MyCat权威指南阅读笔记(进阶篇)

1 读写分离
1.1 MySQL 主从复制的几种方案
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。
从数据库的角度来说,对于大多数应用来说,从集中到分布,最基本的一个需求不是数据存储的瓶颈,而是
在于计算的瓶颈,即 SQL 查询的瓶颈,我们知道,正常情况下,Insert SQL 就是几十个毫秒的时间内写入完成,
而系统中的大多数 Select SQL 则要几秒到几分钟才能有结果,很多复杂的 SQL,其消耗服务器 CPU 的能力超
强,不亚于死循环的威力。在没有读写分离的系统上,很可能高峰时段的一些复杂 SQL 查询就导致数据库服务器
CPU 爆表,系统陷入瘫痪,严重情况下可能导致数据库崩溃。因此,从保护数据库的角度来说,我们应该尽量避
免没有主从复制机制的单节点数据库。
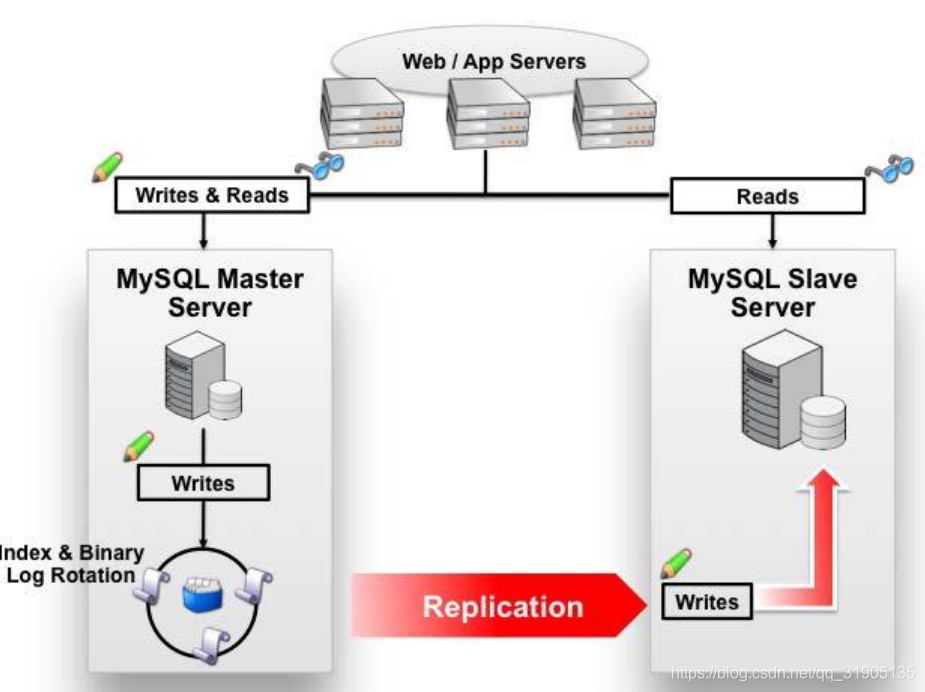
对于 MySQL 来说,标准的读写分离是主从模式,一个写节点 Master 后面跟着多个读节点,读节点的数量取
决于系统的压力,通常是 1-3 个读节点的配置,如下图所示:
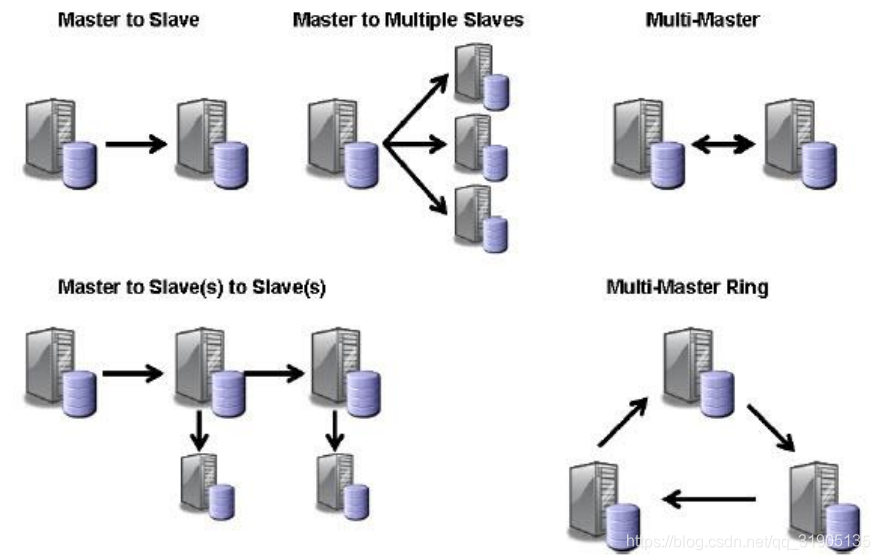
MySQL 支持更多的主从复制的拓扑关系,如下图所示,但通常我们不会采用双向主从同步以及环状的拓扑:
MySQL 主从复制的原理如下:
第一步是在主库上记录二进制日志(稍后介绍如何设置)。在每次准备提交事务完成数 据更新前,主库将数
据更新的事件记录到二进制日志中。MySQL 会按事务提交的顺序 而非每条语句的执行顺序来记录二进制日志。
在记录二进制日志后,主库会告诉存储引 擎可以提交事务了。 下一步,备库将主库的二进制日志复制到其本地的
中继日志中。首先,备库会启动一个 工作线程,称为 I/O 线程,I/O 线程跟主库建立一个普通的客户端连接,然
后在主库上启 动一个特殊的二进制转储(binhg dump、线程(该线程没有对应的 SQL 命令),这个二 进制转储
线程会读取主库上二进制日志中的事件。它不会对事件进行轮询。如果该线程 追赶上了主库,它将进入睡眠状
