《进击大数据》系列教程之MapReduce篇

一、MapReduce 安装
(1)分布式计算概述
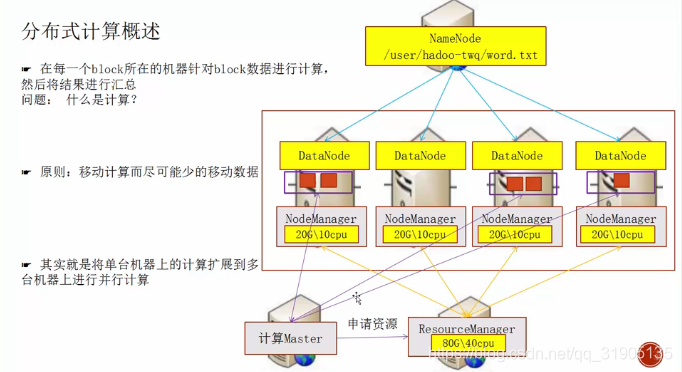

访问 master:8088 查看yarn 是否启动成功。
(2)验证mapreduce 是否安装成功
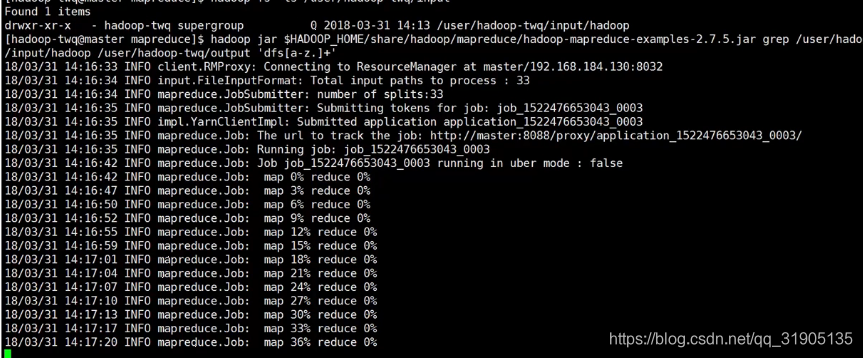
运行 hadoop 安装包中 自带的 mapreduce 正则匹配例子。

看到控制台有如下输出说明mapReduce 任务正在运行中,同时可以在yarn 监控界面上看到任务执行记录
二、hadoop 序列化机制

使用 hadoop 的 writeable 接口 实现序列化
-
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-client</artifactId>
-
<version>2.7.5</version>
-
<dependency>
-
@Data
-
@NoArgsConstructor
-
@AllArgsConstructor
-
@ToString
-
public class BlockWritable implements Writable {
-
-
private long blockId;
-
-
private long numBytes;
-
-
private long generationStamp;
-
-
@Override
-
public void write(DataOutput out) throws IOException {
-
out.writeLong(blockId);
-
out.writeLong(numBytes);
-
out.writeLong(generationStamp);
-
}
-
-
@Override
-
public void readFields(DataInput in) throws IOException {
-
this.blockId = in.readLong();
-
this.numBytes = in.readLong();
-
this.generationStamp = in.readLong();
-
}
-
-
-
-
public static void main(String[] args) throws IOException {
-
//序列化
-
BlockWritable blockWritable = new BlockWritable(34234L, 234324345L, System.currentTimeMillis());
-
DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("D:/block.txt"));
-
blockWritable.write(dataOutputStream);
-
//反序列化
-
