大数据之 Flume 日志收集框架入门

Flume 日志收集框架入门
一、 flume 简介
Apache Flume是一个分布式,可靠且可用的系统,用于有效地从许多不同的源收集,聚合和移动大量日志数据到集中式数据存储。
Apache Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume可用于传输大量事件数据,包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎任何可能的数据源。
Apache Flume是Apache Software Foundation的顶级项目。
目前有两种版本代码行,版本0.9.x和1.x.
系统要求:
- Java运行时环境 - Java 1.8或更高版本
- 内存 - 源,通道或接收器使用的配置的足够内存
- 磁盘空间 - 通道或接收器使用的配置的足够磁盘空间
- 目录权限 - 代理使用的目录的读/写权限
数据流模型
Flume事件被定义为具有字节有效负载和可选字符串属性集的数据流单元。Flume代理是一个(JVM)进程,它承载事件从外部源流向下一个目标(跃点)的组件。
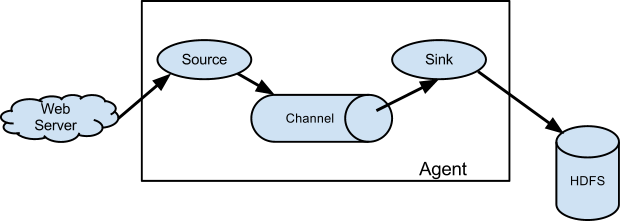
Flume源消耗由外部源(如Web服务器)传递给它的事件。外部源以目标Flume源识别的格式向Flume发送事件。例如,Avro Flume源可用于从Avro客户端或从Avro接收器发送事件的流中的其他Flume代理接收Avro事件。可以使用Thrift Flume Source定义类似的流程,以接收来自Thrift Sink或Flume Thrift Rpc客户端或Thrift客户端的事件,这些客户端使用Flume thrift协议生成的任何语言编写。当Flume源接收事件时,它将其存储到一个或多个频道。该通道是一个被动存储器,可以保持事件直到它被Flume接收器消耗。文件通道就是一个例子 - 它由本地文件系统支持。接收器从通道中移除事件并将其放入外部存储库(如HDFS(通过Flume HDFS接收器))或将其转发到流中下一个Flume代理(下一跳)的Flume源。给定代理程序中的源和接收器与通道中暂存的事件异步运行。
二、flume 下载 安装 ,配置环境变量
cdh 版本下载地址 http://archive.cloudera.com/cdh5/cdh/5/
解压 tar -zxvf flume-ng-1.6.0-cdh5.7.0.tar
配置环境变量:
- 事先配置好jdk1.8以上的JAVA_HOME
- 配置FLUME_HOME
-
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
-
export PATH=${FLUME_HOME}/bin:$PATH
修改 配置 文件:
cd apache-flume-1.6.0-cdh5.7.0-bin/conf/
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
添加 一行
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
执行 flume-ng version 命令 可以在控制台上看到版本号输出说明安装成功。
三、flume 实战(1)从指定的网络端口采集数据输出到控制台
使用 flume 的关键就是写配置文件
(a)配置source
(b)配置channel
(c)配置sink
(d)把以上三个组件串起来
类似于netcat的源,它侦听给定端口并将每行文本转换为事件。像nc -k -l [host] [port]这样的行为。换句话说,它打开一个指定的端口并侦听数据。期望提供的数据是换行符分隔的文本。每行文本都转换为Flume事件,并通过连接的通道发送。
示例配置文件 agent 的名称为a1 ,sources 的名称为 r1 ,sinks 的名称为k1,channels 的名称为 c1
编写 配置 example.conf 文件,放到 $FLUME_HOME/conf 目录下:
-
#example.conf:单节点Flume配置
-
-
#为此代理命名组件
-
a1.sources = r1
-
a1.sinks = k1
-
a1.channels = c1
-
-
#描述/配置源
-
a1.sources.r1.type = netcat
-
a1.sources.r1.bind = localhost
-
a1.sources.r1.port = 44444
-
-
#描述接收器
-
a1.sinks.k1.type = logger
-
-
#使用缓冲内存中事件的通道
-
a1.channels.c1.type = memory
-
a1.channels.c1.capacity = 1000
-
a1.channels.c1.transactionCapacity = 100
-
-
#将源和接收器绑定到通道
-
a1.sources.r1.channels = c1
-
a1.sinks.k1.channel = c1
启动 一个 agent
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/example.conf -Dflume.root.logger
=INFO,console
使用 telnet 命名进行测试 telnet hadoop000 44444
输入 任意字符串 ,可以看到 flume 的控制台接收到了我们 输入的 内容如下:
[INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F hello world.}
Event 是Flume 数据传输的基本单元
四 、 fluem 实战(2)监控一个文件实时采集新增的数据输出到控制台
在/home/hadoop/目录 下 创建一个 hello.txt文件 ,并向其中输入内容
编写配置文件
-
#example.conf:单节点Flume配置
-
-
#为此代理命名组件
-
a1.sources = r1
-
a1.sinks = k1
-
a1.channels = c1
-
-
#描述/配置源
-
a1.sources.r1.type = exec
-
a1.sources.r1.command = tail -F /home/hadoop/hello.txt
-
a1.sources.r1.shell = /bin/bash -c
-
-
-
#描述接收器
-
a1.sinks.k1.type = logger
-
-
#使用缓冲内存中事件的通道
-
a1.channels.c1.type = memory
-
a1.channels.c1.capacity = 1000
-
a1.channels.c1.transactionCapacity = 100
-
-
#将源和接收器绑定到通道
-
a1.sources.r1.channels = c1
-
a1.sinks.k1.channel = c1
启动 agent:
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/example.conf -Dflume.root.logger
=INFO,console
执行 touch hello world >> hello.txt 进行测试,看到 flume 控制台接收到 数据即可。
2018-12-25 18:28:21,386 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
五、flume实战(3)将A服务器上面的日志采集到B服务器上

