大数据应用导论 Chapter03 | 大数据的存储与管理

大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
Chapter03 | 大数据的存储与管理
一、数据管理与存储概述
数据管理:数据收集、整理、组织、维护、检索等操作过程。
数据存储:应数据管理的需要而产生,存储技术的优劣直接影响数据管理的效率。
1、数据存储技术的发展
数据存储技术的发展分为以下四个阶段:
- 人工管理阶段
- 文件系统阶段
- 数据库阶段
- 分布式文件系统阶段
具体过程如图:

1.1、关系型数据库和非关系型数据库
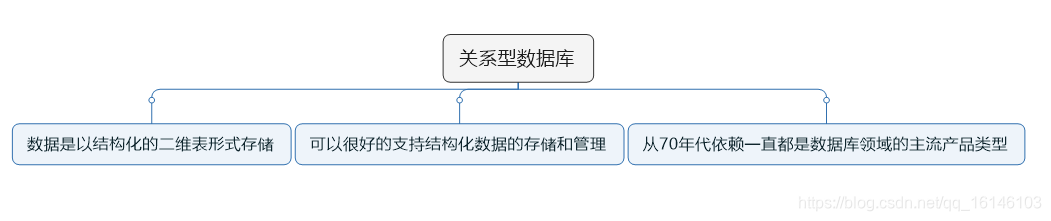
关系型数据库:
- 支持结构化数据存储和管理
- 支持事务ACID四个特征
- 从诞生以来一直是数据库领域的主流产品
非关系型数据库:
- 灵活的数据模型
- 良好的扩展性
- 易于海量数据的管理
1.2、分布式文件系统(GFS和HDFS)
谷歌开发的分布式文件系统(GFS):
- 通过网络实现文件在多台机器上的分布式存储
Hadoop分布式文件系统(HDFS):
- 针对GFS的开源实现
- 提供在廉价服务器集群中进行大规模分布式文件存储的能力
二、关系型数据库
**关系型数据库:**采用由图灵奖得主、有关系型数据库之父之称的E.F.Codd于1970年提出。
结构化数据:
- 具有规范的行列结构
- 存储在关系型数据库中的数据
结构化查询语言:查询和操作关系数据库的语言(Structual Query Language)简称SQL
关系型数据库的优势:
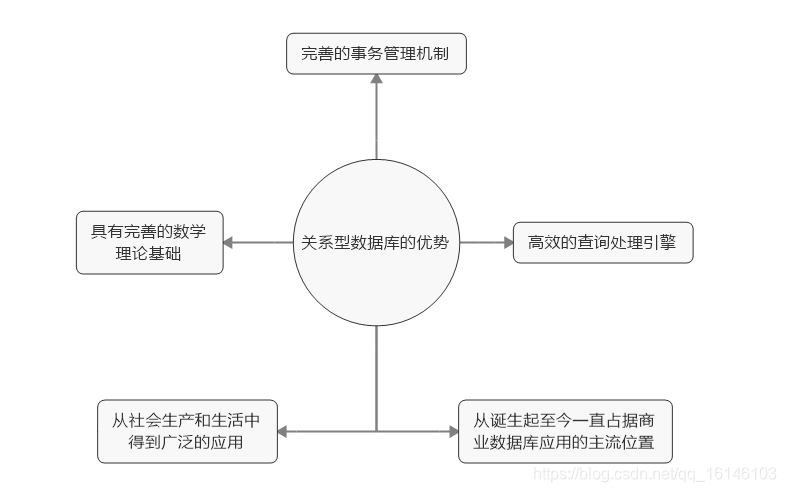
1、目前主流关系型数据库
SQLite:轻型嵌入式开源数据库,广泛应用于IOS和Android移动操作系统
Mysql:前三强中唯一开源数据库,在互联网中占据主导地位
Oracle:闭源,支持大并发,大访问量成熟稳定,安全性高
SQL Server:微软出品,目前最流行的数据库之一,通常和.net搭配使用
PostgreSQL:加州大学伯克利分校开发的,完全由社区驱动的开源项目
由于Mysql免费所以Mysql在当今的企业中占据主导地位。
Mysql数据库:
- 开源的关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司。
- 性能强劲,支持大型数据库,单表可容纳5000万条记录。
- 使用标准SQL语言,支持ACID事务属性。
