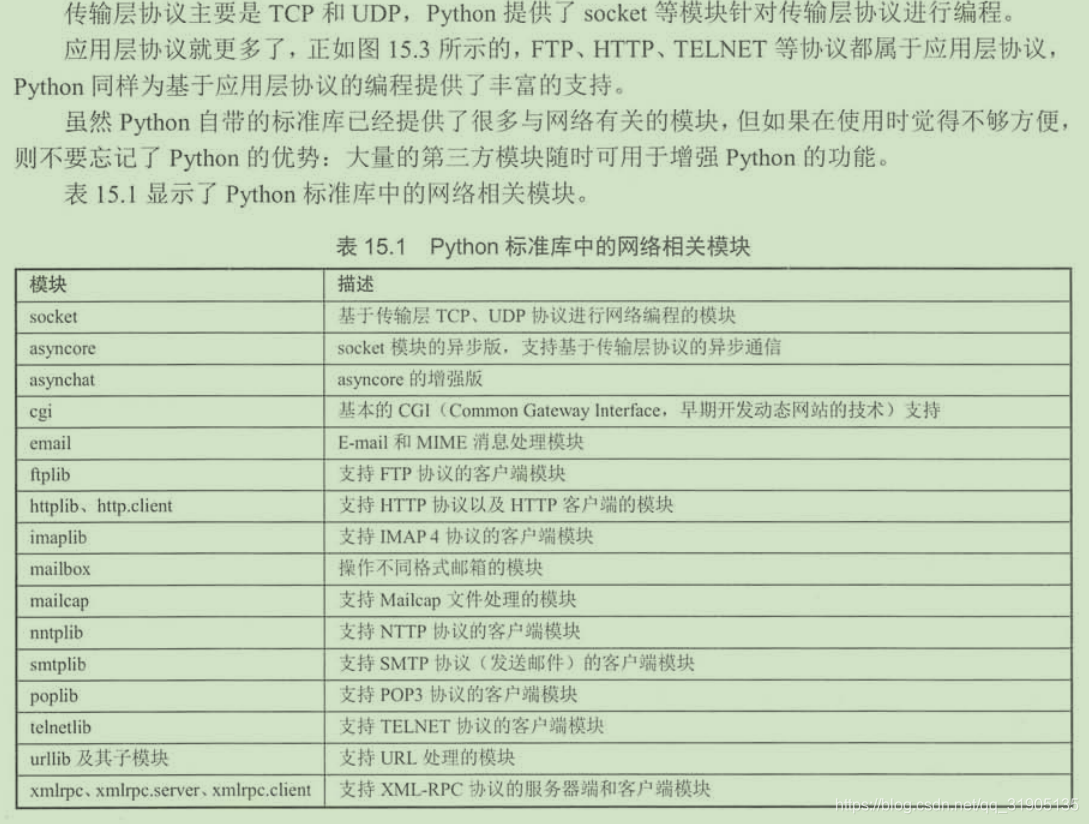
python【系列教程】之网络编程

【摘要】 一、网络编程的基础知识
二、python 的基本网络支持
多线程下载文件工具类DownUtil
from urllib.request import *import threading class DownUtil: def __init__(self, path, target_file, thread_nu...
一、网络编程的基础知识
二、python 的基本网络支持