技术选型:exec source + memory channel +avro sink
avro source + memory channel + logger sink
编写 配置 exec-memory-avro.conf
-
-
-
#为此代理命名组件
-
exec-memory-avro.sources = exec-source
-
exec-memory-avro.sinks = avro-sink
-
exec-memory-avro.channels = memory-channel
-
-
#描述/配置源
-
exec-memory-avro.sources.exec-source.type = exec
-
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/hello.txt
-
exec-memory-avro.sources.exec-source.shell = /bin/bash -c
-
-
-
#描述接收器
-
exec-memory-avro.sinks.avro-sink.type = avro
-
exec-memory-avro.sinks.avro-sink.hostname = hadoop000
-
exec-memory-avro.sinks.avro-sink.port = 44444
-
-
#使用缓冲内存中事件的通道
-
exec-memory-avro.channels.memory-channel.type = memory
-
exec-memory-avro.channels.memory-channel.capacity = 1000
-
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
-
-
#将源和接收器绑定到通道
-
exec-memory-avro.sources.exec-source.channels = memory-channel
-
exec-memory-avro.sinks.avro-sink.channel = memory-channel
编写 配置 avro-memory-logger.conf
-
-
-
#为此代理命名组件
-
avro-memory-logger.sources = avro-source
-
avro-memory-logger.sinks = logger-sink
-
avro-memory-logger.channels = memory-channel
-
-
#描述/配置源
-
avro-memory-logger.sources.avro-source.type = avro
-
avro-memory-logger.sources.avro-source.bind = hadoop000
-
avro-memory-logger.sources.avro-source.port = 44444
-
-
-
#描述接收器
-
avro-memory-logger.sinks.logger-sink.type = logger
-
-
#使用缓冲内存中事件的通道
-
avro-memory-logger.channels.memory-channel.type = memory
-
avro-memory-logger.channels.memory-channel.capacity = 1000
-
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
-
-
#将源和接收器绑定到通道
-
avro-memory-logger.sources.avro-source.channels = memory-channel
-
avro-memory-logger.sinks.logger-sink.channel = memory-channel
日志收集过程:
- 机器上A 上监控一个文件,当我们访问主站时候会有用户行为日志记录到 access.log中
- avro sink把新产生的日志输出到对应的avro source 指定的hostname 和 port 上
- 通过avro source 对应的 agent 将我们的 日志输出到控制台或者(kafka)
先启动 B 服务器 agent
flume-ng agent --name avro-memory-logger --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
在启动A服务器 agent
flume-ng agent --name exec-memory-avro --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 /home/hadoop/hello.txt 文件中输出内容, 即可 看到 B 服务器 flume 控制台 上接收到A 服务器上面 sink 过来的内容。
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/85256667

- 点赞
- 收藏
- 关注作者
评论(0)