最强Spark内存管理剖析,值得收藏~

今天和大家介绍Spark的内存模型,干货多多,不要错过奥~
与数据频繁落盘的Mapreduce引擎不同,Spark是基于内存的分布式计算引擎,其内置强大的内存管理机制,保证数据优先内存处理,并支持数据磁盘存储。
本文将重点探讨Spark的内存管理是如何实现的,内容如下:
-
Spark内存概述 -
Spark 内存管理机制 -
Spark on Yarn模式的内存分配
1 Spark内存概述
首先简单的介绍一下Spark运行的基本流程。
-
用户在 Driver端提交任务,初始化运行环境(SparkContext等) -
Driver根据配置向 ResoureManager申请资源(executors及内存资源) -
ResoureManager资源管理器选择合适的 worker节点创建executor进程 -
Executor向Driver注册,并等待其分配task任务 -
Driver端完成 SparkContext初始化,创建DAG,分配taskset到Executor上执行。 -
Executor启动线程执行task任务,返回结果。
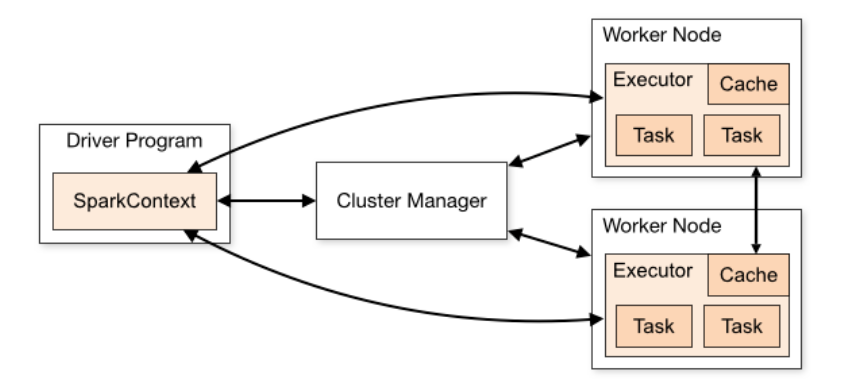
Spark在任务运行过程中,会启动Driver和Executor两个进程。其中Driver进程除了作为Spark提交任务的执行节点外,还负责申请Executor资源、注册Executor和提交Task等,完成整个任务的协调调度工作。而Executor进程负责在工作节点上执行具体的task任务,并与Driver保持通信,返回结果。
由上可见,Spark的数据计算主要在Executor进程内完成,而Executor对于RDD的持久化存储以及Shuffle运行过程,均在Spark内存管理机制下统一进行,其内运行的task任务也共享Executor内存,因此本文主要围绕Executor的内存管理进行展开描述。
Spark内存分为堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。其中堆内内存基于JVM内存模型,而堆外内存则通过调用底层JDK Unsafe API。两种内存类型统一由Spark内存管理模块接口实现。
def acquireStorageMemory(...): Boolean //申请存储内存
def acquireExecutionMemory(...): Long //申请执行内存
def releaseStorageMemory(...): Unit //释放执行内存
def releaseStorageMemory(...): Unit //释放存储内存
1.1 Spark的堆内内存
Executo作为一个JVM进程,其内部基于JVM的内存管理模型。
Spark在其之上封装了统一的内存管理接口MemoryManager,通过对JVM堆空间进行合理的规划(逻辑上),完成对象实例内存空间的申请和释放。保证满足Spark运行机制的前提下,最大化利用内存空间。

这里涉及到的
JVM堆空间概念,简单描述就是在程序中,关于对象实例|数组的创建、使用和释放的内存,都会在JVM中的一块被称作为"JVM堆"内存区域内进行管理分配。
Spark程序在创建对象后,JVM会在堆内内存中
分配一定大小的空间,创建Class对象并返回对象引用,Spark保存对象引用,同时记录占用的内存信息。
Spark中堆内内存参数有: -executor-memory或-spark-executor-memory。通常是任务提交时在参数中进行定义,且与-executor-cores等相关配置一起被提交至ResourceManager中进行Executor的资源申请。
在Worker节点创建一定数目的Executor,每个Executor被分配
-executor-memory大小的堆内内存。Executor的堆内内存被所有的Task线程任务共享,多线程在内存中进行数据交换。
Spark堆内内存主要分为Storage(存储内存)、Execution(执行内存)和Other(其他) 几部分。
-
Storage用于缓存RDD数据和broadcast广播变量的内存使用 -
Execution仅提供shuffle过程的内存使用 -