- 分为社区版(免费)和企业版(收费)
2、MySQL的python接口创建
**MySQL的Python接口创建方法
1、导入Pymysql
Pymsql是在Python3中用于连接MySQL服务器的一个库。
导入方式为:import pymysql
- 连接对象connection:建立Python与数据库的连接。
- 游标对象cursor:用于执行sql命令。
通过以上两个对象,可以将采集的数据库保存到Mysql数据库中。
2、建立连接对象connection
conn = pymysql.connect(host="localhost",user="root",passwd="199712",db="hackdata",charset="utf8")
- 1
3、游标对象cursor
cursor = conn.cursor()
- 1
4、在cursor对象中执行sql语句
创建表,表明为douban
sql = """CREATE TABLE douban ( id int(5) not null auto_increment primary key, public_name CHAR(100) NOT NULL , book_number int(10), picture_link char(100) )"""
cursor.execute(sql)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5、在cursor对象中执行sql语句
在数据表中插入值
insert_douban = "INSERT INTO douban (public_name,book_number,picture_link) VALUES (%s,%s,%s)"
data_douban = (public_name[i],book_number[i],picture_link[i])
cursor.execute(insert_douban,data_douban)
- 1
- 2
- 3
- 4
6、插入完毕后提交事务,并关闭游标和连接对象
conn.commit()
cursor.close()
conn.close()
- 1
- 2
- 3
3、MySQL查询
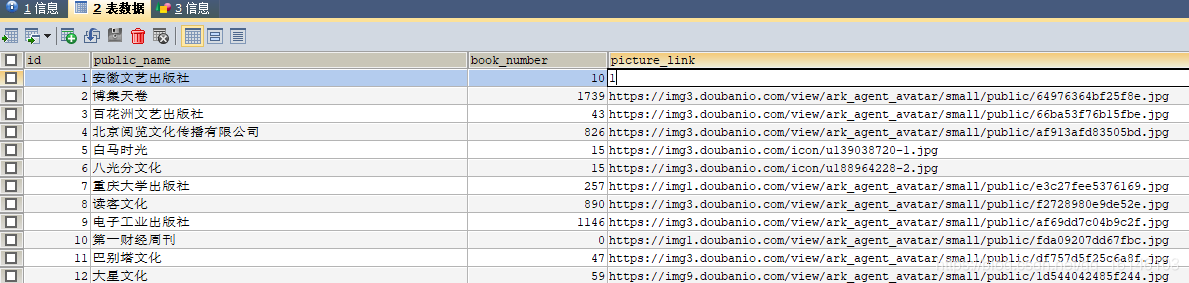
关系型数据库存储结构化数据,类似Excel二维表,表中4列分别为:
- id——编号
- public_name——出版社名称
- book_number——出版数目
