java 并发编程学习笔记(八)线程池

线程池
(1)new Thread 弊端
- 每次new Thred 新建对象,性能差
- 线程缺乏统一管理,可能无限制的新建线程,相互竞争,有可能占用过多系统资源导致死机或者oom
- 缺少更多功能,如更多执行,定期执行,线程中断
(2)线程池的好处
- 重在存在的线程,减少对象的创建,消亡的开销,性能差
- 可有效控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞
- 提供定时执行,定期执行,单线程,并发数控制等功能
(3)线程池 ThreadPoolExecutor


在一个应用程序中,我们需要多次使用线程,也就意味着,我们需要多次创建并销毁线程。而创建并销毁线程的过程势必会消耗内存。而在Java中,内存资源是及其宝贵的,所以,我们就提出了线程池的概念。
线程池:Java中开辟出了一种管理线程的概念,这个概念叫做线程池,从概念以及应用场景中,我们可以看出,线程池的好处,就是可以方便的管理线程,也可以减少内存的消耗。那么,我们应该如何创建一个线程池呢?
Java中已经提供了创建线程池的一个类:Executor而我们创建时,一般使用它的子类:
-
-
public ThreadPoolExecutor(int corePoolSize,
-
int maximumPoolSize,
-
long keepAliveTime,
-
TimeUnit unit,
-
BlockingQueue<Runnable> workQueue,
-
ThreadFactory threadFactory,
-
RejectedExecutionHandler handler) {
-
if (corePoolSize < 0 ||
-
maximumPoolSize <= 0 ||
-
maximumPoolSize < corePoolSize ||
-
keepAliveTime < 0)
-
throw new IllegalArgumentException();
-
if (workQueue == null || threadFactory == null || handler == null)
-
throw new NullPointerException();
-
this.corePoolSize = corePoolSize;
-
this.maximumPoolSize = maximumPoolSize;
-
this.workQueue = workQueue;
-
this.keepAliveTime = unit.toNanos(keepAliveTime);
-
this.threadFactory = threadFactory;
-
this.handler = handler;
-
}
- execute (): 提交 任务,交给线程池执行
- submit():提交任务,能够返回执行结果 execute+future
- shutdown():关闭线程池,等待任务都执行完
- shutdownNow (): 关闭线程池,不等待任务执行完
- getTaskCount (): 线程池已经执行和未执行的任务总数
- getCompletedTaskCount (): 已完成的任务数量
- getPoolSize () : 线程池当前的线程数量
- getActiveCount (): 当前线程池中正在执行任务的线程数量
这是其中最重要的一个构造方法,
这个方法决定了创建出来的线程池的各种属性,下面依靠一张图来更好的理解线程池和这几个参数:又图中,我们可以看出,
线程池中的corePoolSize就是线程池中的核心线程数量,这几个核心线程,只是在没有用的时候,也不会被回收。
maximumPoolSize就是线程池中可以容纳的最大线程的数量。
keepAliveTime,就是线程池中除了核心线程之外的其他的最长可以保留的时间,因为在线程池中,除了核心线程即使在无任务的情况下也不能被清除,其余的都是有存活时间的,意思就是非核心线程可以保留的最长的空闲时间,而util,就是计算这个时间的一个单位。
workQueue,就是等待队列,任务可以储存在任务队列中等待被执行,执行的是FIFIO原则(先进先出)。
threadFactory,就是创建线程的线程工厂。
最后一个handler,是一种拒绝策略,我们可以在任务满了知乎,拒绝执行某些任务。
线程池的执行流程又是怎样的呢?
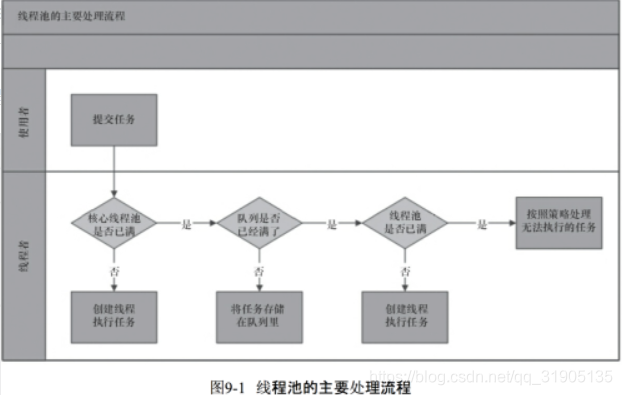
有图我们可以看出,任务进来时,首先执行判断,判断核心线程是否处于空闲状态,如果不是,核心线程就先就执行任务,如果核心线程已满,则判断任务队列是否有地方存放该任务,若果有,就将任务保存在任务队列中,等待执行,如果满了,在判断最大可容纳的线程数,如果没有超出这个数量,就开创非核心线程执行任务,如果超出了,就调用handler实现拒绝策略。
- handler的拒绝策略有四种:
第一种AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
-
public static class AbortPolicy implements RejectedExecutionHandler {
-
/**
-
* Creates an {@code AbortPolicy}.