Writable writable = WritableFactories.newInstance(BlockWritable.class);
-
DataInputStream dataInputStream = new DataInputStream(new FileInputStream("D:/block.txt"));
-
writable.readFields(dataInputStream);
-
System.out.println((BlockWritable) writable);
-
}
-
}
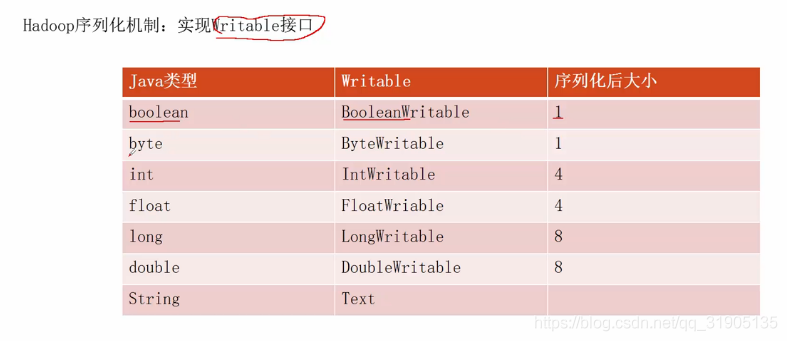
hadoop 封装的一套序列化机制,序列化之后文件大小比java 的序列化要小很多,在大数据量的情况下,对性能有很大的提升。
三、使用mapReduce 实现分布式文本行数计算
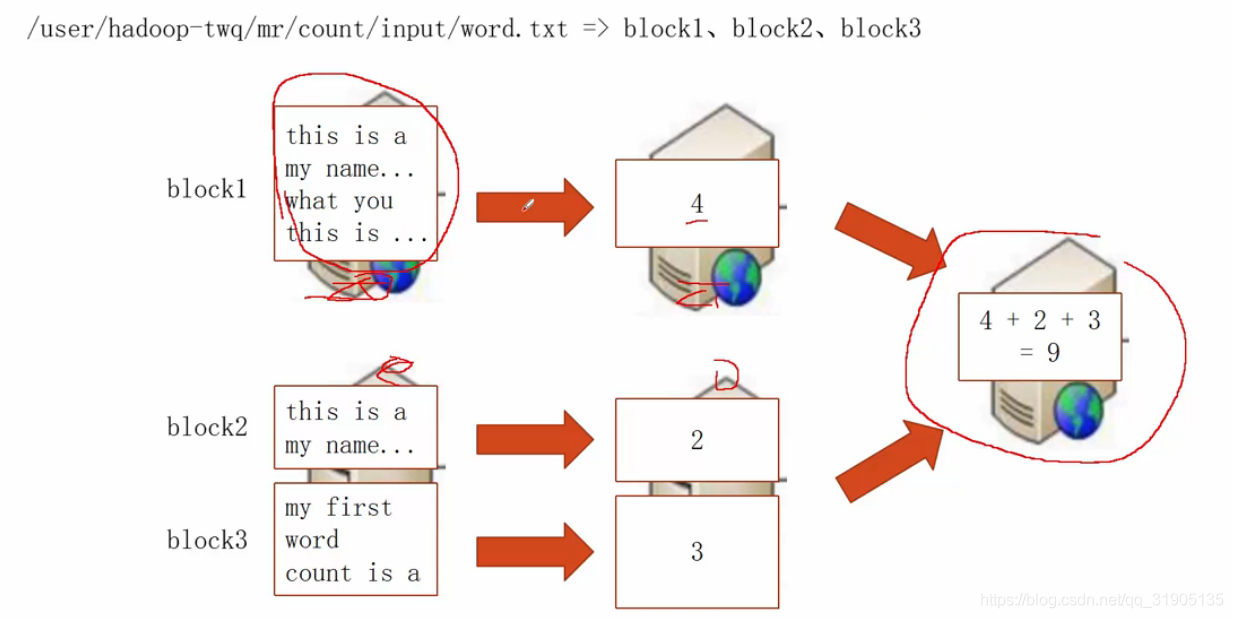
(1)分布式文本行数计算
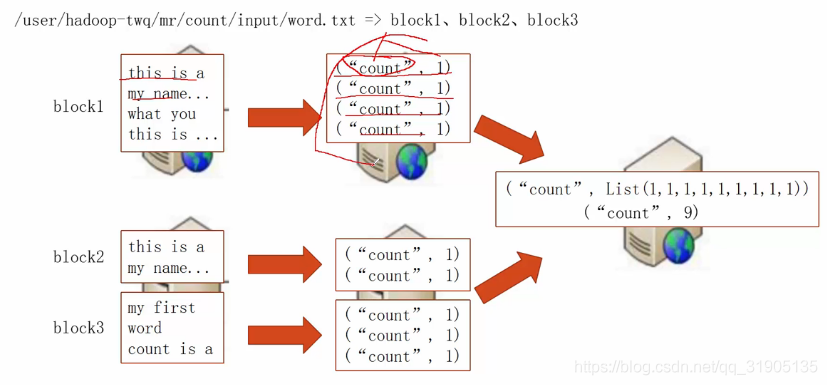
(2)项目添加mapReduce 依赖
-
-
<dependency>
-
<groupId>org.apache.hadoop</groupId>
-
<artifactId>hadoop-mapreduce-client-core</artifactId>
-
<version>2.7.5</version>
-
<dependency>
(3)编写mapReduce代码
-
package com.dzx.hadoopdemo.mapred;
-
-
import org.apache.hadoop.conf.Configurable;
-
import org.apache.hadoop.conf.Configuration;
-
import org.apache.hadoop.fs.Path;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapred.FileInputFormat;
-
import org.apache.hadoop.mapred.FileOutputFormat;
-
import org.apache.hadoop.mapred.JobConf;
-
import org.apache.hadoop.mapred.JobContext;
-
import org.apache.hadoop.mapreduce.Job;
-
import org.apache.hadoop.mapreduce.Mapper;
-
import org.apache.hadoop.mapreduce.Reducer;
-
-
import java.io.FileInputStream;
-
import java.io.FileOutputStream;
-
import java.io.IOException;
-
-
/**
-
* @author duanzhaoxu
-
* @ClassName:
-
* @Description:
-
* @date 2020年12月24日 14:28:59
-
*/
-
public class DistributeCount {
-
-
public static class ToOneMapper extends Mapper<Object, Text, Text, IntWritable> {
-
-
private final static IntWritable ONE = new IntWritable(1);
-
private Text text = new Text();
-
-
-
@Override
-
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
-
this.text.set("count");
-
context.write(this.text, ONE);
-
}
-
}
-
-
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
-
private IntWritable result = new IntWritable(0);
-
-
@Override
-
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
-
int sum = 0;
-
for (IntWritable val : values) {
-
sum += val.get();
-
}
-
result.set(sum);
-
context.write(key, result);
-
}
-
}
-
-
public static void main(String[] args) throws Exception {
-
Configuration configuration = new Configuration();
-
//创建JOB
-
Job job = Job.getInstance(configuration, "distribute-count");
-
//设置启动类
-
job.setJarByClass(DistributeCount.class);
-
//设置mapper类
-
job.setMapperClass(ToOneMapper.class);
-
// job.setCombinerClass(IntSumReducer.class);
-
//设置reduce类
-
job.setReducerClass(IntSumReducer.class);
-
//设置输出结果key类型
-
job.setOutputKeyClass(Text.class);
-
//设置输出结果value类型
-
job.setOutputValueClass(IntWritable.class);
-
JobConf jobConf = new JobConf(configuration);
-
//设置文件输入路径
-