Other提供Spark内部对象、用户自定义对象的内存空间
Spark支持多种内存管理模式,在不同的管理模式下,以上堆内内存划分区域的占比会有所不同,具体详情会在第2章节进行描述。
1.2 Spark的堆外内存
Spark1.6在堆内内存的基础上引入了堆外内存,进一步优化了Spark内存的使用率。
其实如果你有过Java相关编程经历的话,相信对堆外内存的使用并不陌生。其底层调用
基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等。
Spark在2.x之后,摒弃了之前版本的Tachyon,采用Java中常见的基于JDK Unsafe API来对堆外内存进行管理。此模式不在JVM中申请内存,而是直接操作系统内存,减少了JVM中内存空间切换的开销,降低了GC回收占用的消耗,实现对内存的精确管控。
堆外内存默认情况下是不开启的,需要在配置中将spark.memory.offHeap.enabled设为True,同时配置spark.memory.offHeap.size参数设置堆大小。
对于堆外内存的划分,仅包含Execution(执行内存)和Storage(存储内存)两块区域,且被所有task线程任务共享。
2 Spark内存管理机制
前文说到,不同模式下的Spark堆内、堆外内存区域划分占比是不同的。
在Spark1.6之前,Spark采用的是静态管理(Static Memory Manager)模式,Execution内存和Storage内存的分配占比全部是静态的,其值为系统预先设置的默认参数。
在Spark1.6后,为了考虑内存管理的动态灵活性,Spark的内存管理改为统一管理(Unified Memory Manager)模式,支持Storage和Execution内存动态占用。至于静态管理方式任然被保留,可通过spark.memory.useLegacyMode参数启用。
2.1 静态内存管理(Static Memory Manager)
Spark最原始的内存管理模式,默认通过系统固定的内存配置参数,分配相应的Storage、Execution等内存空间,支持用户自定义修改配置。
1. 堆内内存分配
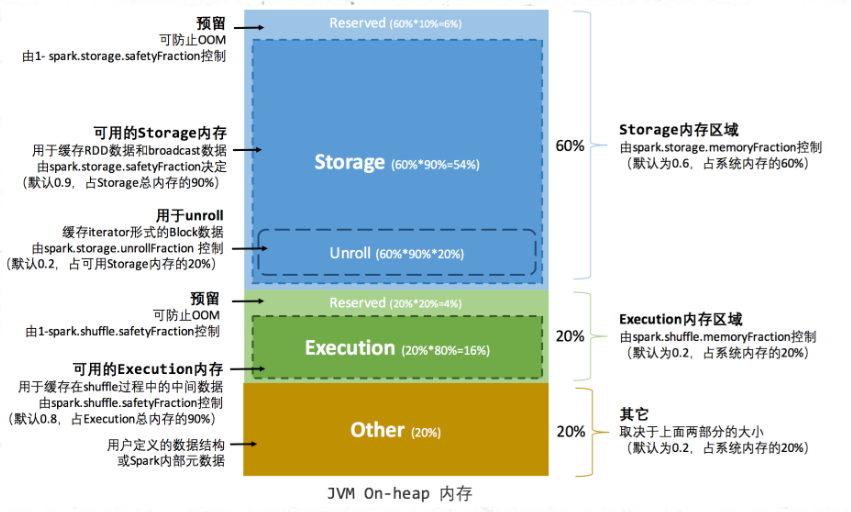
堆内内存空间整体被分为Storage(存储内存)、Execution(执行内存)、Other(其他内存)三部分,默认按照6:2:2的比率划分。其中Storage内存区域参数: spark.storage.memoryFraction(默认为0.6),Execution内存区域参数: spark.shuffle.memoryFraction(默认为0.2)。Other内存区域主要用来存储用户定义的数据结构、Spark内部元数据,占系统内存的20%。
在Storage内存区域中,10%的大小被用作Reserved预留空间,防止内存溢出情况,由参数: spark.shuffle.safetyFraction(默认0.1)控制。90%的空间当作可用的Storage内存,这里是Executor进行RDD数据缓存和broadcast数据的内存区域,参数和Reserved一致。还有一部分Unroll区域,这一块主要存储Unroll过程的数据,占用20%的可用Storage空间。
Unroll过程:
RDD在缓存到内存之前,partition中record对象实例在堆内other内存区域中的不连续空间中存储。RDD的缓存过程中, 不连续存储空间内的partition被转换为连续存储空间的Block对象,并在Storage内存区域存储,此过程被称作为Unroll(展开)。
Execution内存区域中,20%的大小被用作Reserved预留空间,防止OOM和其他内存不够的情况,由参数: spark.shuffle.safetyFraction(默认0.2)控制。80%的空间当作可用的Execution内存,缓存shuffle过程的中间数据,参数: spark.shuffle.safetyFraction(默认0.8)。
计算公式
可用的存储内存 =
systemMaxMemory
* spark.storage.memoryFraction