态,直到主库发送信号量通知其有新的事件产生时才会 被唤醒,备库 I/O 线程会将接收到的事件记录到中继日志
中。
备库的 SQL 线程执行最后一步,该线程从中继日志中读取事件并在备库执行,从而实现 备库数据的更新。当
SQL 线程追赶上 I/O 线程时,中继日志通常已经在系统缓存中,所 以中继日志的开销很低。SQL 线程执行的事件
也可以通过配置选项来决定是否写入其自 己的二进制日志中,它对于我们稍后提到的场景非常有用。这种复制架
构实现了获取事件和重放事件的解耦,允许这两个过程异步进行。也就是说 I/o 线程能够独立于 SQL 线程之外工
作。但这种架构也限制了复制的过程,其中最重要 的一点是在主库上并发运行的査询在备库只能串行化执行,因
为只有一个 SQL 线程来重 放中继日志中的事件。后面我们将会看到,这是很多工作负载的性能瓶颈所在。虽然有
一些针对该问题的解决方案,但大多数用户仍然受制于单线程。MySQL5.6 以后,提供了基于 GTID 多开启多线
程同步复制的方案,即每个库有一个单独的(sql thread)
进行同步复制,这将大大改善 MySQL 主从同步的数据延迟问题,配合 Mycat 分片,可以更好的将一个超级
大表的数据同步的时延降低到最低。此外,用 GTID 避免了在传送 binlog 逻辑上依赖文件名和物理偏移量,能够
更好的支持自动容灾切换,对运维人员来说应该是一件令人高兴的事情,因为传统的方式里,你需要找到 binlog
和 POS 点,然后 change master to 指向,而不是很有经验的运维,往往会将其找错,造成主从同步复制报错,
在 mysql5.6 里,无须再知道 binlog 和 POS 点,需要知道 master 的 IP、端口,账号密码即可,因为同步复制是
自动的,mysql 通过内部机制 GTID 自动找点同步。
即使是并发复制机制、仍然无法避免主从数据库的数据瞬间不同步的问题,因此又有了一种增强的方案,即
galera for mysql、percona-cluster 或者 mariadb cluster 等集群机制,他们是一种多主同步复制的模式,可以
在任意节点上进行读写、自动控制成员,自动删除故障节点、自动加入节点、真正给予行级别的并发复制等强大
能力!