- picture_link——出版社图片链接

我们在实际使用数据时,可以使用SQL语句从数据库中筛选符合条件的数据。
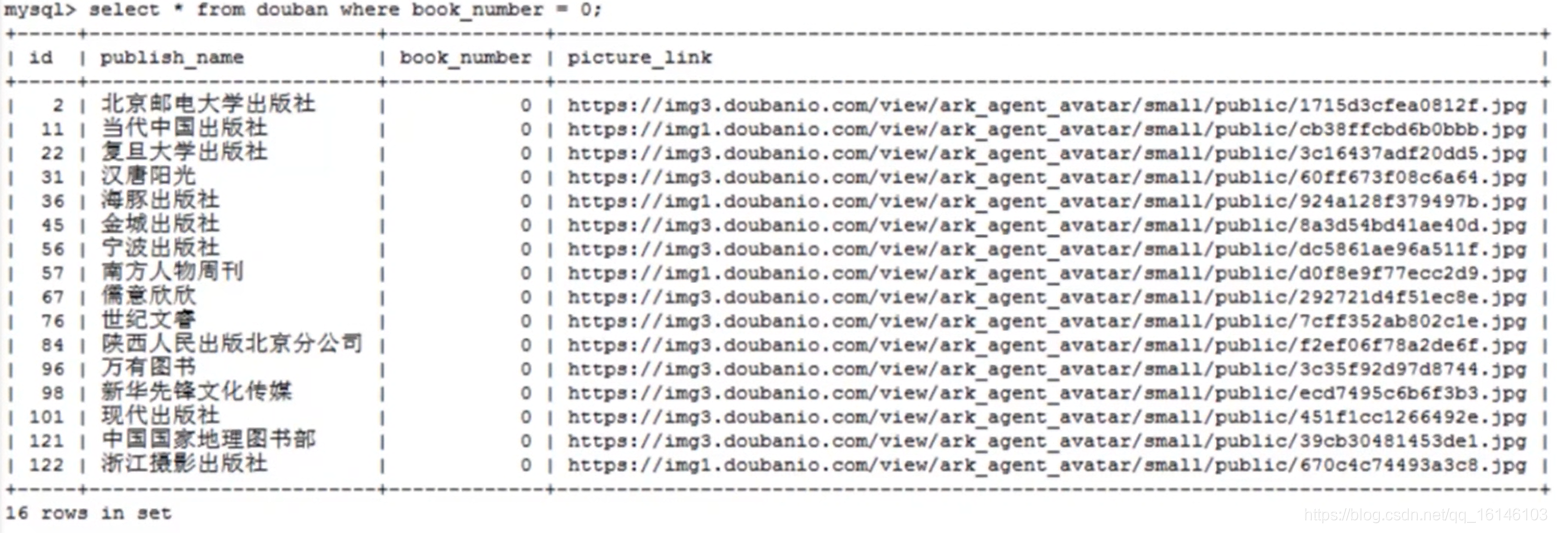
比如选出在售书目数量为0的出版社信息:
select * from douban where book_number = 0
- 1
总结:
关系型数据库遇到的瓶颈:
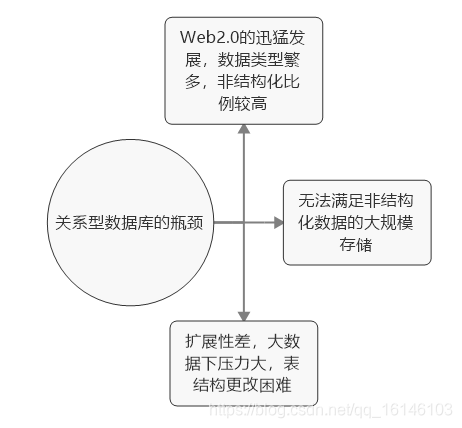
在关系型数据库遇到瓶颈的背景下,非关系型数据库(NoSQL)数据库应运而生:
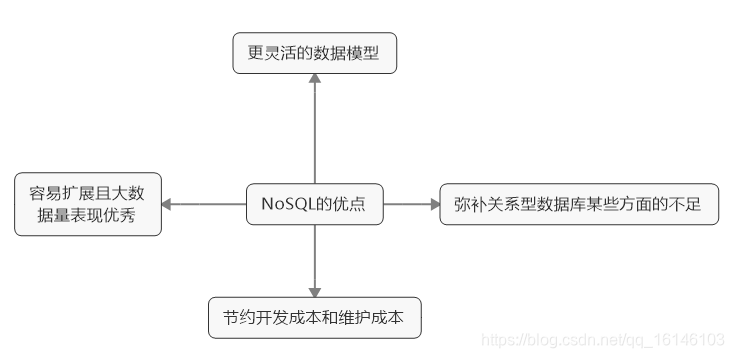
4、MySQL案例演示
完整代码为:
import pymysql
import re
import requests
## 建立连接
conn = pymysql.connect(host="localhost",user="root",passwd="199712",db="hackdata",charset="utf8")
#获取游标
cursor = conn.cursor()
# 删除表
cursor.execute("DROP TABLE IF EXISTS douban")
sql = """CREATE TABLE douban ( id int(5) not null auto_increment primary key, public_name CHAR(100) NOT NULL , book_number int(10), picture_link char(100) )"""
cursor.execute(sql)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
res = requests.get("https://read.douban.com/provider/all",headers=headers).text
pat1='<div class="name">(.*?)</div>'
public_name = re.compile(pat1).findall(res)
pat2='<div class="works-num">(.*?) 部作品在售</div>'
book_number = re.compile(pat2).findall(res)
pat3='<div class="avatar"><img src="(.*?)"'
