零基础爬虫入门(五) | 数据抓取策略与更新策略

大家好,我是不温卜火,是一名计算机学院大数据专业大三的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只在csdn这一个平台进行更新,博客主页:https://buwenbuhuo.blog.csdn.net/。
PS:由于现在越来越多的人未经本人同意直接爬取博主本人文章,博主在此特别声明:未经本人允许,禁止转载!!!

一、爬行策略
爬行策略,是指对爬行过程中从每个页面解析得到的超链接进行安排的方法,即按照什么样的顺序对这些超链接进行爬行。
1.1 爬行策略的设计需要考虑以下限制
(1)不要对Web服务器产生太大的压力
这些压力主要体现在:
①与Web服务器的连接需要占用其网络带宽
②每一次页面请求,需要从硬盘读取文件
③对于动态页面,还需要脚本的执行。如果启用Session的话,对于大数据量访问需要更多的内存消耗
(2)不要占用太多的客户端资源
爬虫程序建立与Web服务器的网络连接时,同样也要消耗本地的网络资源和计算资源。如果太多的线程同时运行,特别是一些长时间的连接存在,或者网络连接的超时参数设置不合适,很可能导致客户端有限的网络资源消耗。
1.2 爬行策略设计的综合考虑
不同网站上的Web页面链接图毕竟有自己独有的特点,因此,设计爬行策略时,需要进行一定权衡,考虑多方面的影响因素,包括爬虫的网络连接消耗以及对服务端所造成的影响等等,一个好的爬虫需要不断地结合Web页面链接的一些特征来进行优化调整。
对于爬虫来说,爬行的初始页面一般是某个比较重要的页面,如某个公司的首页、新闻网站的首页等。
从爬虫管理众多页面超链接的效率来看,基本的深度优先策略和宽度优先的策略都具有较高的效率。
从页面优先级的角度看,爬虫虽然从某个指定的页面作为爬行的初始页面,但是在确定下一个要爬行的页面时,总是希望优先级高的页面先被爬行。
由于页面之间的链接结构非常复杂,可能存在双向链接、环链接等情景
爬虫在对某个WEB服务器上页面进行爬行时需要先建立网络连接,占用主机和连接资源,适当对这种资源占用进行分配是非常必要的。
二、初次尝试网络爬虫
互联网中的网络之间互相连接,构成一个巨大的网络图:

网络爬虫就是从这个巨大复杂的网络体中,根据给定的策略,抓取所需要的内容
- 实例代码
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
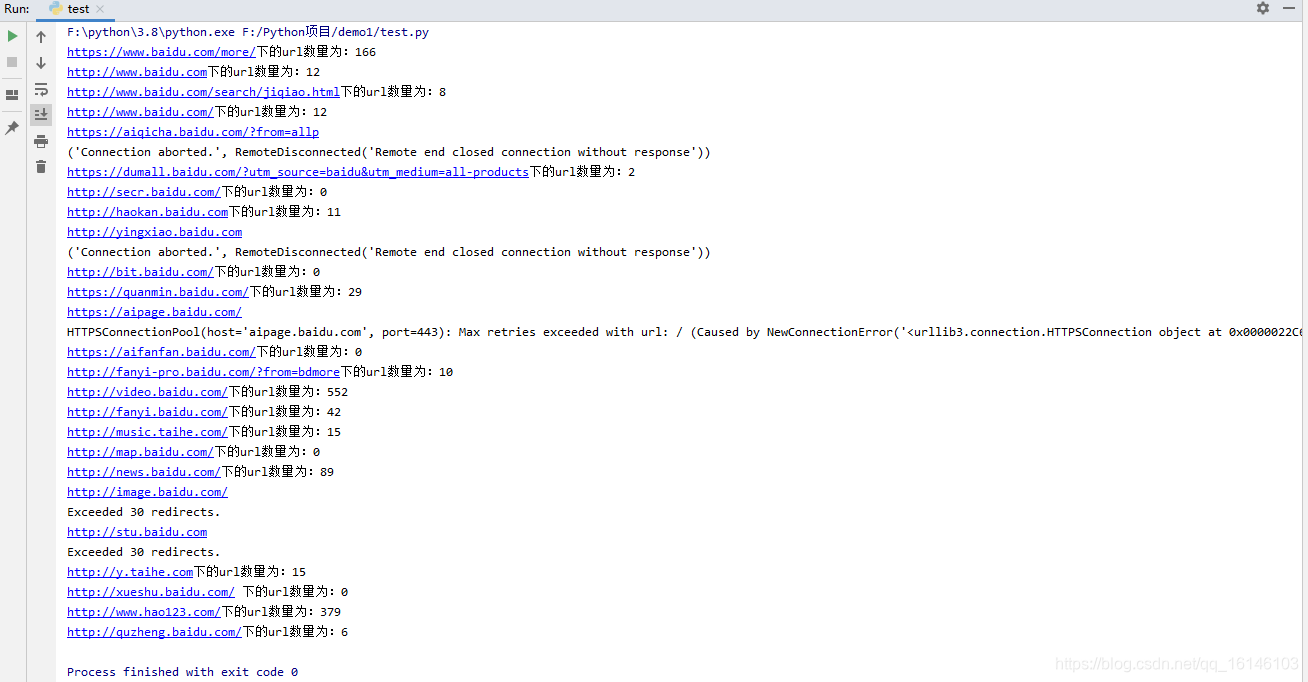
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 : try: url = queue.pop(0) html = requests.get(url).text storage[url] = html #将已经抓取过的URL存入used集合中 used.add(url) new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中 print(url+"下的url数量为:"+str(len(new_urls))) for new_url in new_urls: if new_url not in used and new_url not in queue: queue.append(new_url) count -= 1 except Exception as e : print(url) print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 2. 运行结果
我们可以感受下一个一级网页到下一级网页的链接能有多么多
三、抓取策略
从网络爬虫的角度来看,整个互联网可以划分为:
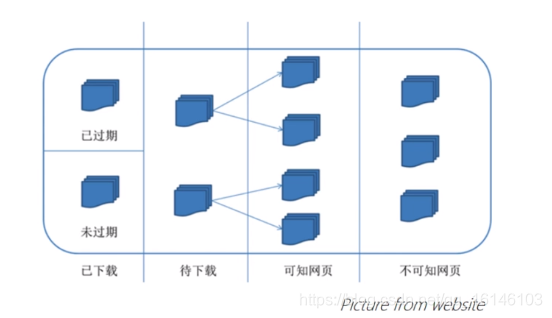
- 在网络爬虫的组成部分中,待抓取URL队列是最重要一环
- 待抓取队列中的URL以什么样的顺序排列,这涉及到页面抓取的先后问题
- 决定待抓取URL排列顺序的方法,成为抓取策略
- 网络爬虫使用不同的抓取策略,实质是使用不同的方法确定待抓取URL队列中URL的先后顺序
- 爬虫的多种抓取策略目标基本一致:优先抓取重要的网页
- 网页的重要性,大多数采用网页的流动性来进行度量
3.1、数据抓取策略
- 非完全PageRank策略
- OCIP策略
- 大站优先策略
- 合作抓取策略
- 图遍历算法策略
3.1.1、非完全PageRank策略
-
PageRank算法,是一种著名的超链接分析算法,用来进行网页排名,以谷歌创始人Larry Page命名。由于它解决了网络图中每个节点重要性的量化计算方法,因此在许多可以抽象为网络连接图的应用中得到广泛采用。 -
PageRank策略算法基于以下的思想对网页的重要性进行评分:
①一个网页被很多其他网页链接,该网页比较重要,PageRank分数回相对较高
② 一个PageRank分数高的网页链接到一个其他的网页,被链接到的网页的PageRank分数会相应提高


通常来讲,一个网页的PageRank分数计算如下:

- PageRank算法计算的对象是整个互联网页面的集合;而非完全PageRank策略则关注的是以下的页面集合:
①网络爬虫已经下载的页面
②待抓取URL队列的URL - 之后由两者组成的页面子集中,计算PageRank分数
- 根据PageRank分数,按照从高到低的顺序,将待抓取URL队列重排,形成新的待抓取URL队列
3.1.2、OPIC策略
OPIC,是Online Page Importance Computation的缩写,是一种改进的PageRank算法
OPIC策略的基本思想
- 将互联网的页面初始cash值设为1/N
- 每当网络爬虫下载页面a,将a的cash值平均分配给页面中包含的链接,再将自己的cash值设为零
- 将待抓取URL队列中的URL按照cash值进行降序排列,优先处理cash值高的网页
3.1.3、大站优先策略(比较粗暴)
大站优先策略的思路简单明了:
- 依据网站决定网页重要性,对于待爬取URL队列中的网页根据所属网站归类
- 等待下载的页面最多的网站,会得到网络爬虫的“优先考虑”
“大战”通常具有以下特点:
- 稳定的服务器,良好的网站结构
- 优秀的用户体验,及时的咨询内容
- 权威的相关资料,丰富的内容类型
- 海量的网页数,高质量的外链
如何识别要抓取的目标网站是否为大战?
- 人工整理大站名单,通过已知的大站发现其他大站
- 根据大站的特点,对将要爬取的网站进行评估(架构,内容,传播速度等)
3.1.4、合作抓取策略(需要一个规范的URL地址)
为了提高抓取网页的速度,常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,确保独立分工,避免重复爬取,这是合作抓取策略的目标
合作抓取策略通常使用以下两种方式:
- 通过服务器的IP地址来分解,让爬虫仅抓取某个地址段的网页
- 通过网页域名来分解,让爬虫仅抓取某个域名段的网页
3.1.5、图的遍历算法策略(★)
图的遍历算法主要分成两种:
- 深度优先(DFS,Depth First Search)
- 广度优先(BFS,Breadth First Search)
1、深度优先
深度优先从根节点开始,沿着一条路径尽可能深地访问,直到遇到叶节点时才回溯

- 深度优先由自己的优点,但更容易陷入无限循环
2、广度优先
使用广度优先策略的原因:
- 重要的网页往往离种子站点距离较近
- 互联网的深度没有那么深,但却出乎意料地宽广
广度优先遍历策略地基本思路
- 将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页
- 再选择其中一个链接网页,继续抓取在此网页中链接的所有网页
广度优先策略从根节点开始,尽可能访问离根节点最近的节点