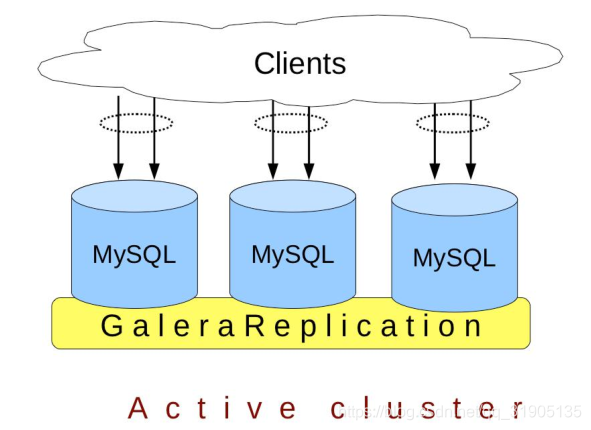
下图是其原理图,通常是采用 3 个 MySQL 节点作为一个 Cluster,即提供了 3 倍的数据库读的并发能
力.galera for mysql 集群这种方式,是牺牲了数据的写入速度,以换取最大程度的数据并发访问能力,类似
Mycat 里的全局表,并且保证了数据同时存在几个有效的副本,从而具有非常高的可靠性,因此在某种程度上,
可以替代 Oracle 的一些关键场景,**目前开源中间件中,只有 Mycat 很完美的支持了 galera for mysql 集群模
式。
1.2 MySQL 主从复制的几个问题
MySQL 主从复制并不完美,存在着几个由来已久的问题,首先一个问题是复制方式:
基于 SQL 语句的复制(statement-based replication, SBR);
基于行的复制(row-based replication, RBR);
混合模式复制(mixed-based replication, MBR);
基于 SQL 语句的方式最古老的方式,也是目前默认的复制方式,后来的两种是 MySQL 5 以后才出现的复
制方式。
RBR 的优点:
任何情况都可以被复制,这对复制来说是最安全可靠的;
和其他大多数数据库系统的复制技术一样;
多数情况下,从服务器上的表如果有主键的话,复制就会快了很多。
RBR 的缺点:
binlog 大了很多;
复杂的回滚时 binlog 中会包含大量的数据;
主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 SBR 只会写一次,这会
导致频繁发生 binlog 的并发写问题;
无法从 binlog 中看到都复制了写什么语句。
SBR 的优点:
历史悠久,技术成熟;
binlog 文件较小;
binlog 中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况;
binlog 可以用于实时的还原,而不仅仅用于复制;
主从版本可以不一样,从服务器版本可以比主服务器版本高。
SBR 的缺点:
不是所有的 UPDATE 语句都能被复制,尤其是包含不确定操作的时候;
复制需要进行全表扫描(WHERE 语句中没有使用到索引)的 UPDATE 时,需要比 RBR 请求更多的行级
锁;
对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而 RBR 模式下,只会对那个发生变化的记
录产生影响;
数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错;
执行复杂语句如果出错的话,会消耗更多资源。
选择哪种方式复制,会影响到复制的效率以及服务器的损耗,甚以及数据一致性性问题,目前其实没有很好
的客观手手段去评估一个系统更适合哪种方式的复制,Mycat 未来希望能通过智能调优模块给出更科学的建议。
