NLP专栏丨情感分析方法入门上

1、情感分析任务介绍
文本情感分析(Sentiment Analysis)是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程[1]。目前,文本情感分析研究涵盖了包括自然语言处理、文本挖掘、信息检索、信息抽取、机器学习和本体学等多个领域,得到了许多学者以及研究机构的关注,近几年持续成为自然语言处理和文本挖掘领域研究的热点问题之一。从人的主观认知来讲,情感分析任务就是回答一个如下的问题“什么人?在什么时间?对什么东西?哪一个属性?表达了怎样的情感?”因此情感分析的一个形式化表达可以如下:(entity,aspect,opinion,holder,time)。比如以下文本“我觉得2.0T的XX汽车动力非常澎湃。”其中将其转换为形式化元组即为(XX汽车,动力,正面情感,我,/)。需要注意的是当前的大部分研究中一般都不考虑情感分析五要素中的观点持有者和时间。
情感分析问题可以划分为许多个细分的领域,下面的思维导图[2]展示了情感分析任务的细分任务:
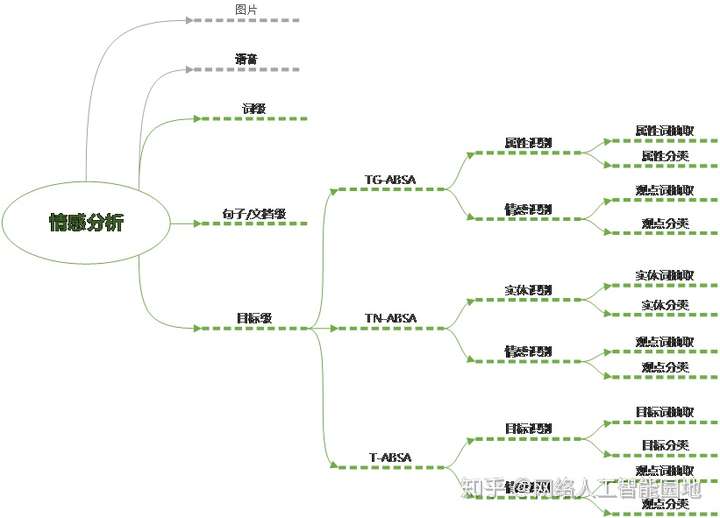
其中词级别和句子级别的分析对象分别是一个词和整个句子的情感正负向,不区分句子中具体的目标,如实体或属性,相当于忽略了五要素中的实体和属性这两个要素。词级别情感分析,即情感词典构建,研究的是如何给词赋予情感信息。句子级/文档级情感分析研究的是如何给整个句子或文档打情感标签。而目标级情感分析是考虑了具体的目标,该目标可以是实体、某个实体的属性或实体加属性的组合。具体可分为三种:Target-grounded aspect based sentiment analysis (TG-ABSA), Target no aspect based sentiment analysis (TN-ABSA), Target aspect based sentiment analysis (T-ABSA). 其中TG-ABSA的分析对象是给定某一个实体的情况下该实体给定属性集合下的各个属性的情感分析;TN-ABSA的分析对象是文本中出现的实体的情感正负向;T-ABSA的分析对象是文本中出现的实体和属性组合。下表例举了不同目标的情感分析任务:
| 任务粒度 | 文本 | 情感 |
| 词级 | 中奖 | 正向 |
| 句子/文档级 | 这家外卖分量足,味道好。 | 正向 |
| 目标级(TG-ABSA) | 2.0T涡轮增压发动机动力强,高速120超车没压力;外观是我和老婆都比较喜欢的款;后排空间有点小;有点费油啊。 | 动力:正向外观:正向空间:负向油耗:负向 |
| 目标级(TN-ABSA) | 丰田汽车比别克汽车更耐用。 | 丰田:正向别克:负向 |
| 目标级(T-ABSA) | 三星手机外观漂亮,苹果手机系统流畅。 | 三星外观:正向苹果系统:正向 |
2、情感分析常用文本预处理方法
2.1中文分词技术
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。研究表明特征粒度为词粒度远远好于字粒度,其大部分分类算法不考虑词序信息,基于字粒度的损失了过多的n-gram信息。
中文分词主要分为两类方法:基于词典的中文分词和基于统计的(HMM,CRF)中文分词。举个例子:“网商银行是蚂蚁金服微贷事业部的最重要产品”,其对应的分词结果为:网商银行/是/蚂蚁金服/微贷事业部/的/最重要/产品。
当前我们讨论的分词算法可分为两大类:基于字典、词库匹配的分词方法;基于词频度统计(HMM,CRF)的分词方法。第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
当前中文分词技术已经非常成熟,下表[3]展示了当前业界主流的分词服务支持的功能:

