rate, learning_rate) learning_rate = max(learning_rate, min_learn_rate) return learning_rate
class WarmUpCosineDecayScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, total_steps, global_step_init=0, warmup_learning_rate=0.0, warmup_steps=0, hold_base_rate_steps=0, min_learn_rate=0, verbose=0): super(WarmUpCosineDecayScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 总共的步数,训练完所有世代的步数epochs * sample_count / batch_size self.total_steps = total_steps # 全局初始化step self.global_step = global_step_init # 热调整参数 self.warmup_learning_rate = warmup_learning_rate # 热调整步长,warmup_epoch * sample_count / batch_size self.warmup_steps = warmup_steps self.hold_base_rate_steps = hold_base_rate_steps # 参数显示 self.verbose = verbose # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] # 更新global_step,并记录当前学习率 def on_batch_end(self, batch, logs=None): self.global_step = self.global_step + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr) # 更新学习率 def on_batch_begin(self, batch, logs=None): lr = cosine_decay_with_warmup(global_step=self.global_step, learning_rate_base=self.learning_rate_base, total_steps=self.total_steps, warmup_learning_rate=self.warmup_learning_rate, warmup_steps=self.warmup_steps, hold_base_rate_steps=self.hold_base_rate_steps, min_learn_rate=self.min_learn_rate) K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_step + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# -----------------------------#
# 创建模型
# -----------------------------#
inputs = Input([28, 28, 1])
x = Conv2D(32, kernel_size=5, padding='same', activation="relu")(inputs)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Conv2D(64, kernel_size=5, padding='same', activation="relu")(x)
x = MaxPooling2D(pool_size=2, strides=2, padding='same', )(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs, out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
# 预热期
warmup_epoch = 3
# 每一次训练使用多少个Batch
batch_size = 16
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 总共的步长
total_steps = int(epochs * sample_count / batch_size)
# 预热步长
warmup_steps = int(warmup_epoch * sample_count / batch_size)
# 学习率
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base, total_steps=total_steps, warmup_learning_rate=1e-5, warmup_steps=warmup_steps, hold_base_rate_steps=5, min_learn_rate=1e-6 )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[warm_up_lr])
plt.plot(warm_up_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, total_steps, 0, learning_rate_base * 1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('Cosine decay with warmup', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
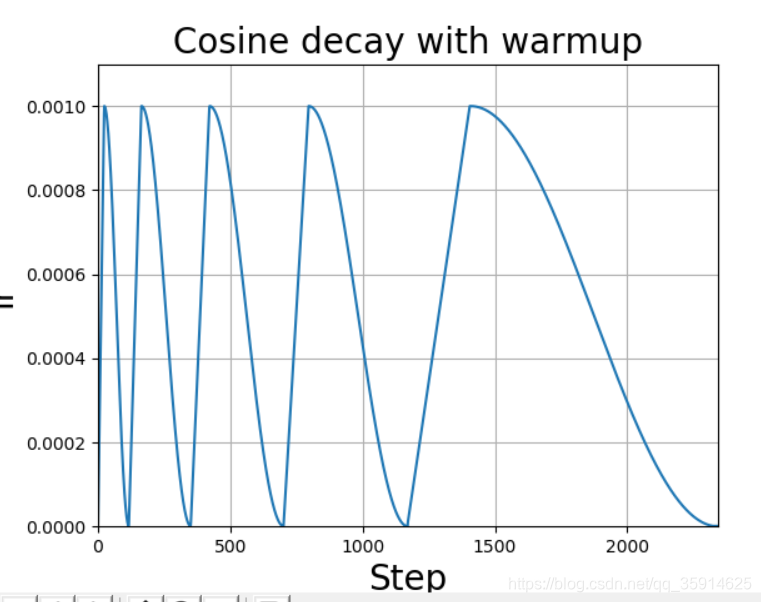
余弦退火衰减更新版
yolov4中余弦退火衰减并非只上升下降一次。
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import backend as K
from keras.layers import Flatten,Conv2D,Dropout,Input,Dense,MaxPooling2D
from keras.models import Model
def cosine_decay_with_warmup(global_step, learning_rate_base, total_steps, warmup_learning_rate=0.0, warmup_steps=0, hold_base_rate_steps=0, min_learn_rate=0, ): """ 参数: global_step: 上面定义的Tcur,记录当前执行的步数。 learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。 total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数) warmup_learning_rate: 这是warm up阶段线性增长的初始值 warmup_steps: warm_up总的需要持续的步数 hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降 """ if total_steps < warmup_steps: raise ValueError('total_steps must be larger or equal to ' 'warmup_steps.') #这里实现了余弦退火的原理,设置学习率的最小值为0,所以简化了表达式 learning_rate = 0.5 * learning_rate_base * (1 + np.cos(np.pi * (global_step - warmup_steps - hold_base_rate_steps) / float(total_steps - warmup_steps - hold_base_rate_steps))) #如果hold_base_rate_steps大于0,表明在warm up结束后学习率在一定步数内保持不变 if hold_base_rate_steps > 0: learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps, learning_rate, learning_rate_base) if warmup_steps > 0: if learning_rate_base < warmup_learning_rate: raise ValueError('learning_rate_base must be larger or equal to ' 'warmup_learning_rate.') #线性增长的实现 slope = (learning_rate_base - warmup_learning_rate) / warmup_steps warmup_rate = slope * global_step + warmup_learning_rate #只有当global_step 仍然处于warm up阶段才会使用线性增长的学习率warmup_rate,否则使用余弦退火的学习率learning_rate learning_rate = np.where(global_step < warmup_steps, warmup_rate, learning_rate) learning_rate = max(learning_rate,min_learn_rate) return learning_rate
