spark 环境搭建

一、spark 安装 配置
基于上一篇博客 CentOS6.4环境编译Spark-2.1.0源码,将编译出来的spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz进行解压,并配置环境变量。
执行 spark-shell --master local[2] 命令,
看到如图所示界面 说明安装成功:本地模式

二、从词频统计着手入门spark
-
package org.apache.spark.examples.streaming
-
-
-
-
import org.apache.spark.SparkConf
-
-
import org.apache.spark.storage.StorageLevel
-
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
-
-
-
/**
-
-
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
-
-
*
-
-
* Usage: NetworkWordCount <hostname> <port>
-
-
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
-
-
*
-
-
* To run this on your local machine, you need to first run a Netcat server
-
-
* `$ nc -lk 9999`
-
-
* and then run the example
-
-
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
-
-
*/
-
-
object NetworkWordCount {
-
-
def main(args: Array[String]) {
-
-
if (args.length < 2) {
-
-
System.err.println("Usage: NetworkWordCount <hostname> <port>")
-
-
System.exit(1)
-
-
}
-
-
-
-
StreamingExamples.setStreamingLogLevels()
-
-
-
-
// Create the context with a 1 second batch size
-
-
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
-
-
val ssc = new StreamingContext(sparkConf, Seconds(1))
-
-
-
-
// Create a socket stream on target ip:port and count the
-
-
// words in input stream of \n delimited text (eg. generated by 'nc')
-
-
// Note that no duplication in storage level only for running locally.
-
-
// Replication necessary in distributed scenario for fault tolerance.
-
-
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
-
-
val words = lines.flatMap(_.split(" "))
-
-
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
-
-
wordCounts.print()
-
-
ssc.start()
-
-
ssc.awaitTermination()
-
-
}
-
-
}
-
-
// scalastyle:on println
执行 nc -lk 9999 启动一个 9999网络端口,后面 输入 单词数据测试使用
1、spark-submit 方式提交spark应用程序运行
spark-submit --master local[2] \
--class org.apache.spark.examples.streaming.NetworkWordCount \
--name NetworkWordCount \
/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar hadoop000 9999
在nc -lk 9999下面输入a a a b b c d e 以空格隔开的单词,按回车键。就可以看到

2、spark-shell --master local[2] 方式 提交 spark 应用任务
等待 spark shell 启动好之后,直接将以下代码 粘贴进去即可。
-
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
val ssc = new StreamingContext(sparkConf, Seconds(1)) //每隔一秒执行一次
-
-
val lines = ssc.socketTextStream("hadoop000", 9999) //ip 端口
-
-
val words = lines.flatMap(_.split(" "))
-
-
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
-
-
wordCounts.print()
-
-
ssc.start()
-
-
ssc.awaitTermination()
同样在 nc -lk 9999 下面 输入 d d e e f f 按回车键
三、 spark streaming 的工作原理(粗粒度)
spark streaming 接收到实时数据流,把数据按照指定的时间段切成一片片小的数据块,然后把小的数据块传给
spark engine 处理。
四、spark streaming 核心概念
- StreamingContext
使用频次较高的构造方法
-
def this(sparkContext: SparkContext, batchDuration: Duration) = {
-
this(sparkContext, null, batchDuration)
-
}
-
def this(conf: SparkConf, batchDuration: Duration) = {
-
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
-
}
batch interval 可以根据你的应用程序需求的延迟需求以及集群可以用的资源情况来设置。
- DStreams
对 DStream 操作算子,比如map/flatMap ,其实底层会被翻译为对 DStream 中的每个RDD 都做相同的操作,因为一个
DStream是 由不同批次的RDD所构成的。
- Input Dstreams 和 Receivers
input Dstreams 代表 从源头接收过来的数据流
receivers 接收 数据流
- Transformations on DStreams
五、spark streaming 实战 之 处理 socket 数据
-
import org.apache.spark.SparkConf
-
import org.apache.spark.streaming.{Seconds, StreamingContext}
-
-
/**
-
* 测试 :采用 nc -lk 6789 进行测试
-
*/
-
object NetworkWordCount {
-
-
def main(args: Array[String]): Unit = {
-
-
/**
-
* 这里要设置成local[2]。
-
*/
-
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
-
/**
-
* 创建streamingContext
-
*/
-
val ssc = new StreamingContext(sparkConf, Seconds(5))
-
val lines = ssc.socketTextStream("192.168.42.85", 6789)
-
val result = lines.flatMap(_.split(" ").map((_, 1))).reduceByKey(_ + _)
-
result.print()
-
ssc.start()
-
ssc.awaitTermination()
-
}
-
}
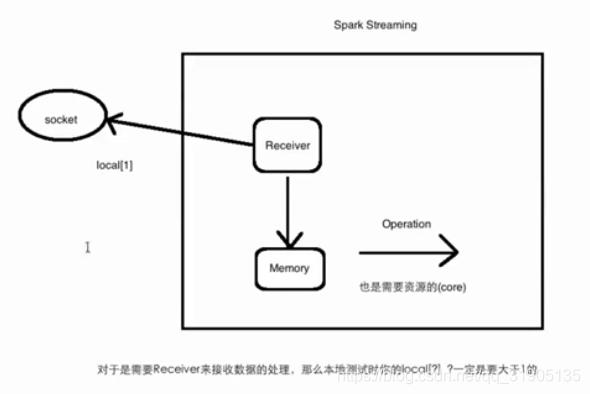
local[?] 对于 是需要 receiver 接收数据的处理任务, 那么本地测试时,local[?] ,?一定是要大于1的,否则receiver 已经占用了一个线程,对于 后面的 operation 就没有 对于的线程可以使用。
六、spark streaming 处理文件系统处理
-
object FileWordCount {
-
def main(args: Array[String]): Unit = {
-
//此处的local 可以 设置为 local[1],因为 他不需要 receiver 接收 数据
-
val sparkConf = new SparkConf().setMaster("local").setAppName("FileWordCount")
-
val ssc = new StreamingContext(sparkConf,Seconds(5))
-
val lines = ssc.textFileStream("file:///home/logs/")
-
val result = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
-
result.print()
-
ssc.start()
-
ssc.awaitTermination()
-
}
-
}
启动 main 方法, 在 home/logs 下 新建 a.log 文件,并向其中输入 a b c d 保存,看到控制台 输出 单词统计的结果
a b c d 频次均为1 ,说明任务运行成功,再新建 b.log,向 其中输入 e e f f d r 保存,看到控制台输出单词统计结果
,e 频次 2,f 频次 2,d频次 1,r频次 1 说明运行成功,但是当我们 再次 向 a.log 、b.log 中写入新的单词时候,spark
streaming 并不会 再次去进行 单词统计任务的执行。
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/85615733

- 点赞
- 收藏
- 关注作者
评论(0)