* spark.storage.safetyFraction
可用的执行内存 =
systemMaxMemory
* spark.shuffle.memoryFraction
* spark.shuffle.safetyFraction
2. 堆外内存

相较于堆内内存,堆外内存的分配较为简单。堆外内存默认为384M,由系统参数spark.yarn.executor.memoryOverhead设定。整体内存分为Storage和Execution两部分,此部分分配和堆内内存一致,由参数: spark.memory.storageFaction决定。堆外内存一般存储序列化后的二进制数据(字节流),在存储空间中是一段连续的内存区域,其大小可精确计算,故此时无需设置预留空间。
3. 总结
-
实现机制简单,易理解 -
容易出现内存失衡的问题,即Storage、Execution一方内存过剩,一方内容不足 -
需要开发人员充分了解存储机制,调优不便
更多细节讨论,欢迎添加我的个人微信: youlong525
2.2 统一内存管理(Unified Memory Manager)
为了解决(Static Memory Manager)静态内存管理的内存失衡等问题,Spark在1.6之后使用了一种新的内存管理模式—Unified Memory Manager(统一内存管理)。在新模式下,移除了旧模式下的Executor内存静态占比分配,启用了内存动态占比机制,并将Storage和Execution划分为统一共享内存区域。
1. 堆内内存
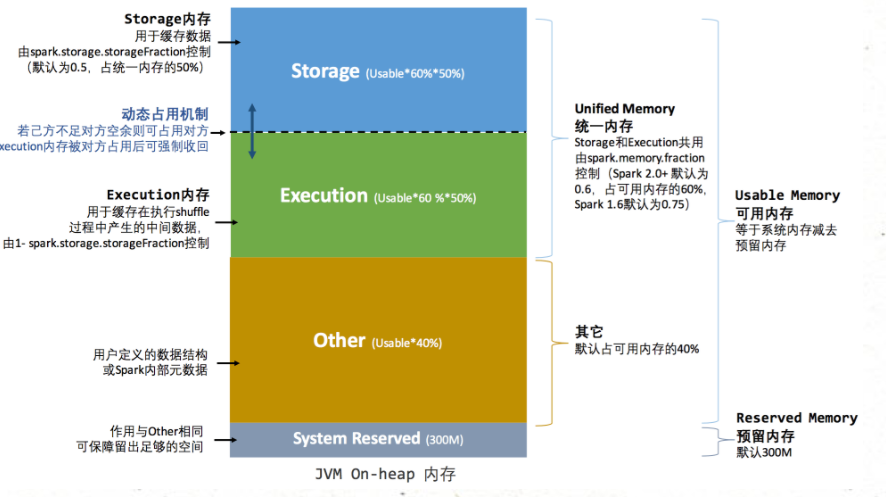
堆内内存整体划分为Usable Memory(可用内存)和Reversed Memory(预留内存)两大部分。其中预留内存作为OOM等异常情况的内存使用区域,默认被分配300M的空间。可用内存可进一步分为(Unified Memory)统一内存和Other内存其他两部分,默认占比为6:4。
统一内存中的Storage(存储内存)和Execution(执行内存)以及Other内存,其参数及使用范围均与静态内存模式一致,不再重复赘述。只是此时的Storage、Execution之间启用了动态内存占用机制。
动态内存占用机制
设置内存的初始值,即Execution和Storage均需设定各自的内存区域范围(默认参数0.5) 若存在一方内存不足,另一方内存空余时,可占用对方内存空间 双方内存均不足时,需落盘处理 Execution内存被占用时,Storage需将此部分转存硬盘并归还空间 Storage内存被占用时,Execution无需归还
2. 堆外内存

和静态管理模式分配一致,堆外内存默认值为384M。整体分为Storage和Execution两部分,且启用动态内存占用机制,其中默认的初始化占比值均为0.5。
计算公式
可用的存储&执行内存 =
(systemMaxMemory -ReservedMemory)
* spark.memoryFraction
* spark.storage.storageFraction
(启用内存动态分配机制,己方内存不足时可占用对方)
3. 总结
-
动态内存占比,提升内存的合理利用率 -
统一管理Storage和Execution内存,便于调优和维护 -
由于Execution占用Storage内存可不规划,存在Storage内存不够频繁GC的情况
3 Spark On Yarn模式的内存分配
由于Spark内存管理机制的健全,Executor能够高效的处理节点中RDD的内存运算和数据流转。而作为分配Executor内存的资源管理器Yarn,如何在过程中保证内存的最合理化分配,也是一个值得关注的问题。
首先看下Spark On Yarn的基本流程:
-
-
Spark Driver端提交程序,并向Yarn申请Application
-
-
-
Yarn接受请求响应,在NodeManager节点上创建AppMaster
-
-
-
AppMaster向Yarn ResourceManager申请资源(Container)
-
-
-
选择合适的节点创建 Container(Executor进程)
-
-
-
后续的Driver启动调度,运行任务
-