FileInputFormat.addInputPath(jobConf, new Path(args[0]));
-
//设置结果输出文件路径
-
FileOutputFormat.setOutputPath(jobConf, new Path(args[1]));
-
//等待任务执行完成之后结束进程,设置为true会打印一些日志
-
System.exit(job.waitForCompletion(true) ? 0 : 1);
-
}
-
}
(4)执行job
将写好的mapReduce 代码打包成 mapreduce-course-1.0-SNAPSHOT.jar
准备一个较大的文本文件 big.txt 上传到 hdfs 上
hadoop fs -mkdir -p /user/hadoop-twq/mr/count/input
hadoop fs -put bih.txt /user/hadoop-twq/mr/count/input/
yarn jar mapreduce-course-1.0-SNAPSHOT.jar com.dzx.hadoopdemo.mapred.DistributeCount /user/hadoop-twq/mr/count/input/big.txt /user/hadoop-twq/mr/count/output
如图所示任务执行完成之后 会在 output 下面 生成一个文件 ,查看文件内容 里面 显示 count 21000104 ,说明big.txt 文本文件有2100多万行数据
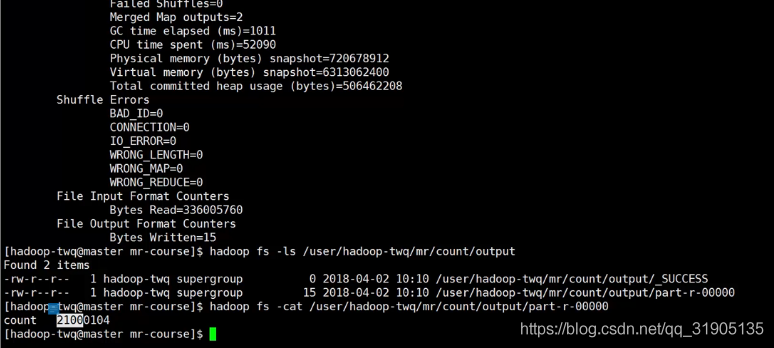
如果再次执行job,会报 输出 文件已存在的错误,要先删除原输出文件
四、block与map的input split的关系
一个block -》一个 input split
一个不足一个block大小的文件 -》 一个input split
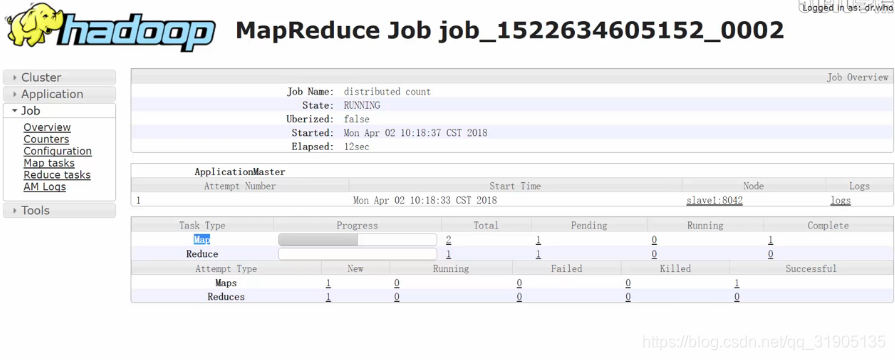
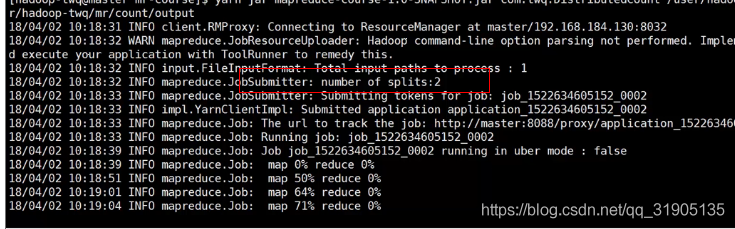
假设每个block块的大小是256M,那么一个 326M的big.txt 文件会被分成两个block存储,所以在运行job的时候,就可以在yarn监控界面上看到对应的map 任务有两个。从以下的日志输出也能看出这一点。
五、MapReduce在yarn上运行的原理
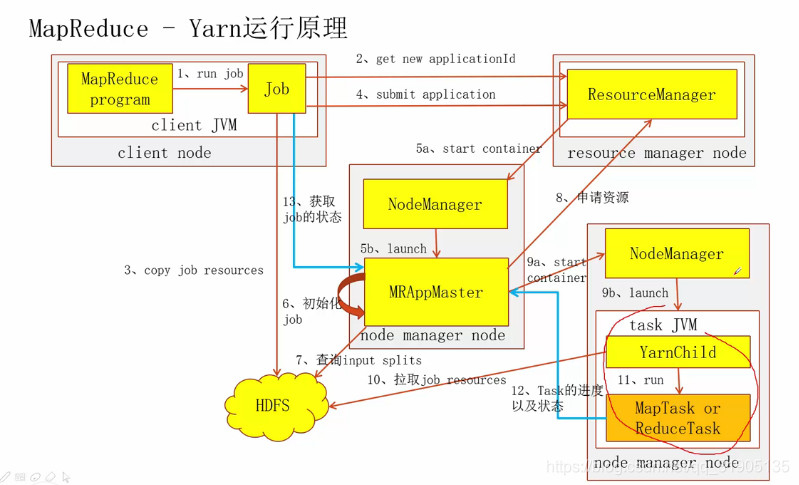
-
//设置reduce任务数
-
job.setNumReduceTasks(2)
RM代指yarn 的 ResourceManager


六、MapReduce 内存cpu资源配置
在 mapred-site.xml 增加如下配置


然后将以上 配置 同步到 slave1 和 slave2