3、Python实现
DFS和BFS具有高度的对称性,因此在Python实现时,并不需要将两种数据结构分开,只需要构建一个数据结构
- 在UrlSequenceUrl中设置的未访问序列self.unvisited可以完成出队列和栈的操作,前者通过pop(0)来实现,后者通过pop()实现。
- UrlSequenceUrl类存放了所有和URL序列有关的函数,维护了两个序列visited和unvisited,并实现了对URL的元素增加、删除、计数等操作,可以为爬虫的其他模块提供完整的封装,具体实现时选择一种遍历方式即可。
4、代码实现
- 1.用list模拟队列,实现BFS算法
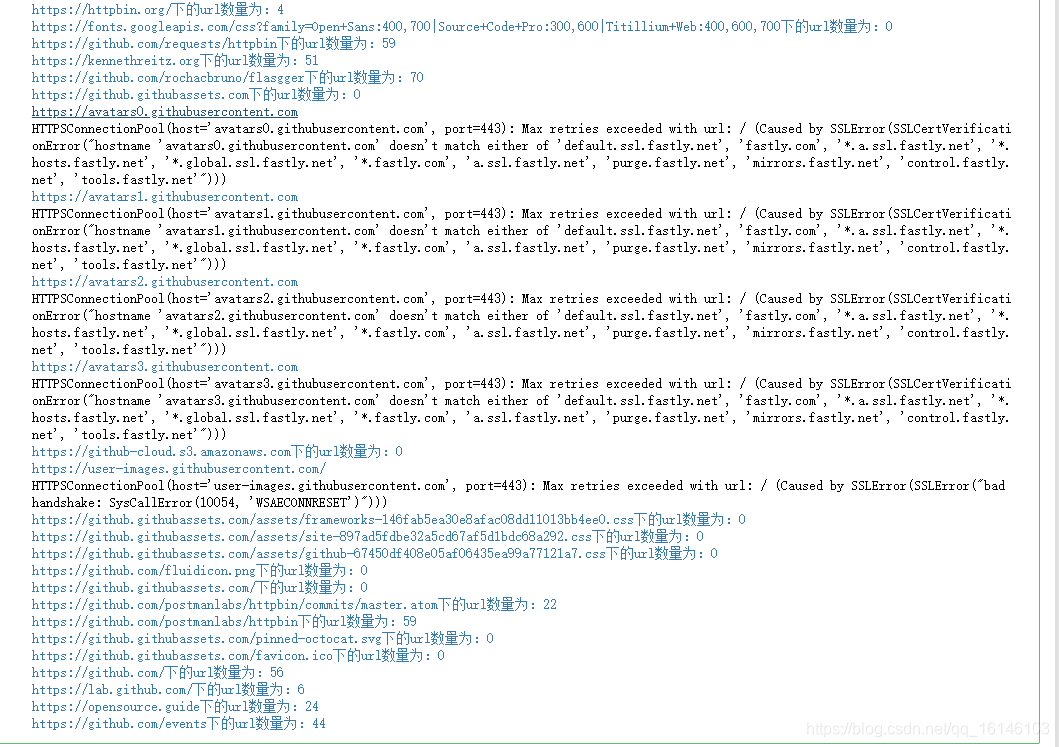
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 : try: url = queue.pop(0) html = requests.get(url).text storage[url] = html #将已经抓取过的URL存入used集合中 used.add(url) new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中 print(url+"下的url数量为:"+str(len(new_urls))) for new_url in new_urls: if new_url not in used and new_url not in queue: queue.append(new_url) count -= 1 except Exception as e : print(url) print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 2.用list模拟队列,实现DFS算法
