教与学算法(TLBO)

TLBO,由Rao等人在2011年提出的,是一种基于群体的启发式优化算法,不需要任何算法特定参数。这种方法模拟了传统的课堂教学过程。整个优化过程包括教师阶段和学习者阶段。在教师阶段,每个学生都向最优秀的个体进行学习。在学习阶段,每个学生都以随机的方式向其他学生学习。
基于教学的优化(TLBO)是一种模拟课堂教学过程的基于群体的优化方法。TLBO分为两部分。第一部分是“教师阶段”,即向教师学习;第二部分是“学习者阶段”,即通过学习者之间的互动进行学习。在TLBO中,种群被视为一类学习者。每个学习者代表优化问题的一个可能的解决方案,分数代表适应度值。老师被认为是迄今为止得到的最好的解决办法。
在教学阶段,教师T是一个群体中具有最佳适应度值的解决方案。M是这个班级的平均成绩。学习者试图通过教师的教学来提高他们的平均成绩。对于第i个学习者Xi,候选解决方案newXi计算如下:

rand是在[0,1]之间产生的随机数,TF是决定M值的教学因素。TF公式为:
在学习阶段,每个学习者通过与从课堂中随机选择的学习者互动来提高自己的成绩。计算如下:
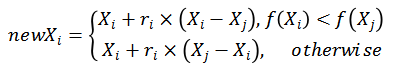
j是从种群中随机选取的,ri表示的是rand。f()指的是要优化的目标函数
伪代码如下:

之后是matlab代码:
-
function [fitnessgbest,gbest]=TLBOmain
-
warning('off')
-
clear;
-
pn=10;%种群大小
-
gn=20;
-
popmax=5.12;
-
popmin=-5.12;
-
for i=1:pn
-
pop(i,:)=5*rand(1,2);
-
fitness(i)=fun(pop(i,:)); %得到适应度值(把pop(i,:)代到目标函数中得到的结果)
-
fitnessgbest=min(fitness);
-
end %初始化
-
for j=1:gn
-
pop_m=sum(pop)/10;
-
[bestfitness,bestindex]=min(fitness);
-
pop_t=pop(bestindex,:);
-
%找到当前的老师
-
%教学阶段
-
for i=1:pn
-
pop_new(i,:)=pop(i,:)+rand*(pop_t-round(1+rand*(2-1)*pop_m));
-
pop_new(i,find(pop_new(1,:)>popmax))=popmax;
-
pop_new(i,find(pop_new(1,:)<popmin))=popmin;%越界处理
-
fitness_new(i)=fun(pop_new(i,:));
-
if fitness_new(i)<fitness(i)
-
pop(i,:)=pop_new(i,:);
-
end
-
end
-
%进行替换
-
%学习阶段
-
for i=1:pn
-
k=randint(1,1,[1 10]);
-
while k==i
-
k=randint(1,1,[1 10]);
-
end
-
if fun(pop(i,:))<fun(pop(k,:))
-
pop_new(i,:)=pop(i,:)+rand*(pop(i,:)-pop(k,:));
-
else if fun(pop(i,:))>fun(pop(k,:));
-
pop_new(i,:)=pop(i,:)+rand*(pop(k,:)-pop(i,:));
-
end
-
end
-
pop_new(i,find(pop_new(i,:)>popmax))=popmax;
-
pop_new(i,find(pop_new(i,:)<popmin))=popmin;
-
fitness_new(i)=fun(pop_new(i,:));
-
if fitness_new(i)<fitness(i)
-
pop(i,:)=pop_new(i,:);
-
end
-
end
-
for i=1:pn
-
fitness(i)=fun(pop(i,:));
-
if fitness(i)<fitnessgbest
-
gbest=pop(i,:);
-
fitnessgbest=fitness(i);
-
end
-
end
-
yy(j)=fitnessgbest; %存储最优的值
-
end
-
plot(yy)
-
function y1=fun(pop)
-
y1=sum(pop.^2-10*cos(2*pi*pop)+10);
文章来源: blog.csdn.net,作者:αβγθ,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_38022166/article/details/106125151

- 点赞
- 收藏
- 关注作者
评论(0)