Yarn Client、Yarn Cluster模式在某些环节会有差异,但是基本流程类似。其中在整个过程中的涉及到的内存配置如下(源码默认配置):
var executorMemory = 1024
val MEMORY_OVERHEAD_FACTOR = 0.10
val MEMORY_OVERHEAD_MIN = 384
// Executo堆外内存
val executorMemoryOverhead =
sparkConf.getInt("spark.yarn.executor
.memoryOverhead",
math.max((MEMORY_OVERHEAD_FACTOR
* executorMemory).toInt
, MEMORY_OVERHEAD_MIN))
// Executor总分配内存
val executorMem= args.executorMemory
+ executorMemoryOverhead
因此假设当我们提交一个spark程序时,如果设置-executor-memory=5g。
spark-submit
--master yarn-cluster
--name test
--executor-memory 5g
--driver-memory 5g
根据源码中的计算公式可得:
memoryMem= args.executorMemory(5120) + executorMemoryOverhead(512) = 5632M
然而事实上查看Yarn UI上的内存却不是这个数值?这是因为Yarn默认开启了资源规整化。
1. Yarn的资源规整化
Yarn会根据最小可申请资源数、最大可申请资源数和规整化因子综合判断当前申请的资源数,从而合理规整化应用程序资源。
-
定义
程序申请的资源如果不是该因子的整数倍,则将被修改为最小的整数倍对应的值
公式: ceil(a/b)*b
(a是程序申请资源,b为规整化因子)
-
相关配置
yarn.scheduler.minimum-allocation-mb:
最小可申请内存量,默认是1024
yarn.scheduler.minimum-allocation-vcores:
最小可申请CPU数,默认是1
yarn.scheduler.maximum-allocation-mb:
最大可申请内存量,默认是8096
yarn.scheduler.maximum-allocation-vcores:
最大可申请CPU数,默认是4
回到前面的内存计算:由于memoryMem计算完的值为5632,不是规整因子(1024)的整数倍,因此需要重新计算:
memoryMem = ceil(5632/1024)*1024=6144M
2. Yarn模式的Driver内存分配差异
Yarn Client 和 Cluster 两种方式提交,Executor和Driver的内存分配情况也是不同的。Yarn中的ApplicationMaster都启用一个Container来运行;
Client模式下的Container默认有1G内存,1个cpu核,Cluster模式的配置则由driver-memory和driver-cpu来指定,也就是说Client模式下的driver是默认的内存值;Cluster模式下的dirver则是自定义的配置。
cluster模式(driver-memory:5g): ceil(a/b)*b可得driver内存为6144M client模式(driver-memory:5g): ceil(a/b)*b可得driver内存为5120M
3. 总结
Apache Yarn作为分布式资源管理器,有自己内存管理优化机制。当在Yarn部署Spark程序时,需要同时考虑两者的内存处理机制,这是生产应用中最容易忽视的一个知识点。
写在最后
Spark内存管理机制是Spark原理和调优的重点内容,本文从Static Memory Manager(静态管理模式)和Unified Memory Manager(统一管理模式)两种模式入手,深入浅出的讲解Spark计算模型是如何进行内存管理,其中在最后讲述了Spark On Yarn的内存分配,希望以上内容能够给大家带来帮助。
》》》更多好文,请大家关注我的公众号: 大数据兵工厂

- 点赞
- 收藏
- 关注作者
评论(0)