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 : try: url = stack.pop(-1) html = requests.get(url).text new_urls = r.findall(html) stack.extend(new_urls) print(url+"下的url数量为:"+str(len(new_urls))) storage[url] = len(new_urls) count -= 1 except Exception as e : print(url) print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
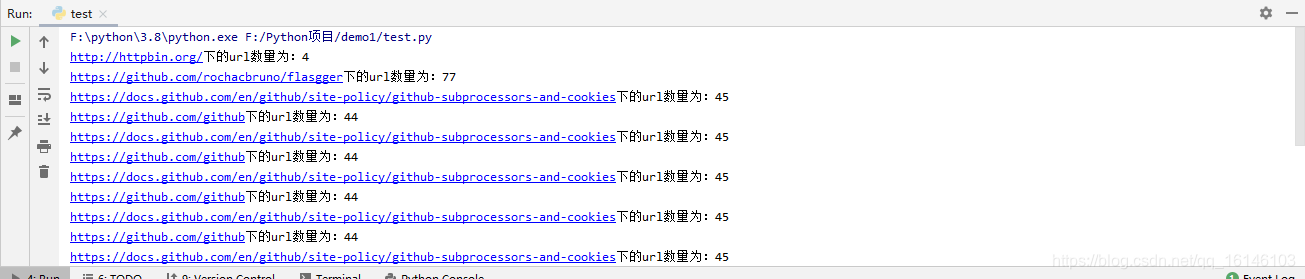
BFS 和 DFS 各有好处,DFS 更容易陷入无限循环,并且通常有价值的网页不会隐藏的太深,所以 BFS 通常是更好的选择。上面的代码是利用 list 来模拟栈或队列,Python 中还有一个 Queue 模块,其中包含了 LifoQueue 和 PriorityQueue,用起来会更加方便,
3.2、数据更新策略
- 抓取策略关注待抓取URL队列,也就是互联网中的待下载页面的合集
- 针对已下载的网页来说,互联网实时变化,页面随时会有变化
- 更新策略决定何时更新之前已经下载过的页面
常见的更新策略有以下几种:
- 历史参考策略:根据页面历史数据,预测页面的变化
- 用户体验策略:总和用户的浏览偏好,更新用户关注度高的网页
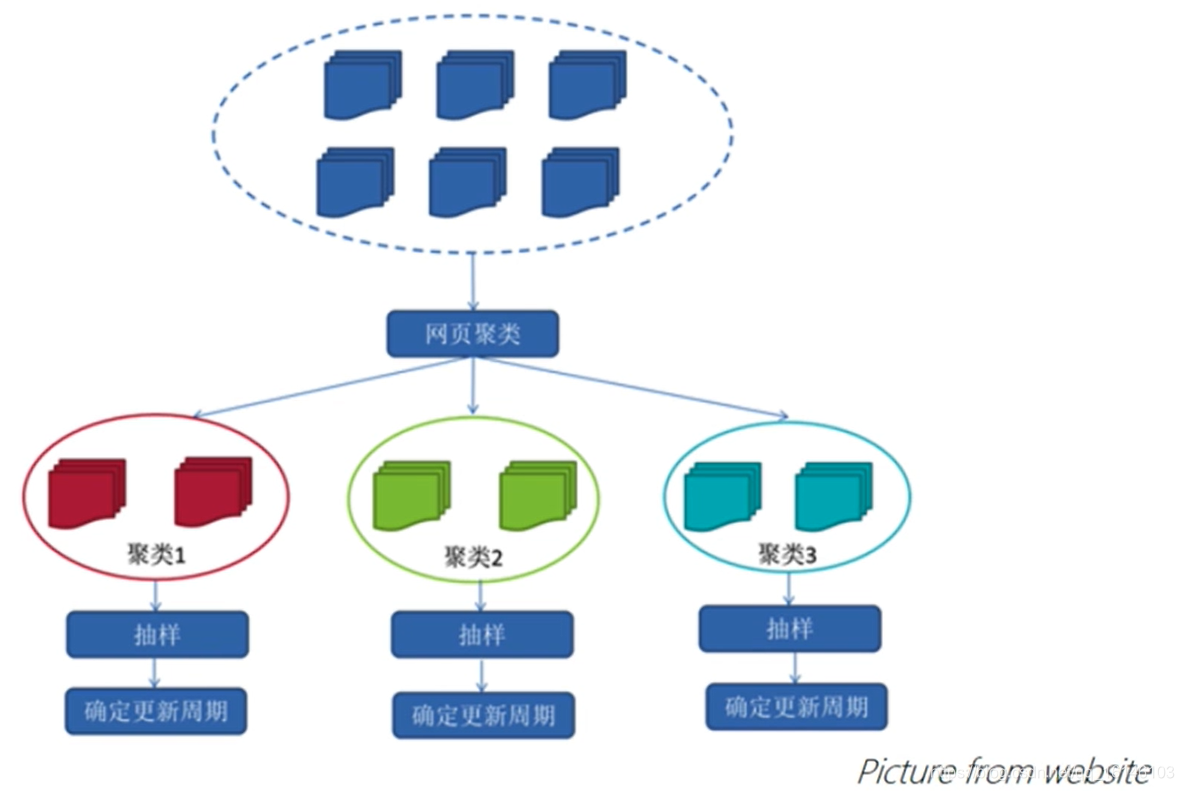
- 聚类抽样策略:根据页面的类别,确定页面的更新周期
聚类策略的基本思路

美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!


文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105213163

- 点赞
- 收藏
- 关注作者
评论(0)