class WarmUpCosineDecayScheduler(keras.callbacks.Callback): """ 继承Callback,实现对学习率的调度 """ def __init__(self, learning_rate_base, total_steps, global_step_init=0, warmup_learning_rate=0.0, warmup_steps=0, hold_base_rate_steps=0, min_learn_rate=0, # interval_epoch代表余弦退火之间的最低点 interval_epoch=[0.05, 0.15, 0.30, 0.50], verbose=0): super(WarmUpCosineDecayScheduler, self).__init__() # 基础的学习率 self.learning_rate_base = learning_rate_base # 热调整参数 self.warmup_learning_rate = warmup_learning_rate # 参数显示 self.verbose = verbose # learning_rates用于记录每次更新后的学习率,方便图形化观察 self.min_learn_rate = min_learn_rate self.learning_rates = [] self.interval_epoch = interval_epoch # 贯穿全局的步长 self.global_step_for_interval = global_step_init # 用于上升的总步长 self.warmup_steps_for_interval = warmup_steps # 保持最高峰的总步长 self.hold_steps_for_interval = hold_base_rate_steps # 整个训练的总步长 self.total_steps_for_interval = total_steps self.interval_index = 0 # 计算出来两个最低点的间隔 self.interval_reset = [self.interval_epoch[0]] for i in range(len(self.interval_epoch)-1): self.interval_reset.append(self.interval_epoch[i+1]-self.interval_epoch[i]) self.interval_reset.append(1-self.interval_epoch[-1])
#更新global_step,并记录当前学习率 def on_batch_end(self, batch, logs=None): self.global_step = self.global_step + 1 self.global_step_for_interval = self.global_step_for_interval + 1 lr = K.get_value(self.model.optimizer.lr) self.learning_rates.append(lr)
#更新学习率 def on_batch_begin(self, batch, logs=None): # 每到一次最低点就重新更新参数 if self.global_step_for_interval in [0]+[int(i*self.total_steps_for_interval) for i in self.interval_epoch]: self.total_steps = self.total_steps_for_interval * self.interval_reset[self.interval_index] self.warmup_steps = self.warmup_steps_for_interval * self.interval_reset[self.interval_index] self.hold_base_rate_steps = self.hold_steps_for_interval * self.interval_reset[self.interval_index] self.global_step = 0 self.interval_index += 1 lr = cosine_decay_with_warmup(global_step=self.global_step, learning_rate_base=self.learning_rate_base, total_steps=self.total_steps, warmup_learning_rate=self.warmup_learning_rate, warmup_steps=self.warmup_steps, hold_base_rate_steps=self.hold_base_rate_steps, min_learn_rate = self.min_learn_rate) K.set_value(self.model.optimizer.lr, lr) if self.verbose > 0: print('\nBatch %05d: setting learning ' 'rate to %s.' % (self.global_step + 1, lr))
# 载入Mnist手写数据集
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.expand_dims(x_train,-1)
x_test = np.expand_dims(x_test,-1)
y_train = y_train
#-----------------------------#
# 创建模型
#-----------------------------#
inputs = Input([28,28,1])
x = Conv2D(32, kernel_size= 5,padding = 'same',activation="relu")(inputs)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Conv2D(64, kernel_size= 5,padding = 'same',activation="relu")(x)
x = MaxPooling2D(pool_size = 2, strides = 2, padding = 'same',)(x)
x = Flatten()(x)
x = Dense(1024)(x)
x = Dense(256)(x)
out = Dense(10, activation='softmax')(x)
model = Model(inputs,out)
# 设定优化器,loss,计算准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 设置训练参数
epochs = 10
# 预热期
warmup_epoch = 2
# 每一次训练使用多少个Batch
batch_size = 256
# 最大学习率
learning_rate_base = 1e-3
sample_count = len(x_train)
# 总共的步长
total_steps = int(epochs * sample_count / batch_size)
# 预热步长
warmup_steps = int(warmup_epoch * sample_count / batch_size)
# 学习率
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base, total_steps=total_steps, warmup_learning_rate=1e-5, warmup_steps=warmup_steps, hold_base_rate_steps=5, min_learn_rate=1e-6 )
# 利用fit进行训练
model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[warm_up_lr]) plt.plot(warm_up_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, total_steps, 0, learning_rate_base*1.1])
plt.grid()
plt.title('Cosine decay with warmup', fontsize=20)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
文章来源: blog.csdn.net,作者:快了的程序猿小可哥,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_35914625/article/details/108493400

- 点赞
- 收藏
- 关注作者
评论(0)