keras搭建有趣的孪生网络

keras搭建有趣的孪生网络
要解决问题
第一类,分类数量较少,每一类的数据量较多,比如ImageNet、VOC等。这种分类问题可以使用神经网络或者SVM解决,只要事先知道了所有的类。
第二类,分类数量较多(或者说无法确认具体数量),每一类的数据量较少,比如人脸识别、人脸验证任务
孪生网络
孪生网络将输入映射为一个特征向量,使用两个向量之间的“距离”(L1 Norm)来表示输入之间的差异(图像语义上的差距)。孪生网络有两个输入,两个输入传入到一个神经网络中,神经网络把两个特征映射到空间,形成向量,计算loss。对比出相似度。

github代码下载
https://github.com/yanjingke/luanshen
孪生网络具体实现
1.主干特征提取部分
在主干特征提取部分,我采用了vgg,vgg结构如下。我这里主要采用vgg,是因为vgg方便可以和其他特征提取部分作出对比。
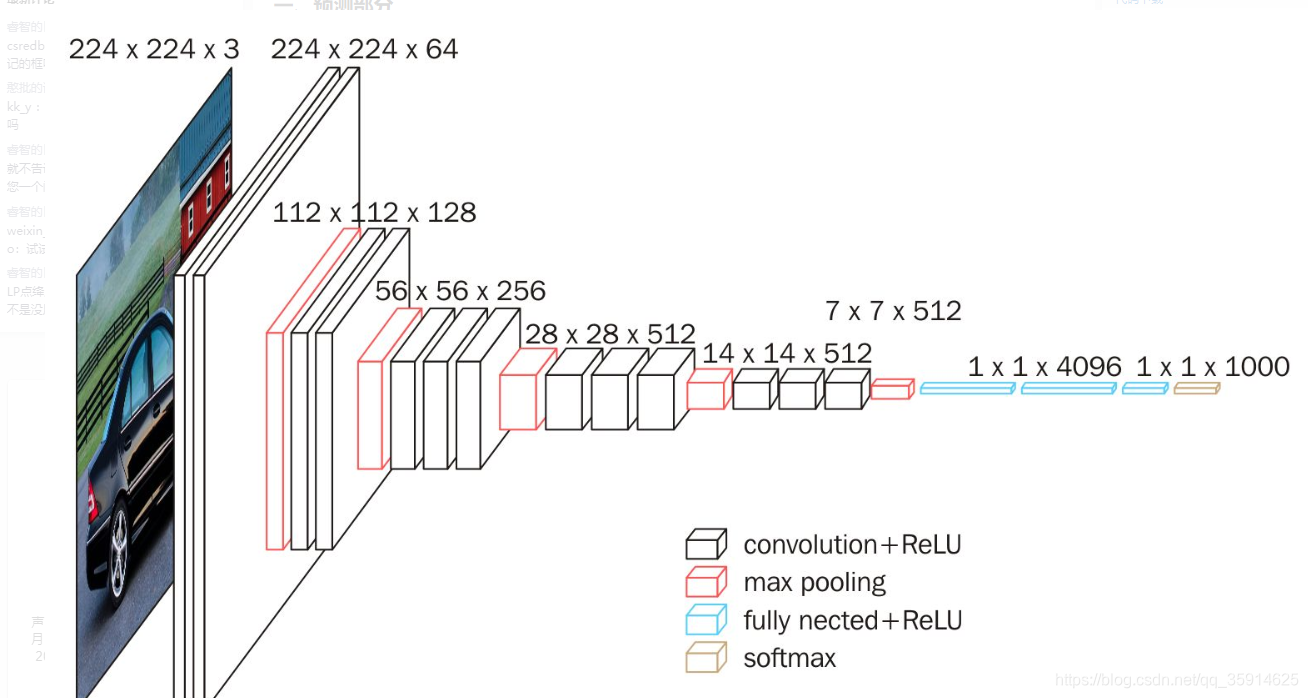
孪生网络主干提取部分:输入为1051051,这里采用1通道数的灰白图。
在vgg部分,总共进行了5个步骤:
1.首先进行了2次卷积和一次最大平均池化,通道数变成了64
2.进行了2次卷积和一次最大平均池化,通道数变成了128
3.进行了3次卷积和一次最大平均池化,通道数变成了256
4.进行了3次卷积和一次最大平均池化,通道数变成了512
5.进行了3次卷积和一次最大平均池化,通道数变成了512
def VGG16(input_shape): image_input = Input(shape = input_shape) # 第一个卷积部分 x = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')(image_input) x = Conv2D(64,(3,3),activation = 'relu',padding = 'same', name = 'block1_conv2')(x) x = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')(x) # 第二个卷积部分 x = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')(x) x = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')(x) x = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')(x) # 第三个卷积部分 x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')(x) x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')(x) x = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')(x) x = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')(x) # 第四个卷积部分 x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')(x) x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')(x) x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')(x) x = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')(x) # 第五个卷积部分 x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')(x) x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')(x) x = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')(x) x = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')(x) # 分类部分 x = Flatten(name = 'flatten')(x) model = Model(image_input,x,name = 'vgg16') return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
得到特征提取后的网络
2.比较网络比较图片的相似度
在比较网络中利用vgg提取到特征,对输入的两张图片进行相似度的比较,主要采用了欧式距离,对两图片进行了向量计算,在经过relu和sigmoid把其值变为0-1之间。其值越大越相似。
def siamese(input_shape): VGG_model = VGG16(input_shape) # densenet_model =MobileNetv3_large(input_shape) input_image_1 = Input(shape=input_shape) input_image_2 = Input(shape=input_shape) encoded_image_1 = VGG_model(input_image_1) encoded_image_2 = VGG_model(input_image_2) l1_distance_layer = Lambda( lambda tensors: K.abs(tensors[0] - tensors[1])) l1_distance = l1_distance_layer([encoded_image_1, encoded_image_2]) out = Dense(512,activation='relu')(l1_distance) out = Dense(1,activation='sigmoid')(out) model = Model([input_image_1,input_image_2],out) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.训练部分
训练格式

chapter里面存放的相似的图片,外面为不相似的图片。
训练和loss值比较
在我们输入两张图片时,标签为1位相似图片,标签为0为不相似的图片,利用binary_crossentropy计算loss。
下面就可以点击train.py,进行训练
利用训练好的图片,进行预测,就可以得到相似的概率。
if __name__ == "__main__": model = Siamese() while True: image_1 = input('Input image_1 filename:') try: image_1 = Image.open(image_1) except: print('Image_1 Open Error! Try again!') continue image_2 = input('Input image_2 filename:') try: image_2 = Image.open(image_2) except: print('Image_2 Open Error! Try again!') continue probability = model.detect_image(image_1,image_2) print(probability[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19


文章来源: blog.csdn.net,作者:快了的程序猿小可哥,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_35914625/article/details/107992882

- 点赞
- 收藏
- 关注作者
评论(0)