scp mapred-site.xml hadoopq-twq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp mapred-site.xml hadoopq-twq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/
七、MapReduce 中的 Combiner
(1)Combiner 讲解
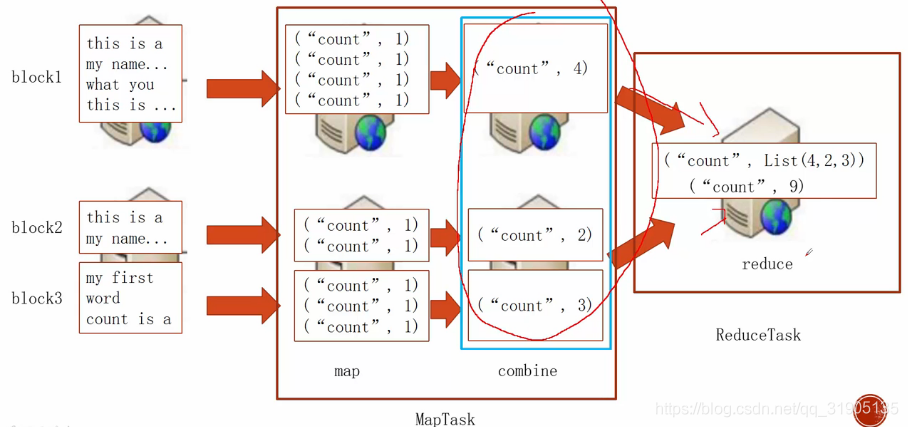
使用combiner 提前在 每台机器上面 reduce 数据,减少最终数据的网络传输,提升性能。
代码中的 实现: job.setCombinerClass(IntSumReduce.class);
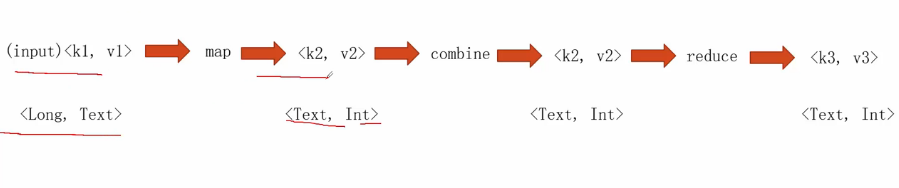
八、使用mapReduce 实现 wordCount
(1)代码编写
-
package com.dzx.hadoopdemo.mapred;
-
-
import org.apache.commons.io.FileUtils;
-
import org.apache.hadoop.conf.Configuration;
-
import org.apache.hadoop.fs.FileUtil;
-
import org.apache.hadoop.fs.Path;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapred.FileInputFormat;
-
import org.apache.hadoop.mapred.FileOutputFormat;
-
import org.apache.hadoop.mapred.JobConf;
-
import org.apache.hadoop.mapreduce.Job;
-
import org.apache.hadoop.mapreduce.Mapper;
-
import org.apache.hadoop.mapreduce.Reducer;
-
-
import java.io.File;
-
import java.io.IOException;
-
import java.util.StringTokenizer;
-
-
/**
-
* @author duanzhaoxu
-
* @ClassName:
-
* @Description:
-
* @date 2020年12月25日 11:06:53
-
*/
-
public class WordCount {
-
-
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
-
private Text text = new Text();
-
private final static IntWritable ONE = new IntWritable(1);
-
-
@Override
-
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
-
