pandas将list数据拆分成行或列的实现

【摘要】 数据1234567 import numpy as npimport pandas as pd data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]}, {'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]data = pd.DataFrame(d...
数据
|
1
2
3
4
5
6
7
|
import numpy as np
import pandas as pd
data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
data
|
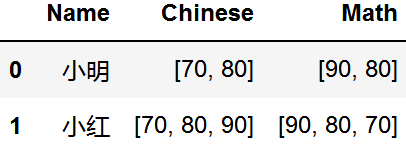
拆分成行
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def split_row(data, column):
'''拆分成行
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
row_len = list(map(len, data[column].values))
rows = []
for i in data.columns:
if i == column:
row = np.concatenate(data[i].values)
else:
row = np.repeat(data[i].values, row_len)
rows.append(row)
return pd.DataFrame(np.dstack(tuple(rows))[0], columns=data.columns)
split_row(data, column='Chinese')
|
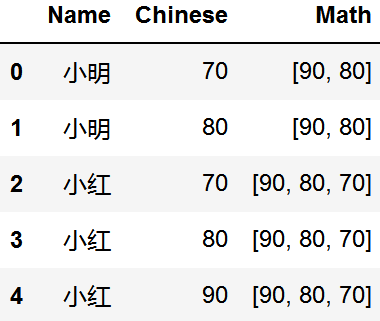
拆分成列

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from copy import deepcopy
def split_col(data, column):
'''拆分成列
:param data: 原始数据
:param column: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type column: str
'''
data = deepcopy(data)
max_len = max(list(map(len, data[column].values))) # 最大长度
new_col = data[column].apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[column + str(i)] = j
return data
split_col(data, column='Chinese')
|
其他情况
1. 批量处理+不要原列

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(len, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x + [None]*(max_len - len(x))) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data
|
2. 带int和list数据
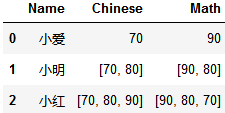
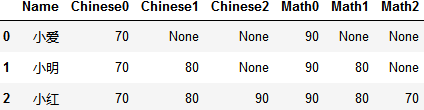
转成这样:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import numpy as np
import pandas as pd
data = [{'Name': '小爱', 'Chinese': 70, 'Math': 90},
{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
def split_col(data, columns):
'''拆分成列
:param data: 原始数据
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(lambda x:len(x) if isinstance(x, list) else 1, new_col.values))) # 最大长度
new_col = new_col.apply(lambda x: x+[None]*(max_len - len(x)) if isinstance(x, list) else [x]+[None]*(max_len - 1)) # 补空值,None可换成np.nan
new_col = np.array(new_col.tolist()).T # 转置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data
|

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)