【Akka系列】之 Akka和Actors在Flink中的应用

本文翻译自https://cwiki.apache.org/confluence/display/FLINK/Akka+and+actors
Akka和Actors
本页讨论了
Flink 0.9版本采用的Akka分布式通信的实现。有了Akka,所有的远程过程调用(RPC)被实现成异步消息。这主要影响了JobManager、TaskManager和JobClient三个组件。未来,很可能更多的组件将被转换成一个actor,使它们可以发送和处理异步消息。
Akka和Actor Model
Akka是一个开发并发、容错和可伸缩应用的框架。它是Actor Model的一个实现,因此和Erlang的并发模型很像。在Actor模型中,所有的实体被认为是独立的actors。actors和其他actors通过发送异步消息通信。Actor模型的强大来自于异步(asynchronism)。它也可以显式等待响应,这使得可以执行同步(synchronous)操作。但是,强烈不建议同步消息,因为它们限制了系统的伸缩性(scalability)。每个actor有一个邮箱(mailbox),它收到的消息存储在里面。另外,每一个actor维护自身单独的状态.。一个Actors网络如下所示:
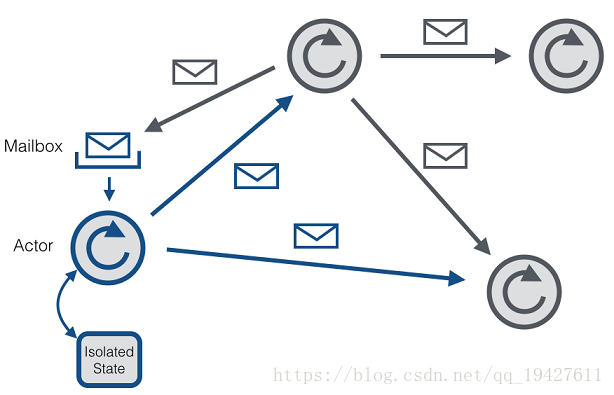
每个actor有且只有一个“处理线程”轮询(poll)自己的邮箱,并且连续地处理收到的消息。处理一条消息后,actor可以改变它的内部状态,发送新的消息,或者产生新的actors。如果一个actor的内部状态只被它的处理线程改变,那么无需确保actor的状态是线程安全的。即使每个actor自身是有序的,但是一个由多个actor组成的系统是高并发和可伸缩的,因为各个处理线程在所有actors之间共享。这也是为什么我们不应该在一个actor线程内调用“阻塞调用”。这会阻塞正被其他actors使用并处理各自消息的线程。
Actor Systems
一个Actor系统是所有actors存在的容器。它提供了共享的服务,如调度、配置和日志等。Actor系统也包含一个产生所有actors线程的线程池。多个Actor系统可以存在于同一台机器上。如果Actor系统开始于RemoteActorRefProvider,那么它可以被可能存在于另有一台机器上的Actor系统访问。Actor系统自动识别actor消息被一个同系统内的actor处理还是远程的Actor系统。在本地通信中,消息通过共享内存被有效地传输。在远程通信中,消息通过网络栈被发送。
所有的actors被层次化组织。每个新创建的actor将创建它的actor作为父actor。层级被用于监督。每个父actor有义务监督它的子actor。如果它的某个子actor产生一个error,它会被通知。如果它可以解决这个问题,那么它可以继续或重启这个子actor。如果该问题超出它的处理能力范围,它可以将error向上传播给自己的父actor。传播一个error仅意味着当前层以上的层级现在负责解决这个问题。关于Akka监督和管理的细节可以在这里找到。
系统创建的第一个actor由系统提供的guardian actor/user 监管。关于Actor层级更深入的解释参阅这里。更多关于Actor系统的详细信息参阅这里。
Actors in Flink
一个actor是一个自身状态和行为的容器。它的actor线程连续处理收到的消息。这减轻了用户编写易出错的锁和线程管理任务,因为每个actor每一时刻只有一个线程是活动的。然而,必须保证一个actor的内部状态只被这个actor线程访问。一个actor的行为由一个接收函数定义,这个函数包含一个收到每条消息时被执行的逻辑。
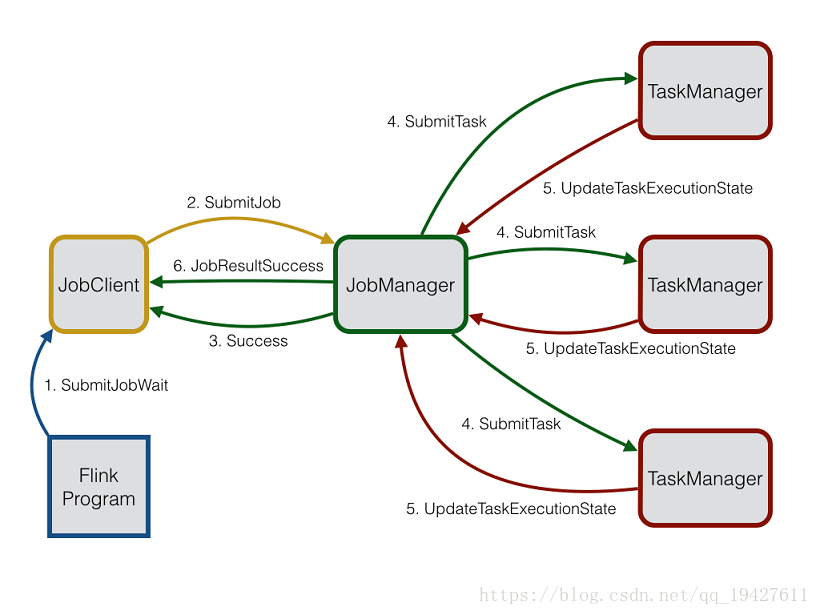
Flink系统由三个分布式通信组件组成:JobClient、JobManager、TaskManager。JobClient接收一个来自用户的Flink作业并提交给JobManager。JobManager然后负责协调作业的执行。首先,它分配需要的资源。这主要包括TaskManagers上的运行slots。资源分配后,JobManager部署作业的各个tasks到各个TaskManagers。一收到task,TaskManager创建一个执行该task的线程。状态的改变,例如开始计算或完成计算,被发送回JobManager。JobManager基于状态更新控制作业执行直到完成。一旦作业完成,结果将被发送到JobClient,由它告知用户运行结果。作业执行过程如下图所示:
JobManager & TaskManager