多线程下载文件工具类DownUtil
-
from urllib.request import *
-
import threading
-
-
-
class DownUtil:
-
def __init__(self, path, target_file, thread_num):
-
# 定义资源下载的路径
-
self.path = path
-
# 定义需要使用多少个线程下载资源
-
self.thread_num = thread_num
-
# 指定所下载的文件的保存位置
-
self.target_file = target_file
-
# 初始化threads数组
-
self.threads = []
-
-
def download(self):
-
# 创建request对象
-
req = Request(url=self.path, method='GET')
-
# 添加请求头
-
req.add_header('Accept', '*/*')
-
req.add_header('Charset', 'UTF-8')
-
req.add_header('Connection', 'Keep-Alive')
-
# 打开要下载的资源
-
f = urlopen(req)
-
self.file_size = int(dict(f.headers).get('Content-Length', 0))
-
f.close()
-
# 计算每个线程要下载的资源大小
-
current_part_size = self.file_size // self.thread_num + 1
-
for i in range(self.thread_num):
-
# 计算每个线程下载的开始位置
-
start_pos = i * current_part_size
-
# 每个线程使用一个wb模式打开的文件进行下载
-
t = open(self.target_file, 'wb')
-
# 定义该线程的下载位置
-
t.seek(start_pos, 0)
-
# 创建下载线程
-
td = DownThread(self.path, start_pos, current_part_size, t)
-
self.threads.append(td)
-
# 启动线程
-
td.start()
-
-
# 获取下载完成的百分比
-
def get_complete_rate(self):
-
# 统计多个线程已经下载的资源总大小
-
sum_size = 0
-
for i in range(self.thread_num):
-
sum_size += self.threads[i].length
-
return sum_size / self.file_size
-
-
-
class DownThread(threading.Thread):
-
def __init__(self, path, start_pos, current_part_size, current_part):
-
super().__init__()
-
self.path = path
-
# 当前线程的下载位置
-
self.start_pos = start_pos
-
# 定义当前线程负责下载的文件大小
-
self.current_part_size = current_part_size
-
# 当前线程需要下载的文件块
-
self.current_part = current_part
-
# 定义当前线程已下载的字节数
-
self.length = 0
-
-
def run(self):
-
# 创建Request对象
-
req = Request(url=self.path, method='GET')
-
# 添加请求头
-
req.add_header('Accept', '*/*')
-
req.add_header('Charset', 'UTF-8')
-
req.add_header('Connection', 'Keep-Alive')
-
# 打开要下载的资源
-
f = urlopen(req)
-
# 跳过self.start_pos个字节,表明该线程只下载自己负责的那部分内容
-
for i in range(self.start_pos):
-
f.read(1)
-
while self.length < self.current_part_size:
-
data = f.read(1024)
-
if data is None or len(data) <= 0:
-
break
-
self.current_part.write(data)
-
# 累计该线程下载的资源总大小
-
self.length += len(data)
-
self.current_part.close()
-
f.close()
-
-
d = DownUtil('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1569583834625&di=9a307758f95e32c324e36d00a9cdd59b&imgtype=0&src=http%3A%2F%2Fb.zol-img.com.cn%2Fsoft%2F6%2F571%2FcepyVKtIjudo6.jpg','./1.jpg',5)
-
-
d.download()
-
-
def show_process():
-
print('已完成:%.2f'% d.get_complete_rate())
-
global t
-
if d.get_complete_rate()<1:
-
t = threading.Timer(0.1,show_process)
-
t.start()
-
t = threading.Timer(0.1,show_process)
-
t.start()



-
from urllib.request import *
-
import http.cookiejar, urllib.parse
-
-
cookie_jar = http.cookiejar.MozillaCookieJar('a.txt')
-
cookie_processor = HTTPCookieProcessor(cookie_jar)
-
opener = build_opener(cookie_processor)
-
# 定义一个模拟chrome浏览器的User-Agent
-
user_agent = r'Mozilla/5.0(Windows NT 6.1; wow64) AppleWebKit/537.36' \
-
r'(KHTML,like Gecko) Chrome/56.0.2924.87 Safari/537.36'
-
-
# 定义请求头
-
headers = {'User-Agent': user_agent, 'Connection': 'keep-alive'}
-
-
# 下面代码发送登陆的post请求
-
# 定义登陆系统的请求参数
-
params = {'name': 'crazyit.org', 'pass': 'leegang'}
-
postdata = urllib.parse.urlencode(params).encode()
-
# 创建向登录页面发送的post请求的request
-
request = Request('http://localhost:8888/test/join.jsp', data=postdata,headers=headers)
-
response = opener.open(request)
-
print(response.read().decode('utf-8'))
-
# 将cookie信息写入文件
-
cookie_jar.save(ignore_discard=True, ignore_expires=True)
-
# 下面代码发送访问被保护资源的get请求
-
request = Request('http://localhost:8888/test/secret.jsp',headers=headers)
-
response = opener.open(request)
-
print(response.read().decode('utf-8'))

三、基于tcp协议的网络编程




-
# 导入socket模块
-
import socket
-
-
# 创建socket对象
-
s = socket.socket()
-
# 连接远程服务器
-
s.connect(('localhost', 30000))
-
print(s.recv(1024).decode('utf-8'))
-
s.close()

socket 通信 服务端代码:
-
# 导入socket模块
-
import socket
-
-
# 创建socket对象
-
s = socket.socket()
-
# 将socket绑定到本机IP和端口
-
s.bind(('localhost', 30000))
-
# 服务器端开始监听来自客户端的连接
-
s.listen()
-
-
while True:
-
# 每当接收到客户端的socket请求时,该方法就返回对应的socket和远程地址
-
c, addr = s.accept()
-
print(c)
-
print('连接地址', addr)
-
c.send('您好!您收到了服务器的新年祝福'.encode('utf-8'))
-
# 关闭连接
-
c.close()
socket通信客户端代码:
-
# 导入socket模块
-
import socket
-
-
# 创建socket对象
-
s = socket.socket()
-
# 连接远程服务器
-
s.connect(('localhost', 30000))
-
print(s.recv(1024).decode('utf-8'))
-
s.close()