// String s = value.toString();
-
// String[] strArray = s.split(" ");
-
// for (String item : strArray) {
-
// text.set(item);
-
// context.write(text, ONE);
-
// }
-
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
-
while (stringTokenizer.hasMoreTokens()) {
-
text.set(stringTokenizer.nextToken());
-
context.write(text, ONE);
-
}
-
}
-
}
-
-
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
-
private IntWritable res = new IntWritable(0);
-
-
@Override
-
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
-
int sum = 0;
-
for (IntWritable val : values) {
-
sum += val.get();
-
}
-
res.set(sum);
-
context.write(key, res);
-
}
-
}
-
-
-
public static void main(String[] args) throws Exception {
-
File file = new File(args[1]);
-
if (file.exists()) {
-
FileUtils.deleteQuietly(file);
-
}
-
Configuration configuration = new Configuration();
-
Job job = Job.getInstance(configuration, "word-count");
-
job.setJarByClass(WordCount.class);
-
job.setMapperClass(WordCountMapper.class);
-
job.setCombinerClass(WordCountReduce.class);
-
job.setReducerClass(WordCountReduce.class);
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(IntWritable.class);
-
-
job.getConfiguration().set("yarn.app.mapreduce.am.resource.mb", "512");
-
job.getConfiguration().set("yarn.app.mapreduce.am.command-opts", "-Xmx250m");