picture_link=re.compile(pat3).findall(res)
for i in range(len(public_name)): insert_douban = "INSERT INTO douban(public_name,book_number,picture_link) VALUES (%s,%s,%s)" data_douban = (public_name[i],book_number[i],picture_link[i]) cursor.execute(insert_douban,data_douban)
conn.commit()
cursor.close()
conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
最终运行结果为:

三、非关系型数据库
近年来,NoSQL数据库发展势头非常迅猛。在短短四五年内,NoSQL爆炸性的产生了50-150个新的数据库。(http://nosql-database.org)。
其中MongoDB(一种文档数据库)极度火热。
MongoDB的本地安装:https://www.mongodb.com/download-center?jmp=nav#community
Robo3T可视化工具安装:https://robomongo.org/download
1、MongoDB简介
- 由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
- 数据存储为一个文档,数据结构由键值对(key、value)组成。
- 在高负载的情况下,添加更多的节点,可以保证服务器性能。
2、MongoDB存储方式
- 将数据存储为一个文档,数据结构由键值对(key、value)组成
- 类似于JSON对象,已与存储非结构化数据
文档类似于关系型数据库中的行,但不必为二维表结构,存储更为灵活方便。


3、MongoDB的Python接口
Pymongo是在Python3中用于连接MongoDB服务器的一个库。
- 数据库连接对象client:建立Python客户端与数据库的连接。
- 指定数据库,指定集合,再通过insert数据插入数据。
通过以上两个步骤,将Python爬虫采集的数据保存到MongoDB数据库中。
步骤:
1、引入pymongo库
import pymongo
- 1
2、建立连接对象
conn = MongoClient('localhost',27017)
- 1
- localhost代表本机地址,也可以写成127.0.0.1
- 27017为mongodb的默认端口号
3、自定数据库和集合名称
db = conn.movie_test
collection = db.top250
- 1
- 2
4、插入数据