四、基于udp协议的网络编程






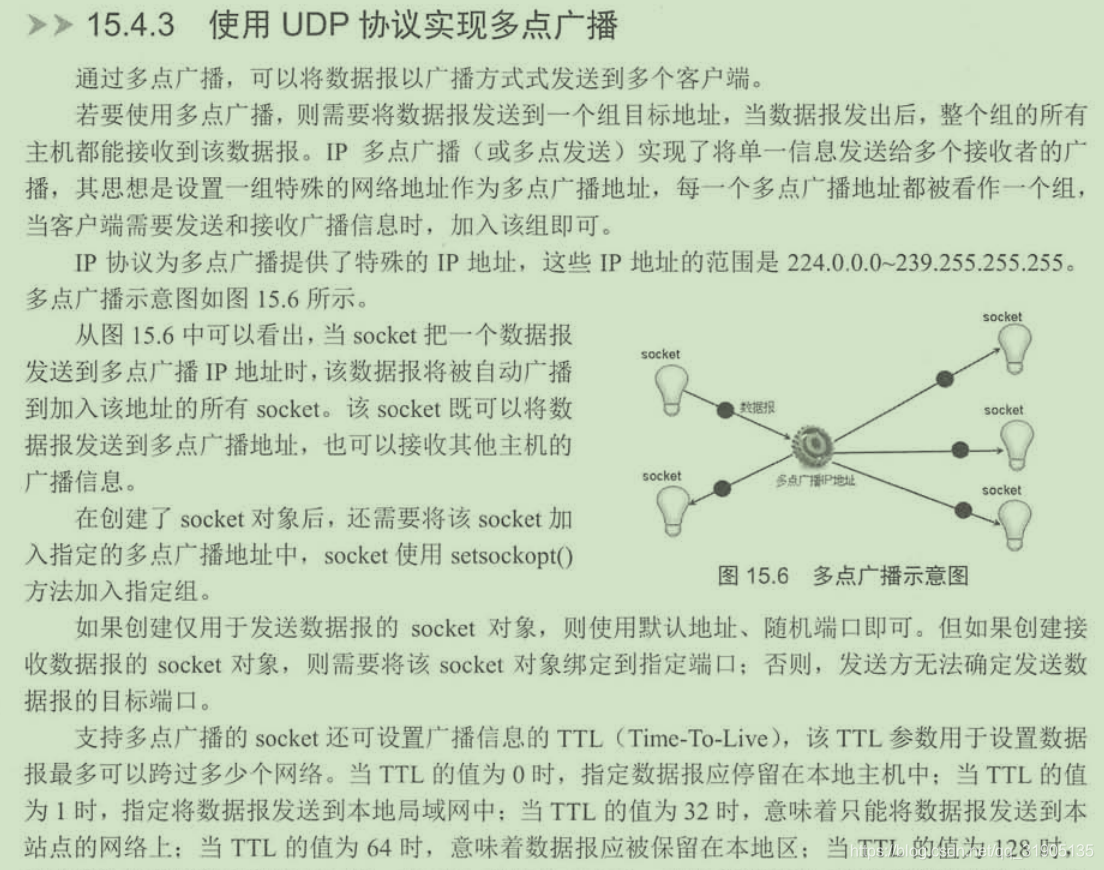


五、电子邮件支持


-
import smtplib
-
from email.message import EmailMessage
-
-
# 定义smtp服务器地址
-
smtp_server = 'smtp.qq.com'
-
# 定义发件人地址
-
from_addr = '414591005@qq.com'
-
# 定义登录邮箱的密码
-
password = 'plrcqrfgdajybhah'
-
# 定义收件人地址
-
to_addr = '414591005@qq.com'
-
# 创建smtp连接
-
conn = smtplib.SMTP(smtp_server)
-
smtplib.SMTP_SSL(smtp_server, 465)
-
conn.set_debuglevel(1)
-
conn.login(from_addr, password)
-
msg = EmailMessage()
-
msg.set_content('您好,这是一封来自python的邮件', 'plain', 'utf-8')
-
conn.sendmail(from_addr, [to_addr], msg.as_string())
-
conn.quit()
发送html邮件

-
import smtplib
-
from email.message import EmailMessage
-
-
# 定义smtp服务器地址
-
smtp_server = 'smtp.qq.com'
-
# 定义发件人地址
-
from_addr = '414591005@qq.com'
-
# 定义登录邮箱的密码
-
password = 'plrcqrfgdajybhah'
-
# 定义收件人地址
-
to_addr = '414591005@qq.com'
-
# 创建smtp连接
-
conn = smtplib.SMTP(smtp_server)
-
smtplib.SMTP_SSL(smtp_server, 465)
-
conn.set_debuglevel(1)
-
conn.login(from_addr, password)
-
msg = EmailMessage()
-
msg.set_content('<h1>您好,这是一封来自python的邮件</h1>', 'html', 'utf-8')
-
msg['subject'] = '<h1>一封html邮件</h1>'
-
msg['from'] = '李刚<%s>' % from_addr
-
msg['to'] = '新用户<%s>' % to_addr
-
conn.sendmail(from_addr, [to_addr], msg.as_string())
-
conn.quit()












文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/101020351

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)