-
*/
-
public AbortPolicy() { }
-
-
/**
-
* Always throws RejectedExecutionException.
-
*
-
* @param r the runnable task requested to be executed
-
* @param e the executor attempting to execute this task
-
* @throws RejectedExecutionException always
-
*/
-
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
-
throw new RejectedExecutionException("Task " + r.toString() +
-
" rejected from " +
-
e.toString());
-
}
-
}
第二种DisCardPolicy:不执行新任务,也不抛出异常
-
public static class DiscardPolicy implements RejectedExecutionHandler {
-
/**
-
* Creates a {@code DiscardPolicy}.
-
*/
-
public DiscardPolicy() { }
-
-
/**
-
* Does nothing, which has the effect of discarding task r.
-
*
-
* @param r the runnable task requested to be executed
-
* @param e the executor attempting to execute this task
-
*/
-
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
-
}
-
}
第三种DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
-
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
-
/**
-
* Creates a {@code DiscardOldestPolicy} for the given executor.
-
*/
-
public DiscardOldestPolicy() { }
-
-
/**
-
* Obtains and ignores the next task that the executor
-
* would otherwise execute, if one is immediately available,
-
* and then retries execution of task r, unless the executor
-
* is shut down, in which case task r is instead discarded.
-
*
-
* @param r the runnable task requested to be executed
-
* @param e the executor attempting to execute this task
-
*/
-
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
-
if (!e.isShutdown()) {
-
e.getQueue().poll(); //将队列头部的任务移除掉
-
e.execute(r); //执行当前新进来的任务
-
}
-
}
-
}
第四种CallerRunsPolicy:直接调用execute来执行当前任务
-
public static class CallerRunsPolicy implements RejectedExecutionHandler {
-
/**
-
* Creates a {@code CallerRunsPolicy}.
-
*/
-
public CallerRunsPolicy() { }
-
-
/**
-
* Executes task r in the caller's thread, unless the executor
-
* has been shut down, in which case the task is discarded.
-
*
-
* @param r the runnable task requested to be executed
-
* @param e the executor attempting to execute this task
-
*/
-
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
-
if (!e.isShutdown()) {
-
r.run(); //直接执行 当前新进来的任务
-
}
-
}
-
}
- 四种常见的线程池:
CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。
SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。
FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程
-
/**
-
* fixedThreadPool 正规的线程池,由于核心池数 等于最大 池数,因此没有最大线程池,
-
* 只有最大线程池 的线程才能被回收,因为没有最大线程池,所以无超时机制,
-
* 队列大小无限制,除非线程池关闭了核心线程才会被回收,
-
* 采用默认的AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
-
* return new ThreadPoolExecutor(nThreads, nThreads,
-
* 0L, TimeUnit.MILLISECONDS,
-
* new LinkedBlockingQueue<Runnable>());
-
*
-
*/
-
ExecutorService service = Executors.newFixedThreadPool(10);
-
-
/**
-
* newCachedThreadPool
-
* return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
-
* 60L, TimeUnit.SECONDS,
-
* new SynchronousQueue<Runnable>());
-
*
-