JobManager是负责执行一个Flink作业的中央控制单元。同样地,它管理资源分配、任务调度和状态报告。在任何Flink作业可以被执行前,一个JobManager和至少一个TaskManager必须被启动。TaskManager然后发送一个RegisterTaskManager消息到JobManager注册自己。JobManager发送一条注册成功的确认消息。如果TaskManager已经在JobManager注册过了,因为有多条RegisterTaskManager消息被发送,JobManager返回一条AlreadyRegistered消息。如果注册被拒绝,JobManager将发送一条RefuseRegistration消息。
通过发送一条附带相应JobGraph的SubmitJob消息提交一个作业给JobManager。一收到JobGraph,JobManager基于JobGraph创建一个ExecutionGraph,它是分布式执行的逻辑表示。ExecutionGraph包含了会被部署到TaskManagers执行的tasks的相关信息。
JobManager的调度器负责在可用的TaskManagers上分配运行slots。在一个TaskManager上分配一个运行slot后,一条附带所有执行task必要信息的SubmitTask消息被发送到该TaskManager。TaskManager发送一条TaskOperationResult消息确认task部署成功。一旦已提交作业的源码被部署和执行,则作业提交成功。JobManager发送一条附带相应作业Id的Success消息通知JobClient作业提交成功。
运行在TaskManagers上的每个task的状态更新通过UpdateTaskExecutionState消息发送回JobManager。有了这些更新消息,ExecutionGraph可以被更新以反映执行的当前状态。
JobManager也作为数据源的输入分片器(input split assigner)。它负责向所有TaskMangers分配任务,以便尽可能保证数据本地性(data locality)。为了动态平衡负载,tasks处理完上一个数据分片(input split)后请求一个新的数据分片。这个请求通过发送一条RequestNextInputSplit给JobManager实现。JobManager返回一条NextInputSplit消息响应。如果没有更多的数据分片,包含在JobManager返回消息中的数据分片为null。
tasks被延迟部署在TaskManagers上。这意味着消费数据的tasks会在它的一个数据生产者(producer)产生数据后被部署。一旦生产者产生数据完成,它发送一条ScheduleOrUpdateConsumers消息给JobManager。这条消息表明消费者(consumer)现在可以读取新产生的数据。如果消费数据的task还没有启动,它将被部署到一个TaskManager上。
JobClient
JobClient代表分布式系统中面向用户的组件。它用于和JobManager通信,并且负责提交Flink作业、查询已提交作业的状态和接收运行中作业的状态信息。
JobClient也是一个通过消息通信的actor。存在两种和作业提交相关的消息:SubmitJobDetached和SubmitJobWait。第一个消息提交一个作业并且取消用于接收任何状态消息和最终作业结果的注册。如果你想以一种发送并忽略(fire and forget)的方式提交你的作业到Flink集群, 分离模式(detached mode)很有用。第二种消息提交一个作业并注册以接收这个作业的状态消息。在内部,这通过创建一个helper actor作为状态消息的接收者而实现。一旦作业终止,JobManager发送一个附带运行时长和累计结果的JobResultSuccess消息给helper actor。当收到这个消息的时候,helper actor将这个消息转发给发送SubmitJobWait消息的JobClient,然后终止。
Asynchronous VS. Synchronous Messages
在可能的情况下,Flink试图使用异步消息并将响应作为Futures处理。Futures和很少已存的阻塞调用有一个timeout,在timeout之后的操作被认为失败。这避免了在一条消息丢失或一个分布式组件崩溃的情况下系统产生死锁。然而,如果你正好有一个很大的集群或一个很慢的网络,timeouts或许会被错误的触发。因此,这些操作的timeout可以修改在配置 “akka.ask.timeout”中修改。
在一个actor可以和另一个actor通信前,它必须查找(retrieve)得到一个ActorRef。这个操作的查找也需要一个timeout。如果一个actor没有启动,为了使系统快速失败,查找的timeout被设置成一个比常规timeout更小的值。在查找timeout的情况下,你可以在配置“akka.lookup.timeout”中增加查找timeout。
Akka的另一个特点是设置了一个它可发送消息大小的最大值限制。原因是它保留了一个同样大小的序列化buffer并且它不想浪费内存。如果你遇到一个消息超出最大值的传输错误,你可以在配置“akka.framesize”中增大帧大小(framesize)。
