基于分解的参考点多目标优化(R-MEAD)

R-MEAD:Reference Point Based Multi-objective Optimization Through Decomposition
1.摘要
本文提出了一种基于用户定义的进化算法,该算法依靠分解策略将多目标问题转化为一组单目标问题。通过使用参考点,该算法可以将搜索集中在更多的优选区域上,这会节省大量的计算资源。我们提出的算法动态地调整权重向量,并且能够收敛于优选区域。将分解策略与参考点方法相结合,为更有效地优化多目标问题打好了基础。分解方法的使用减轻了基于优势的方法的选择压力问题,而参考点允许更集中的搜索。实验结果表明,该算法能够找到接近决策者指定的参考点的解。此外,我们的结果表明,与基于状态分解的进化多目标算法相比,用较少的计算量可以获得高质量的解。
2.介绍
进化多目标优化(EMO)技术已成功地应用。然而,随着目标数目的增加,进化多目标方法的性能急剧下降。
1.当有三个以上的目标时,观察寻找Pareto前沿很困难。
2.大约形成完整的Pareto最优前沿所需的解的数目相对于目标数呈指数增长。
3.最后,当目标数量增加时,大多数解决方案在初始随机生成的人群中都是非支配的,因此没有足够的选择压力一定会把解决方案寻找Pareto 最优解前沿。
利用多准则策略中的分解策略将多目标问题转化为单目标问题,我们可以减轻基于支配的进化算法的选择压力问题。这些策略主要依赖于对目标函数的权值的赋值,从而在Pareto-最优前沿上得到一个解。并且对于每一组权值,都可以在Pareto-最优前沿找到一个解。
虽然基于分解的方法(如MOGLS和MOEA/D)比基于支配的方法从选择压力问题中受到的影响要小,并且有可能更好地扩展到更高的目标空间。当目标数量增加时,为了逼近整个帕累托最优前沿,它们必须解决的单目标子问题的数量呈指数增长。因此为了减少计算成本,本文集中精力搜索Pareto最优前沿的一个优选区域。
基于用户偏好的方法,在目标空间中的参考点作为它的优选区域的代表,通过访问这样的参考点,,该算法可以更有效地通过在更期望的区域中搜索来使用计算预算。
本文提出了一种将用户偏好与基于分解的EMO算法相集成的多目标优化算法,以提供一种机制。提出的算法具有以下主要优点:
1.通过使用基于分解的方法,不太容易受到由于使用支配比较而产生的选择压力问题的影响。
(随着目标数量的增加,在种群中几乎所有的解(x)都变得彼此不支配。这句话可以理解为:可以设想一下,原来两解X1和X2是相互支配,我们只需要它们其中一个保留其中一个来作为支配解(即Pareto最优解),但是当添加一个目标时,可能这两个解就会变得相互不支配,那我们就要将两个解都保留下来作为Pareto最优解,放入下一次迭代中,那么对于基于Pareto支配关系选择,无法明显而且快速的区分并选出Pareto最优解,反而会由于解大部分都保留下来,增加了更新过程中对后代解的选择压力,大大延缓了进化过程(迭代次数增加),然而促进了种群的多样性。原文链接:https://blog.csdn.net/zp18355435850/article/details/80501324)
2.通过搜索决策者喜欢的区域来提高计算效率
3.更快收敛到Pareto-最优前沿
4.更好地扩展到更高的目标空间
3.相关知识
1.加权和法
加权和法是将多目标问题转化为单目标问题的最简单、最著名的策略之一。虽然这种方法简单易用,但选择一个权重向量,从而在用户参考点附近找到解决方案并不是一项简单的任务。复合目标函数是加权归一化目标之和,定义如下:

对于给定的一组权值,方程将在Rm中形成一个超平面,其位置由目标值确定,这些目标值随后依赖于输入向量 和平面的方向由加权值Wi决定。在有两个目标的特殊情况下,gWS将采用直线的形式,其中斜率由权重向量确定,如图:
和平面的方向由加权值Wi决定。在有两个目标的特殊情况下,gWS将采用直线的形式,其中斜率由权重向量确定,如图:
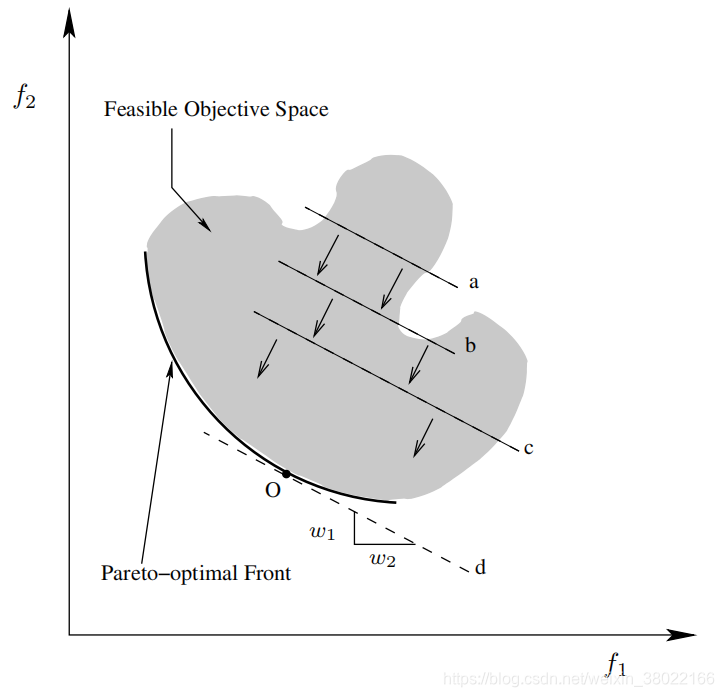
加权和法的一个主要优点是它的简单性和有效性,但在处理非凸的帕累托最优锋时则不那么有效。
2.用户提供参数,在目标空间中的参考点作为优选区域的代表
这种方法允许用户通过一个参考点指定他们想要的区域。由于参考点允许更集中的搜索。这些固有的优势促使研究者将基于用户偏好的方法应用于进化多目标优化(Emo)领域。
4.方法
我们的目标是设计一种算法,当目标数量增加时,该算法能够更好地缩放。没有去生成一组权重向量,以覆盖整个帕累托最优前沿,我们生成较小的权重向量集,以查找接近于用户提供的引用的多个解决方案。如果我们设法找到一个合适的权向量,就有可能在参考点附近找到一个解。然而,找到一个最佳权重向量,从而得到一个接近参考点的解是有困难的。为了解决这个问题,我们首先选择一个次最优权向量,并在进化过程中对其进行调整,直到得到尽可能接近用户提供的参考的解以及帕累托最优前沿。

图2中的区域B示出了接近我们希望找到的参考点的期望区域。区域A和C给出了在远离期望区域(B)的Pareto-最优前沿上得到的几个解。白色实心箭头显示了更新权重向量的效果。请注意,人口和权重向量的优化同时进行,结果是图2中以白色圆圈表示的次优解可能直接移动到帕累托最优前沿的期望区域。
算法:
步骤1-初始化:初始化,用预定分解法计算进化算法的有限迭代次数,一旦种群进化,所有目标都被评估,结果存储在PF矩阵中。应该注意的是,人口中的每一个个体只与一个权重向量相关联,这个向量后来被用来分解这个问题。
步骤2-找到基本的权重向量:在这个阶段,对于用户提供的每个参考点,使用欧氏距离寻找目标空间(PF)中离参考点最近的点。选择与每个参考点最近的点对应的权重向量作为基准权重向量,围绕该向量生成一组新的权重向量。
步骤3-进化种群:在这里,总体进化,与每个参考点相关联的权重向量以循环方式更新,直到达到终止条件为止。
步骤3.1-更新权重:在这一阶段,计算了每个参考点到其在总体中的相应解的欧氏距离。为了找到更新权重的方向,找出了与参考点对应的最接近和最远点对应的最优和最坏的权重。然后,根据最优和最坏的权重向量计算更新方向。一旦确定了更新方向,就会通过在梯度方向上移动权重和步骤变量确定的数量来更新权重。对于与每个参考点相关联的所有权重向量都重复此过程。
5.结论
本文基于参考点的方法允许更集中的搜索,并消除了近似整个帕累托前沿的需要。通过分解提出了一种基于偏好的进化多目标优化方法.建议的方法有可能应用于许多客观问题。 主要原因如下:
1.利用分解技术将多目标问题转化为单目标问题,不受基于优势的方法中常见的选择压力问题的影响。
2.通过使用参考点,搜索可以集中在所需的区域上,这可能会节省大量的计算资源。
本文提出了一种非常简单的权向量更新方法。在我们未来的工作中,我们打算研究在处理以下许多问题时,调整权重向量的有效性- 具有复杂非凸Pareto最优前沿的目标问题。
总结
1.得出初代种群人口P和权重IW(size2*m)
2.利用分解法进行演化并且进行评价
3.寻找目标空间(PF(P的评价结果))中离参考点最近的点ind,找出ind的BW,通过ind与参考点空间得出基准权重向量
(解决方案个数实际是NP,wi是BW和个体的自己的w结合生成Wi)
4.重新在参考点附近初始生产P
5.进行P的人口演变得出PF,再对每个个体的权重向量进行更新。
6.对每个参考点和P中的个体计算欧式距离,为了找到更新权重的方向,
找出了与参考点对应的最接近和最远点对应的最优和最坏的权重,通过权重向量得出要进行更新的方向。
7.一旦确定了更新方向,就会通过在梯度方向上移动权重和步骤变量确定的数量来更新权重。
文章来源: blog.csdn.net,作者:αβγθ,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_38022166/article/details/100525671

- 点赞
- 收藏
- 关注作者
评论(0)