第二个问题是关于主从同步的监控问题,Mysql 有主从同步的状态信息,可以通过命令 show slave status
获取,除了获知当前是否主从同步正常工作,另外一个重要指标就是 Seconds_Behind_Master,从字面理解,它
表示当前 MySQL 主从数据的同步延迟,单位是秒,但这个指标从 DBA 的角度并不能简单的理解为延迟多少秒,
感兴趣的同学可以自己去研究,但对于应用来说,简单的认为是主从同步的时间差就可以了,另外,当主从同步
停止以后,重新启动同步,这个数值可能会是几万秒,取决于主从同步停止的时间长短,我们可以认为数据此时
有很多天没有同步了,而这个数值越接近零,则说明主从同步延迟最小,我们可以采集这个指标并汇聚曲线图,
来分析我们的数据库的同步延迟曲线,然后根据此曲线,给出一个合理的阀值,主从同步的时延小于阀值时,我
们认为从库是同步的,此时可以安全的从从库读取数据。Mycat 未来将支持这种优化,让应用更加可靠的读取到
预期的从库数据。
1.3 Mycat 支持的读写分离
1. 配置 mysql 端主从的数据自动同步,mycat 不负责任何的数据同步问题。
2. Mycat 配置读写分离,具体参数参加前面章节。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS1" url="localhost2:3306" user="root" password="123456"
weight="1" />
</writeHost>
</dataHost>
或者
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
</writeHost>
<writeHost host="hostS1" url="localhost:3307" user="root" password="123456">
</writeHost>
</dataHost>
以上两种取模第一种当写挂了读不可用,第二种可以继续使用,事务内部的一切操作都会走写节点,所以读
操作不要加事务,如果读延时较大,使用根据主从延时的读写分离,或者强制走写节点:
1.3.1应用强制走写:
一个查询 SQL 语句以/*balance*/注解来确定其是走读节点还是写节点。
1.6 以后添加了强制走读走写处理:
强制走从:
/*!mycat:db_type=slave*/ select * from travelrecord
/*#mycat:db_type=slave*/ select * from travelrecord
强制走写:
/*#mycat:db_type=master*/ select * from travelrecord
/*!mycat:db_type=master*/ select * from travelrecord
1.3.2根据主从延时切换:
1.4 开始支持 MySQL 主从复制状态绑定的读写分离机制,让读更加安全可靠,配置如下:
MyCAT 心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType="2" 与
slaveThreshold="100",此时意味着开启 MySQL 主从复制状态绑定的读写分离与切换机制,Mycat 心跳机
制通过检测 show slave status 中的 "Seconds_Behind_Master", "Slave_IO_Running",
"Slave_SQL_Running" 三个字段来确定当前主从同步的状态以及 Seconds_Behind_Master 主从复制时延,
当 Seconds_Behind_Master>slaveThreshold 时,读写分离筛选器会过滤掉此 Slave 机器,防止读到很久之
前的旧数据,而当主节点宕机后,切换逻辑会检查 Slave 上的 Seconds_Behind_Master 是否为 0,为 0 时则
表示主从同步,可以安全切换,否则不会切换。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="2"
slaveThreshold="100">
<heartbeat>show slave status </heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
</dataHost>
1.4.1 开始支持 MySQL 集群模式,让读更加安全可靠,配置如下:
MyCAT 心跳检查语句配置为 show status like ‘wsrep%’ ,
dataHost 上定义两个新属性: switchType="3"
此时意味着开启 MySQL 集群复制状态状态绑定的读写分离与切换机制,Mycat 心跳机制通过检测集群复制时延
时,如果延时过大或者集群出现节点问题不会负载改节点。
dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="3" >
<heartbeat> show status like ‘wsrep%’</heartbeat>
<writeHost host="hostM1" url="localhost:3306"
user="root"password="123456">
</writeHost>
<writeHost
host="hostS1"url="localhost:3316"user="root"password="123456" ></writeHost>
</dataHost>
2. 高可用与集群
2.1 MySQL 高可用的几种方案
首先我们看看 MySQL 高可用的几种方案:
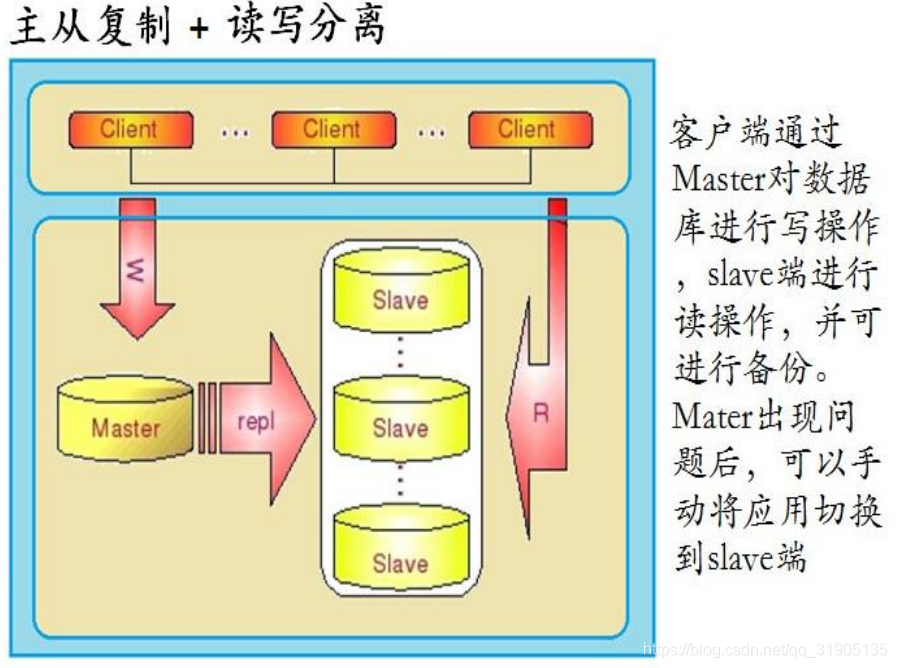
对于数据实时性要求不是特别严格的应用,只需要通过廉价的 pc server 来扩展 Slave 的数量,将读压力分