Failure Detection
一个分布式系统中失败检测对于它的鲁棒性(robustness)很重要。当在一个商用集群上运行的时候,分布式系统总会遇到一些组件失败或者不可达。这样一个失败的原因是多种多样的,可以是从硬件故障到网络中断。一个健壮的(robust)分布式系统应当能够检测失败组件并恢复它。
Flink通过Akka的DeathWatch机制检测失败组件。DeathWatch允许actors监视其他actors,即使它们不受这个actor监督或者甚至它们属于另一个actor系统。一旦一个被监视的actor死掉或是不可达,一个终止消息会被发送给这个actor的监视者。因此,一收到这个消息,系统可以对这个actor采取相应措施。在内部,DeathWatch被实现成心跳(heartbeat)和一个基于心跳间隔、心跳暂停、心跳阈值的失败检测器,它判断一个actor什么时候很可能是dead。心跳间隔可以在配置“akka.watch.heartbeat.interval”中设置。可接受的心跳暂停可以通过配置“akka.watch.heartbeat.pause”确定。心跳暂停应当是心跳间隔的几倍,否则一个丢失的心跳会直接触发DeathWatch。失败(心跳)阈值可以通过配置“akka.watch.threshold”确定,并且它有效地控制失败检测器的敏感度。更多关于DeathWatch机制和失败检测器的细节可以参阅这里。
在Flink中,JobManager监视所有已注册的TaskManagers并且所有的TaskManagers监视JobManager。这样,两类组件都知道什么时候另一个组件是不可达的。某个TaskManager不可达的时候,JobManager会将这个不能部署tasks的TaskManager标记为dead。另外,JobManager使运行在这个TaskManager上的所有tasks失败,并且在另一个TaskManager上重新调度执行这些tasks。TaskManager在由于临时连接丢失开而被标记为dead的情况下,当连接重新建立的时候,它可以向JobManager重新注册自己。TaskManager也监视JobManager。这个监视允许TaskManager检测到JobManager失败的时候通过使所有正在运行的tasks失败而进入一个清洁的(clean)状态。另外,在只是由于网络拥塞或连接丢失而触发的death情况下,TaskManager将试图重新连接JobManager。
Future Development
当前只有三个组件:JobClient、JobManager和TaskManager被实现成actor。为了更好的实现并发性以提高伸缩性,可以将更多的组件实现成actors。一个有希望的候选者是ExecutionGraph,它的ExecutionVertices或者其相关联的Execution对象也可以实现成一个actor。这样一个细粒度的Actor模型将有利于状态更新直接发送各自的Execution对象。这样的话,JobManger将显著地从作为单一的通信节点中解放出来。
Configuration
akka.ask.timeout:用于所有Futures和阻塞的Akka调用的timeout。如果Flink由于timeouts而失败,那么你应该增大这个值。timeouts可以由运行慢的机器或者拥塞的网络造成。timeout值需要时间单元标识符(ms/s/min/h/d) ( 默认:100s )akka.lookup.timeout:用于JobManager查找的timeout。timeout值需要时间单元区分符(ms/s/min/h/d)( 默认:10s )akka.framesize:JobManager和TaskManager之间发送的消息大小的最大值。如果Flink由于消息大小超出这个限制而失败,那么你应该增大这个值。消息大小需要消息单元标识符。( 默认:10485760b )akka.watch.heartbeat.interval:Akka检测deadTaskManager的DeathWatch机制的时间间隔。如果TaskManagers由于丢失或延迟的心跳消息而错误地被标记为dead,那么你应该增大这个值。一个关于Akka的DeathWatch的详细介绍可以在这里找到。(默认:akka.ask.timeout/10)akka.watch.heartbeat.pause:Akka的DeathWatch机制可接受的心跳暂停值。一个较低的值不允许一个无规律的心跳。一个关于Akka的DeathWatch机制的详细介绍可以在这里找到。(默认:akka.ask.timeout)akka.watch.threshold:DeathWatch失败检测器的阈值。一个较低的值容易产生错误的判断,反之,一个较大的值增加了检测到deadTaskManager的时间。一个关于Akka的DeathWatch机制的详细介绍可以在这里找到。(默认:12)

- 点赞
- 收藏
- 关注作者
评论(0)