2.2去除停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。
2.3 文本特征提取
2.3.1 Bag of words
BoW模型最初应用于文本处理领域,用来对文档进行分类和识别。其核心思想是建立一个词典库,该词典库包含训练语料库的所有词语,每个词语对应一个唯一识别的编号,利用one-hot文本表示。文档的词向量维度与单词向量的维度相同,每个位置的值是对应位置词语在文档中出现的次数,即词袋模型(BOW)BoW 模型因为其简单有效的优点而得到了广泛的应用。如下示例,给定两句简单的文档:
文档 1:“我喜欢跳舞,小明也喜欢。”
文档 2:“我也喜欢唱歌。”
基于以上这两个文档,便可以构造一个由文档中的关键词组成的词典:
词典={1:“我”,2:“喜欢”,3:“跳舞”,4:“小明”,5:“也”,6:“唱歌”}
这个词典一共包含6个不同的词语,利用词典的索引号,上面两个文档每一个都可以用一个6维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数。这样,根据各个文档中关键词出现的次数,便可以将上述两个文档分别表示成向量的形式:
文档 1:[1, 2, 1, 1, 1, 0]
文档 2:[1, 1, 0, 0, 1, 1]
通过上面的例子可以看出,虽然BOW模型理解和实行起来简单,但是他有以下缺点问题:
(1)容易引起维度灾难问题,语料库太大,字典的大小为每个词的维度,高维度导致计算困难,每个文档包含的词语数少于词典的总词语数,导致文档稀疏。(2)仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑。
2.3.2 TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。TF-IDF的主要思想是:如果某个词或短语在一篇文章(句子)中出现的频率TF高,并且在其他文章(句子)中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。其中其计算方法如下:



如下示例可以清楚说明TF-IDF的计算方法:
- 假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。
- 一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000+1)=4。
- 最后的TF-IDF的分数为0.03 * 4=0.12。
2.3.3 预训练模型
当我们用机器学习或者深度学习方法来处理NLP任务时,为了使自然语言成为计算机可以读懂的语言,首先我们需要对文本进行编码。在编码时,我们期望句子之间保持词语间的相似行,词的向量表示是进行机器学习和深度学习处理NLP任务的基础。由此也催生了各种各样的预训练模型发展,同时预训练加模型微调(Pre-training and fine tuning)的方法也是当前NLP领域各种任务state-of-art的方法的基本流程。预训练的方法最初是在图像领域提出的,达到了良好的效果,后来被应用到自然语言处理。预训练一般分为两步,首先用某个较大的数据集训练好模型(这种模型往往比较大,训练需要大量的内存资源),使模型训练到一个良好的状态,然后下一步根据不同的任务,改造预训练模型,用这个任务的数据集在预训练模型上进行微调。这种做法的好处是训练代价很小,预训练的模型参数可以让新的模型达到更快的收敛速度,并且能够有效地提高模型性能,尤其是对一些训练数据比较稀缺的任务,在神经网络参数十分庞大的情况下,仅仅依靠任务自身的训练数据可能无法训练充分,预训练方法可以认为是让模型基于一个更好的初始状态进行学习,从而能够达到更好的性能。
预训练模型的发展也反映了深度学习在NLP领域的进步。NLP领域的预训练模型大致可以分为以下两类:
- 基于词嵌入的预训练方法
2003年,Bengio等人提出了神经语言模型(Neural Network Language Model)[4],神经语言模型在训练过程中,不仅学习到预测下一个词的概率分布,同时也得到了一个副产品:词嵌入表示。相比随机初始化的词嵌入,模型训练完成后的词嵌入已经包含了词汇之间的信息。2013年,Mikolov等人提出了word2vec工具,其中包含了CBOW(Continue Bag of Words)模型和Skip-gram模型[5-6],该工具仅仅利用海量的单语数据,通过无监督的方法训练得到词嵌入,在很长一段时间内word2vec在各种任务中都被广泛使用。
- 基于语言模型的预训练方法
词嵌入本身具有局限性,最主要的缺点是无法解决一词多义问题,即不同的词在不同的上下文中会有不同的意思,但是词嵌入对模型中的每个词都分配了一个固定的表示。针对上述问题,Peters等人提出了ELMo(Embedding from Language Model)[7],即使用语言模型来获取深层的上下文表示。ELMo的具体做法是,基于每个词所在的上下文,利用双向LSTM的语言模型来获取这个词的表示。ELMo的方法能够提取丰富的特征给下游任务使用,但是ELMo仅仅进行特征提取而没有预训练整个网络,远远没有发挥预训练的潜力。针对上述两个问题,Radford等人提出了 GPT Generative Pre-Training)[8],即生成式的预训练。GPT将LSTM换成了Transformer,获得了更高的成绩,但是由于使用的是单向模型,只能通过前面词预测后面的词,可能会遗漏信息。Devlin等人提出了BERT(Bidirectional Encoder Representations from Transformers)[9],即基于Transformer的双向编码器表示。BERT和GPT的结构和方法十分相似,最主要的不同之处在于GPT模型使用的是单向语言模型,可以认为是基于Transformer的解码器表示,而BERT使用的基于Transformer的编码器能够对来自过去和未来的信息进行建模,能够提取更丰富的信息。三个预训练模型的图如下所示:
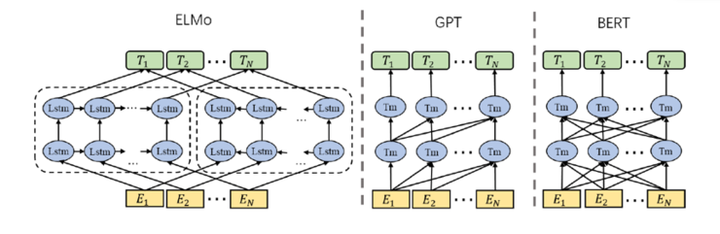
BERT提出后大火,也许是因为BERT的效果太好。目前绝大多数的预训练模型都是在BERT上改造而来。清华大学的王晓智和张正彦同学给出了目前的预训练模型关系图,这里引用一下,如下图所示:

总结
本篇博文主要介绍了情感分析任务的概述以及进行情感分析任务之前我们需要进行的准备工作,其中着重介绍了NLP领域最重要的预训练模型的主要里程碑。下一篇博文将着重介绍进行情感分析任务的具体方法,包括传统基于统计的方法和深度学习方法。
参考文献
- PANG B,LEE L. Opinion mining and sentiment analysis[J].Foundations and Trends in InformationRetrieval,2008,2 (1 -2) :130 - 135.
- https://www.infoq.cn/article/XGoSsRfZRSupblTGGJCM
- https://blog.csdn.net/fendouaini/article/details/82027310
- Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model.
- Mikolov T, Chen K, Corrado G S, et al. Efficient Estimation of Word Representations in Vector Space.
- Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality.
- Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep Contextualized Word Representations.
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.

- 点赞
- 收藏
- 关注作者
评论(0)