散到多台 Slave 的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大
多数数据库应用系统中的读压力还是要比写压力大很多。这在很大程度上解决了目前很多中小型网站的数据库压
力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。
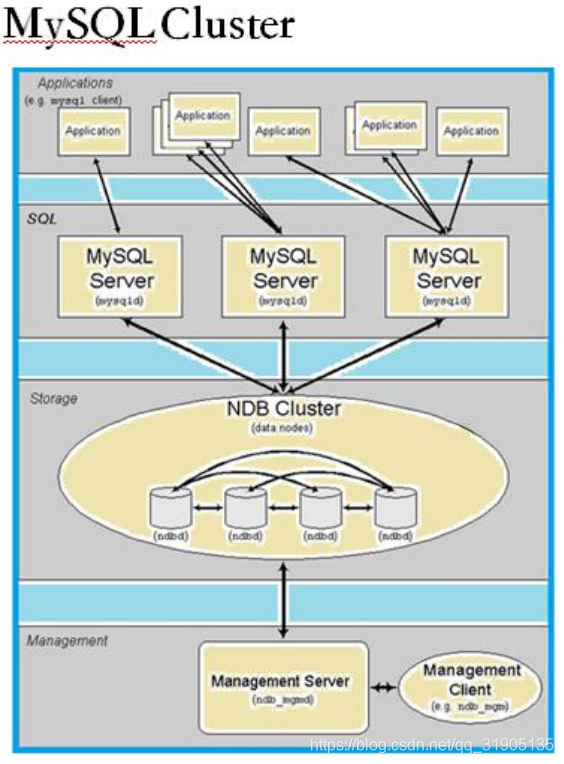
MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括 MySQL 服务器,NDB Cluster
的数据节点,管理服务器,以及(可能)专门的数据访问程序。NDB” 是一种“内存中”的存储引擎,它具有可
用性高和数据一致性好的特点。MySQL Cluster 要实现完全冗余和容错,至少需要 4 台物理主机,其中两个为管
理节点。MySQL Cluster 使用不那么广泛,除了自身构架因素、适用的业务有限之外,另一个重要的原因是其安
装配置管理相对复杂繁琐,总共有几十个操作步骤,需要 DBA 花费几个小时才能搭建或完成。重启 MySQL
Cluster 数据库的管理操作之前需要执行 46 个手动命令,需要耗费 DBA 2.5 小时的时间,而依靠 MySQL
Cluster Manager 只需一个命令即可完成,但 MySQL Cluster Manager 仅作为商用 MySQL Cluster 运营商级
版本 (CGE) 数据库的一部分提供,需要购买。其官方的说明,若应用中的 SQL 操作为主键数据库访问,包含一些
JOIN 操作而非对整个表执行常规扫描和 JOIN 而返回数万行数据,则适合 Cluster,否则不合适,从这一条限制
来看,表明大多数业务场景并不合适 MySQL Cluster,业内有资深人士也凭评价:NDB 不适合大多数业务场景,
而且有安全问题。
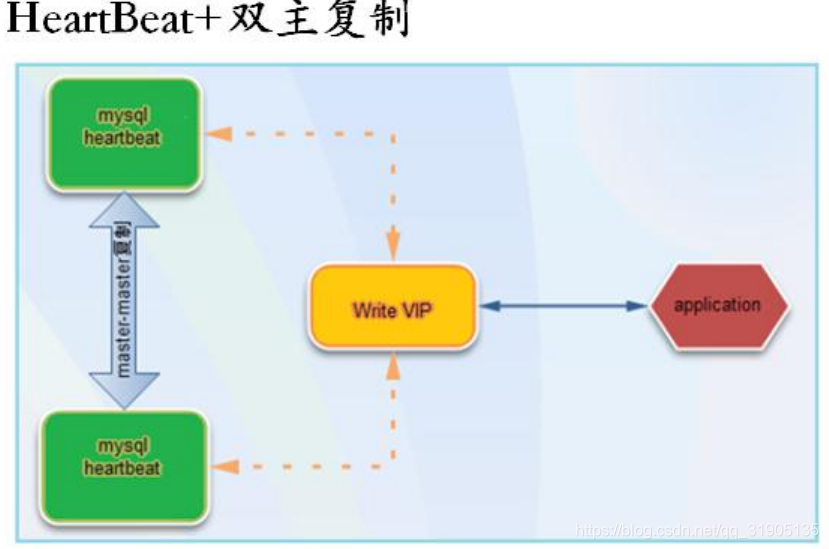
heartbeat 是 Linux-HA 工程的一个组件,heartbeat 最核心的包括两个部分:心跳监测和资源接管。在指定
的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运 行在对方主机上的资
源或者服务。
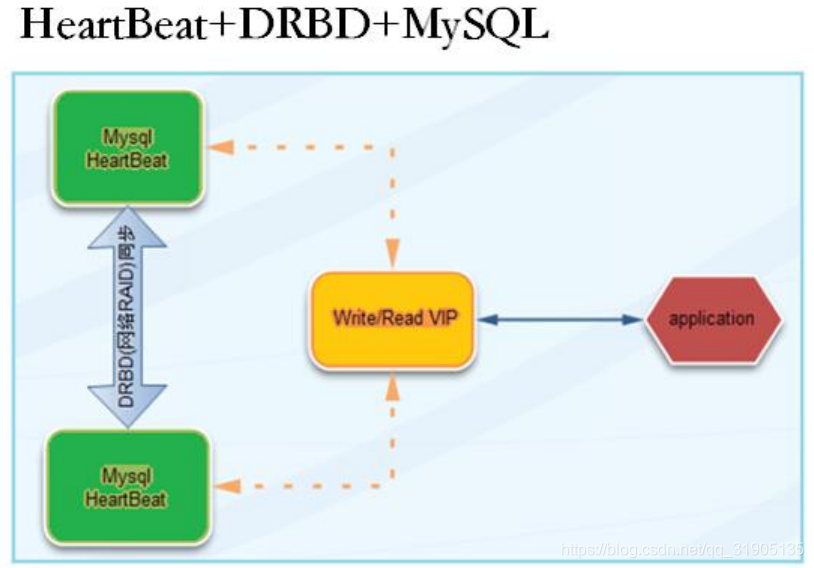
DRBD 是通过网络来实现块设备的数据镜像同步的一款开源 Cluster 软件,它自动完成网络中两个不同服务
器上的磁盘同步,相对于 binlog 日志同步,它是更底层的磁盘同步,理论上 DRDB 适合很多文件型系统的高可
用。
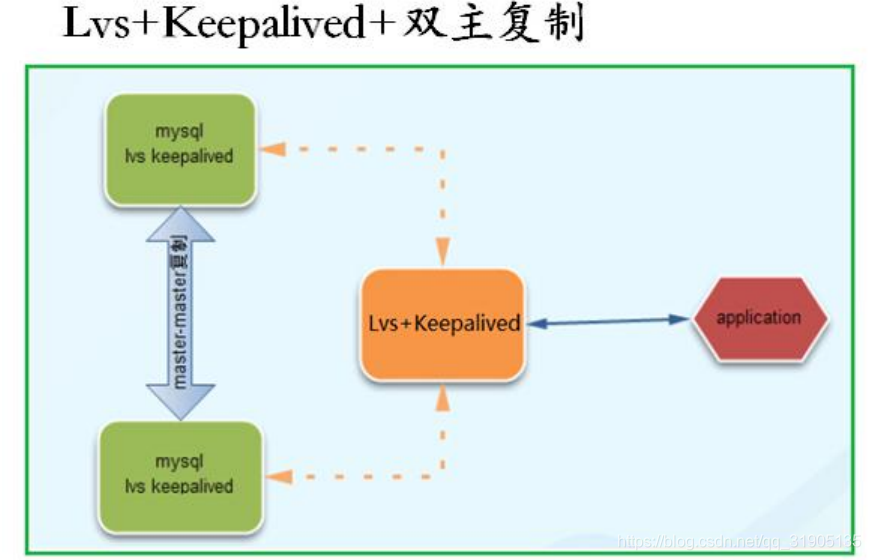
Lvs 是一个虚拟的服务器集群系统,可以实现 LINUX 平台下的简单负载均衡。keepalived 是一个类似于