-
job.getConfiguration().set("yarn.app.mapreduce.am.resource.cpu-vcores", "1");
-
job.getConfiguration().set("mapreduce.map.memory.mb", "400");
-
job.getConfiguration().set("mapreduce.map.java.opts", "-Xmx200m");
-
job.getConfiguration().set("mapreduce.map.cpu.vcores", "1");
-
job.getConfiguration().set("mapreduce.reduce.memory.mb", "400");
-
job.getConfiguration().set("mapreduce.reduce.java.opts", "-Xmx200m");
-
job.getConfiguration().set("mapreduce.reduce.cpu.vcores", "1");
-
-
JobConf jobConf = new JobConf(configuration);
-
FileInputFormat.addInputPath(jobConf, new Path(args[0]));
-
FileOutputFormat.setOutputPath(jobConf, new Path(args[1]));
-
System.out.println(job.waitForCompletion(true) ? 0 : 1);
-
}
-
-
-
}
将编写好的代码打成mapreduce-wordcount.jar包上传到服务器上,执行如下命令:
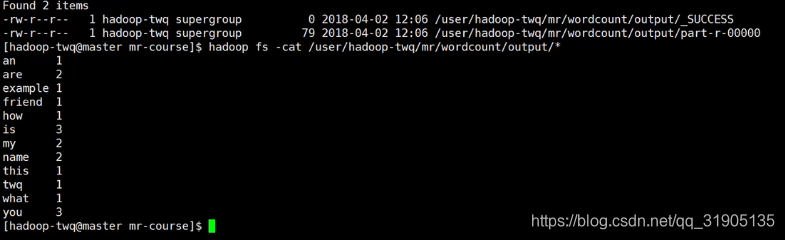
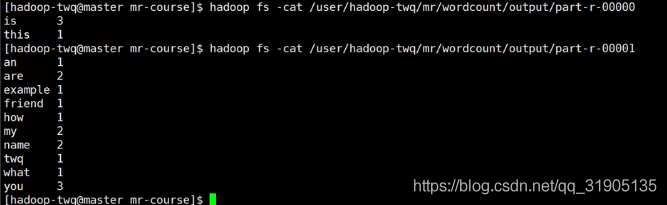
hadoop jar mapreduce-wordcount.jar com.dzx.hadoopdemo.mapred.WordCount /user/hadoop-twq/mr/count/input/big_word.txt /user/hadoop-twq/mr/count/output
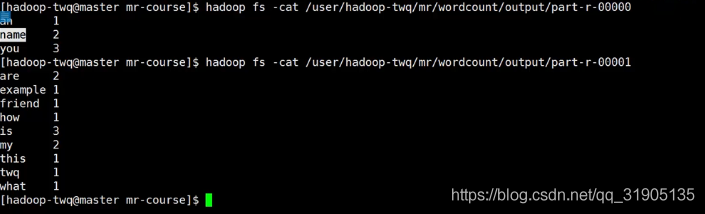
等待任务执行完成之后查看 结果输出文件,看到如下内容,说明完成了单词数量的统计
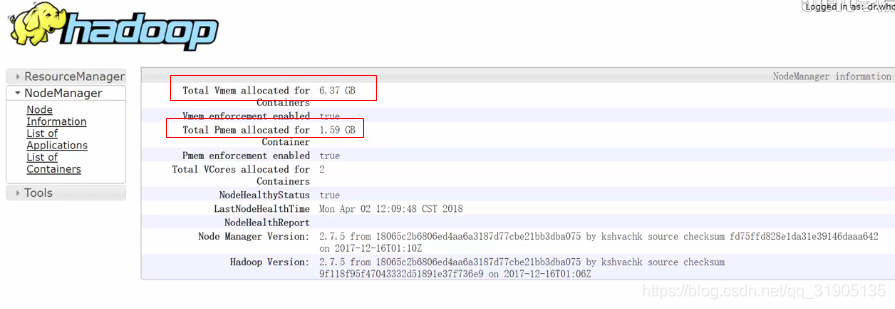
提高虚拟内存配置

重启yarn 之后可以看到 虚拟内存被放大了 4倍。
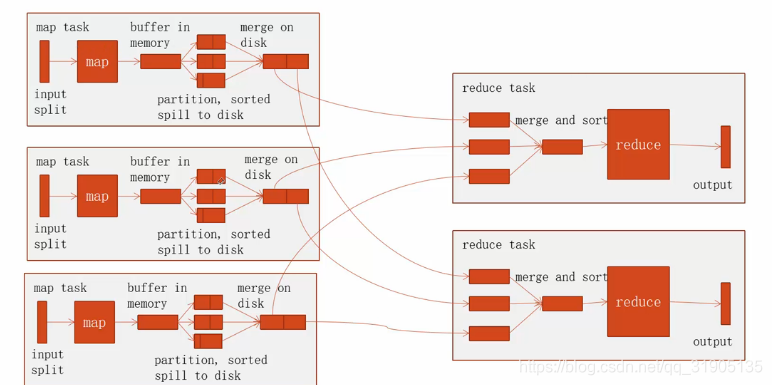
(2)word count 程序详解 - shuffle
job设置了 reduceTask 为 2 的情况下
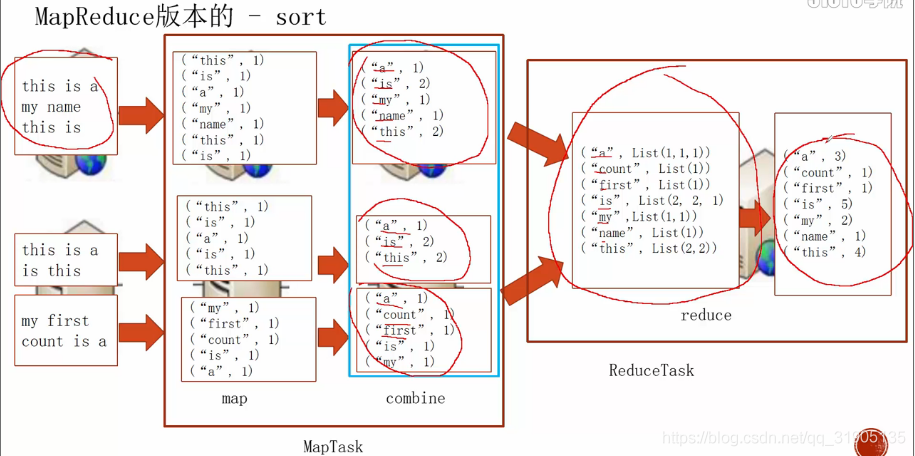