* 只有非核心线程,最大线程数很大(Integer.MAX_VALUE),它会为每一个任务添加一个新的线程,
-
* 这边有一个超时机制,当最大线程池中空闲的线程超过60s内没有用到的话,就会被回收。
-
* 缺点就是没有考虑到系统的实际内存大小。
-
* 采用默认的AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
-
*/
-
service = Executors.newCachedThreadPool();
-
-
-
/**
-
* return new FinalizableDelegatedExecutorService
-
* (new ThreadPoolExecutor(1, 1,
-
* 0L, TimeUnit.MILLISECONDS,
-
* new LinkedBlockingQueue<Runnable>()));
-
* 看这个名字就知道这个家伙是只有一个核心线程,就是一个孤家寡人,
-
*通过指定的顺序将任务一个个丢到线程,都乖乖的排队等待执行,不处理并发的操作,不会被回收。确定就是一个人干活效率慢。
-
*/
-
Executors.newSingleThreadExecutor();
-
-
/**
-
* super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
-
* new DelayedWorkQueue());
-
* 这个线程池就厉害了,是唯一一个有延迟执行和周期重复执行的线程池。
-
* 它的核心线程池固定,非核心线程的数量没有限制,但是闲置时会立即会被回收。
-
*/
-
Executors.newScheduledThreadPool(5);
-
(4)线程池的简单使用
-
@Slf4j
-
public class ThreadPoolExample1 {
-
public static void main(String[] args) {
-
ExecutorService service = Executors.newCachedThreadPool();
-
-
service = Executors.newFixedThreadPool(3);
-
-
service = Executors.newSingleThreadExecutor();
-
-
for (int i = 0; i < 10; i++) {
-
final int index = i;
-
service.execute(() -> {
-
log.info("task {}", index);
-
});
-
}
-
-
service.shutdown();
-
-
//Timer 组件
-
Timer timer = new Timer();
-
timer.schedule(new TimerTask() {
-
@Override
-
public void run() {
-
log.info("Timer组件的定时任务");
-
}
-
}, new Date());
-
-
timer.schedule(new TimerTask() {
-
@Override
-
public void run() {
-
log.info("");
-
}
-
}, 3);
-
-
timer.schedule(new TimerTask() {
-
@Override
-
public void run() {
-
log.info("开始时间");
-
log.info("喵喵喵喵喵喵喵喵");
-
log.info("结束时间");
-
}
-
}, 3000, 3000);
-
-
-
timer.scheduleAtFixedRate(new TimerTask() {
-
@Override
-
public void run() {
-
log.info("开始时间");
-
log.info("喵喵喵喵喵喵喵喵");
-
log.info("结束时间");
-
}
-
}, 3000, 3000);
-
-
-
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10);
-
//3秒之后执行
-
scheduledExecutorService.schedule(() -> {
-
log.info("啦啦啦啦!");
-
},
-
3, TimeUnit.SECONDS);
-
-
-
//3秒之后执行,前一个线程的执行开始时间 和 后一个 线程的执行开始时间相差2秒
-
/**
-
* command:执行线程
-
* initialDelay:初始化延时
-
* period:两次开始执行最小间隔时间
-
* unit:计时单位
-
*/
-
scheduledExecutorService.scheduleAtFixedRate(() -> {
-
log.info("开始时间");
-
log.info("啦啦啦啦啦啦啦啦啦!");
-
log.info("结束时间");
-
}, 3, 2, TimeUnit.SECONDS);
-
-
-
//3秒之后执行,前一个线程的结束时间 和 后一个 线程的 开始时间相差2秒
-
/**
-
* command:执行线程
-
* initialDelay:初始化延时
-
* period:前一次执行结束到下一次执行开始的间隔时间(间隔执行延迟时间)
-
* unit:计时单位
-
*/
-
scheduledExecutorService.scheduleWithFixedDelay(() -> {
-
log.info("开始时间");
-
log.info("啦啦啦啦啦啦啦啦啦!");
-
log.info("结束时间");
-
}, 3, 5, TimeUnit.SECONDS);
-
}
-
}
(5)线程池 合理配置
cpu 密集型任务,就需要尽量压榨cpu,参考值可以设置为NCPU+1
Io 密集型任务,参考值可以设置为2*NCPU
I/O 密集型(主要是读写):指的是系统的CPU效能相对硬盘/内存的效能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高
CPU 密集型(主要是运算): 指的是系统的 硬盘/内存 效能 相对 CPU 的效能 要好很多,此时,系统运作,大部分的状况是 CPU Loading 100%,CPU 要读/写 I/O (硬盘/内存),I/O在很短的时间就可以完成,而 CPU 还有许多运算要处理,CPU Loading 很高。
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/84304276

- 点赞
- 收藏
- 关注作者
评论(0)