layer3, 4 & 5 交换机制的软件,主要用于主机与备机的故障转移,这是一种适用面很广的负载均衡和高可用方
案,最常用于 Web 系统。
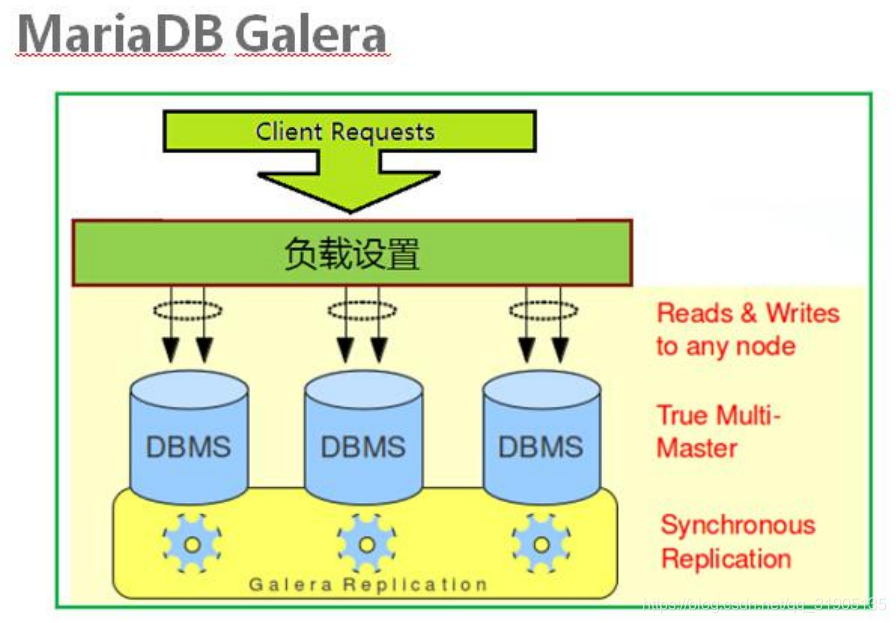
这种 gluster 模式可以说是全新的一种高可用方案,前面也提到其优点,它的缺点不多,不支持 XA,不支持
Lock Table,只能用 InnoDB 引擎。
2.2 Mycat 高可用方案
Mycat 作为一个代理层中间件,Mycat 系统的高可用涉及到 Mycat 本身的高可用以及后端 MySQL 的高可
用,前面章节所讲的 MySQL 高可用方案都可以在此用来确保 Mycat 所连接的后端 MySQL 服务的高可用性。在
大多数情况下,建议采用标准的 MySQL 主从复制高可用性配置并交付给 Mycat 来完成后端 MySQL 节点的主从
自动切换。
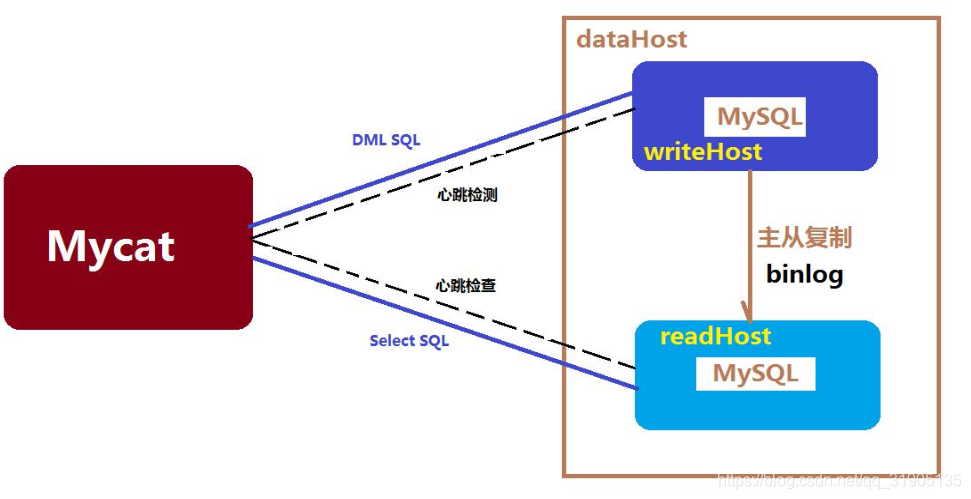
如图所示,MySQL 节点开启主从复制的配置方案,并将主节点配置为 Mycat 的 dataHost 里的
writeNode,从节点配置为 readNode,同时 Mycat 内部定期对一个 dataHost 里的所有 writeHost 与
readHost 节点发起心跳检测,正常情况下,Mycat 会将第一个 writeHost 作为写节点,所有的 DML SQL 会发送
给此节点,若 Mycat 开启了读写分离,则查询节点会根据读写分离的策略发往 readHost(+writeHost)执行,当
一个 dataHost 里面配置了两个或多个 writeHost 的情况下,如果第一个 writeHost 宕机,则 Mycat 会在默认的
3 次心跳检查失败后,自动切换到下一个可用的 writeHost 执行 DML SQL 语句,并在 conf/dnindex.properties
文件里记录当前所用的 writeHost 的 index(第一个为 0,第二个为 1,依次类推),注意,此文件不能删除和擅
自改变,除非你深刻理解了它的作用以及你的目的。
那么问题来了,当原来配置的 MySQL 写节点宕机恢复以后,怎么重新加入 Mycat,要不要恢复为原来的写
节点?关于这个问题,我们也曾与 DBA 讨论很久,最终的建议方案是,保持现有状态不变,改旗易帜,恢复后的
MySQL 节点作为从节点,跟随新的主节点,重新配置主从同步,原先跟随该节点做同步的其他节点也同样换帅,
重新配置同步源,这些节点的数据手工完成同步以后,再加入 Mycat 里。目前 1.3 版本的 Mycat 还没有实现监控
MySQL 主从同步状态的功能,因此这个过程里,DBA 可以先修改 MySQL 的密码,让 Mycat 无法链接故障服务
器,等同步完成以后,恢复密码,这样 Mycat 就自动重新将修复好的 Mycat 纳管进来了。