如图可看到,在maptask的 combine 阶段会将 map的结果按照 key 的 字母自然顺序进行排序。
(3)自定义分区器
在设置了 reduceTask 为2 的情况下,最终的任务输出文件会产出两个结果集文件,那么这个数据的分区是如何实现的,这里面就涉及到分区的规则 了。
hadoop 默认是按照 key 的哈希值进行分区的。
实际上就是 每个单词的hash值 对2 进行取模
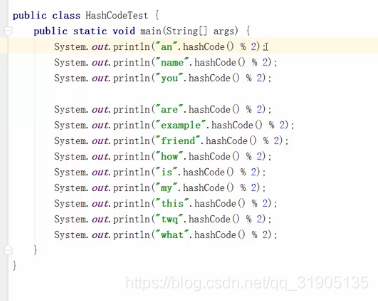
自定义分区器
-
package com.dzx.hadoopdemo.mapred;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Partitioner;
-
-
/**
-
* @author duanzhaoxu
-
* @ClassName:
-
* @Description:
-
* @date 2020年12月25日 14:34:47
-
*/
-
public class CustomPartitiner extends Partitioner<Text, IntWritable> {
-
-
-
//自定义分区器
-
@Override
-
public int getPartition(Text text, IntWritable intWritable, int i) {
-
if (text.toString().contains("s")) {
-
return 0;
-
}
-
return 1;
-
}
-
}
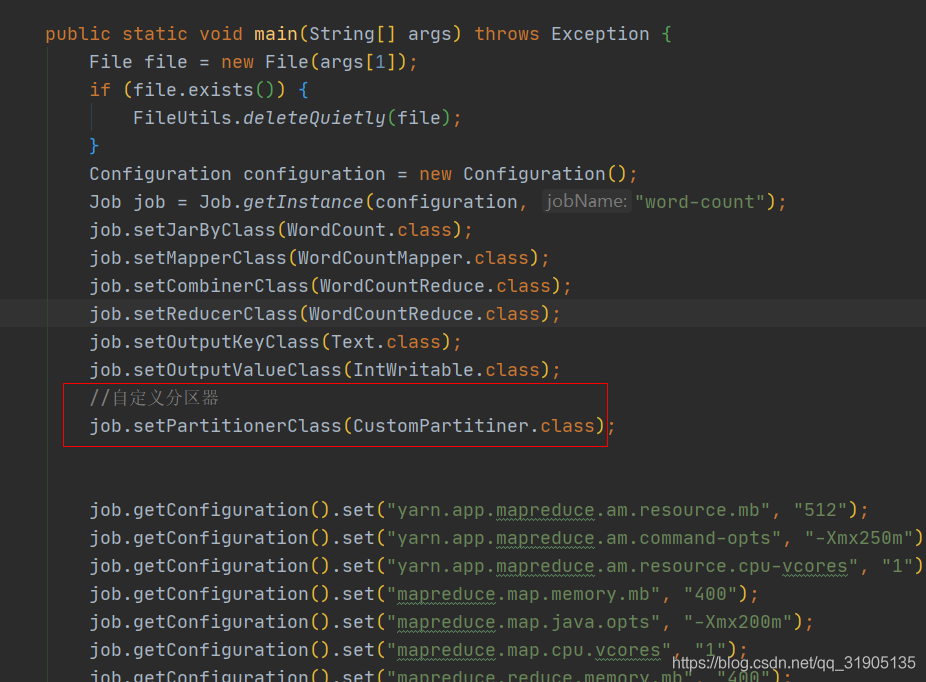
重新打包上传到服务器,运行任务,发现key包含 s的结果输出到了part0 文件,key不包含s的结果输出到part1文件。
(4)MapReduce 应用
1. distinct 问题

利用mapReduce的key天然去重,把map输入的value作为reduce的key,即可自动去重
2.distcp
将hdfs nn1 节点数据拷贝到 nn2节点
distcp hdfs://nn1:8020/source/first hdfs://nn1:8020/source/second hdfs://nn2:8020/target
九、hadoop 压缩机制
通过一定的算法对数据进行特殊编码,使得数据占用的存储空间比较小,这个过程我们称之为压缩,反之为解压缩。
不管哪种压缩工具都需要权衡时间和空间,在大数据领域内还要考虑压缩文件的可分割性
Hadoop 支持的压缩工具有 ,DEFAULT,bzip,Snappy
十、avro 行式存储 和 parquet列式存储(暂不更新)
十一、avro文件和parquet文件(重要)的读写(暂不更新)
十二、sequenceFile 文件的读写(暂不更新)
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/111608474

- 点赞
- 收藏
- 关注作者
评论(0)