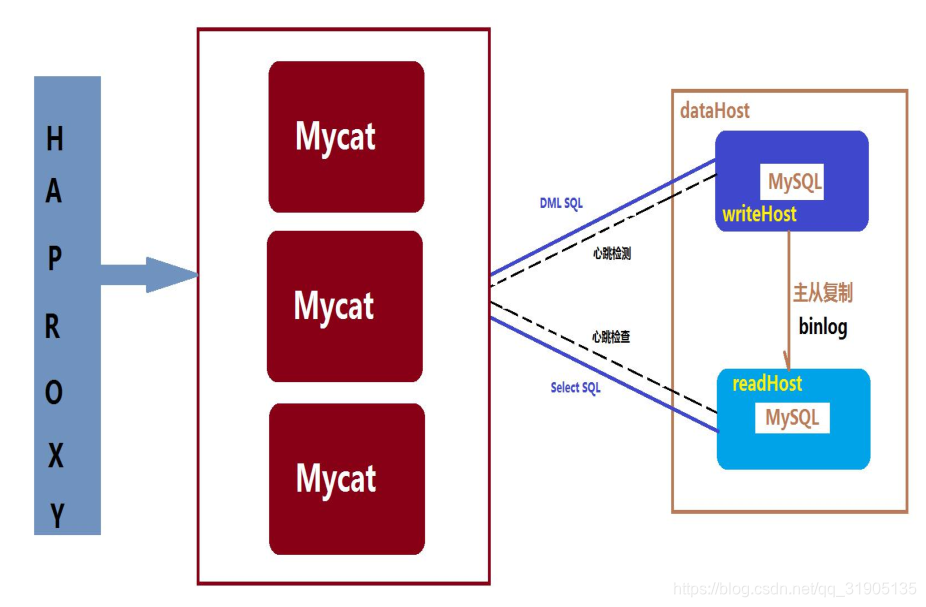
说完了 MySQL 部分,接下来我们看看 Mycat 自身的高可用性,由于 Mycat 自身是属于无状态的中间件(除
了主从切换过程中记录的 dnindex.properties 文件),因此 Mycat 很容易部署为集群方式,提供高可用方案。
原先有规划 Mycat-balance 组件,专门用于 Mycat 负载均衡,但由于缺乏志愿者,也没有经过生产实践验证,
163
因此暂时不建议使用,官方建议是采用基于硬件的负载均衡器或者软件方式的 HAproxy,HAProxy 相比 LVS 的
使用要简单很多,功能方面也很丰富,免费开源,稳定性也是非常好,可以与 LVS 相媲美,根据官方文档,
HAProxy 可以跑满 10Gbps-New benchmark of HAProxy at 10 Gbps using Myricom’s 10GbE NICs (Myri-
10G PCI-Express),这个作为软件级负载均衡,也是比较惊人的,下图是 HAproxy+Mycat 集群+MySQL 主从
所组成的高可用性方案:
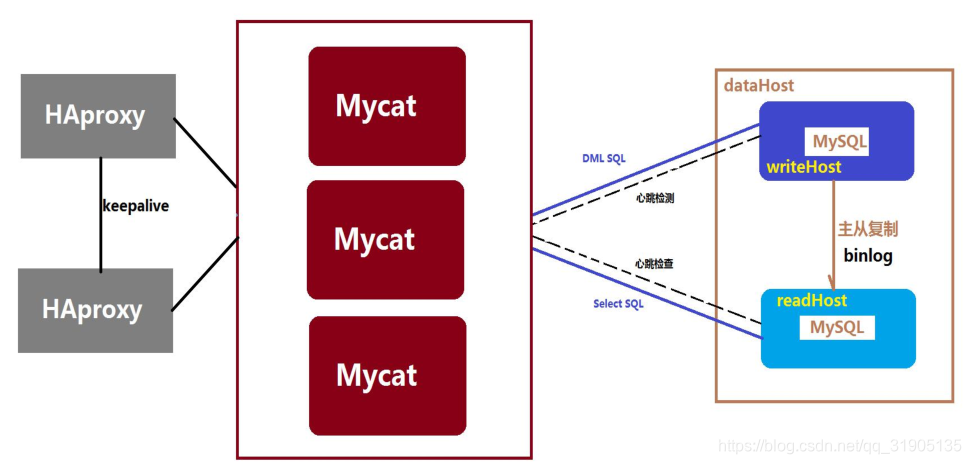
如果还担心 HAproxy 的稳定性和单点问题,则可以用 keepalived 的 VIP 的浮动功能,加以强化:
2.3 Galary Cluster 配置
Mycat1.4.1 开始支持 galary cluster 集群的配置,提高心跳可用。
配置如下:
1.4.1 开始支持 MySQL 集群模式,让读更加安全可靠,配置如下:
MyCAT 心跳检查语句配置为 show status like ‘wsrep%’ ,
dataHost 上定义两个新属性: switchType="3"
此时意味着开启 MySQL 集群复制状态状态绑定的读写分离与切换机制,Mycat 心跳机制通过检测集群复制时延时,如
果延时过大或者集群出现节点问题不会负载改节点。
dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="3" >
<heartbeat> show status like ‘wsrep%’</heartbeat>
<writeHost host="hostM1" url="localhost:3306"
user="root"password="123456">
</writeHost>
<writeHost
host="hostS1"url="localhost:3316"user="root"password="123456" ></writeHost>
</dataHost>
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/87377066

- 点赞
- 收藏
- 关注作者
评论(0)