collection.insert_one(movie)
- 1
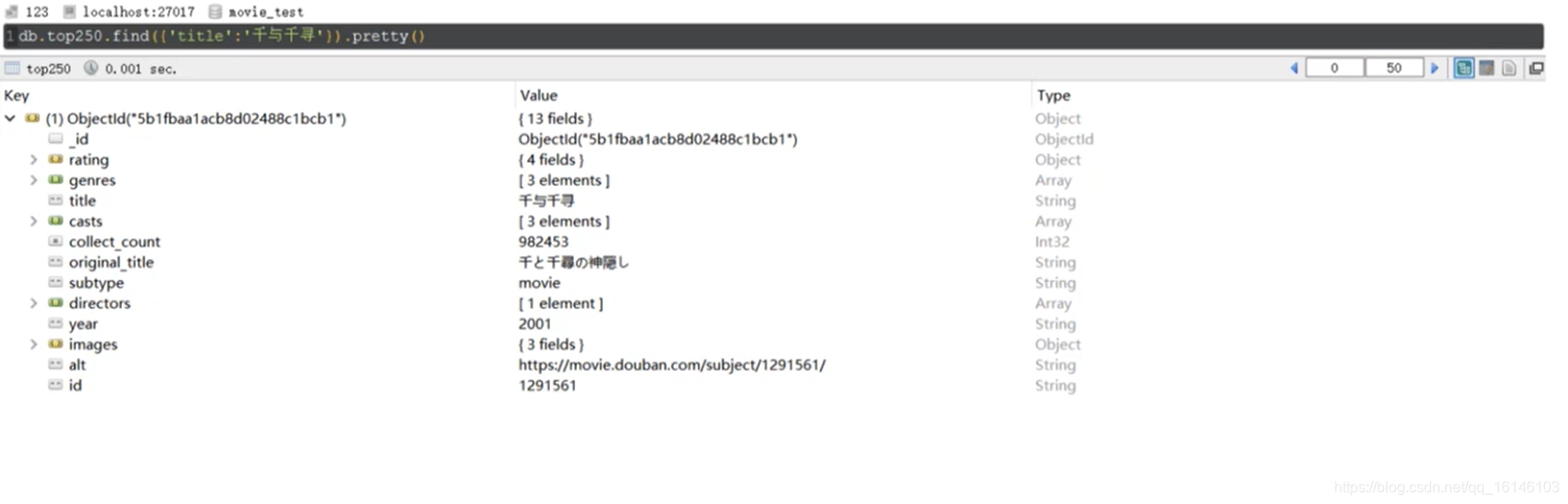
下图为事先爬取的豆瓣top250的电影信息,并存储到MongoDB数据库中。

实际使用中,可以使用find命令从数据库中筛选符合条件的数据。
筛选电影《千与千寻》的影片信息:
db.top250.find({'title':'千与千寻'}).pretty()
- 1
总结:
- NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
- SQL和NoSQL都有各自的特点和使用的应用场景。
- 关系型数据关注在关系上,NoSQL关注在存储上。
上述的完整代码:
import requests
from time import sleep
from pymongo import MongoClient
# 连接(服务器地址、端口号)
conn = MongoClient('localhost',27017)
# 选择数据库
db= conn.movie_test
# 选择表
collection = db.top_250
# 采集数据
url = 'https://movie.douban.com/top250'
for start in range(0,250,25): r = requests.get(url,params={'start':start,'count':25}) print('processing %s' % r.url) res = r.json() for movie in res['subjects']: collection.insert_one(movie) print(movie['title'],'saved') sleep(0.1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
四、分布式文件系统
1、概述
大数据时代的到来促成了分布式文件系统:
- 互联网上一分钟内有3万小时的音乐播放记录
- 43万次维基百科页面的访问记录
- 4百万条谷歌搜索记录
- 单台计算机磁盘无法存放海量数据
1.1、分布式存储:
- 可将海量数据分配到多个操作系统管理的磁盘中进行存储。
- 获取数据时,必须知道数据的存储位置,比较麻烦。

1.2、分布式文件系统
- 各个节点可分布在不同地点,通过网络进行节点间的通信和数据传输。
- 节点符合主从结构,主节点存储元数据,从节点存储时间数据。
- 调用数据时,不用关心数据在从节点的存储位置,客户端向主节点发送请求即可。

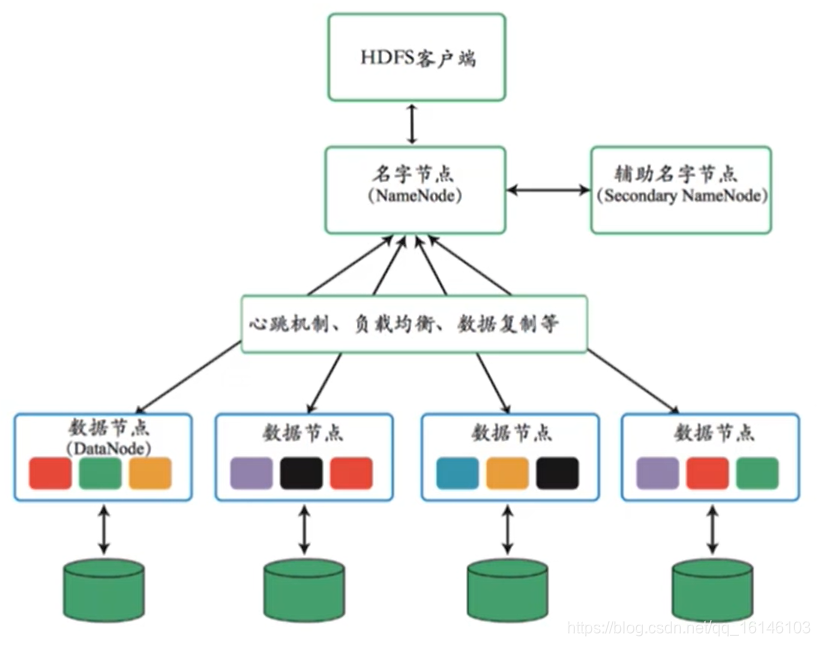
2、HDFS体系结构
- Hadoop生态系统中包含一系列数据存储、数据分析的组件。
- 其中HDFS为Hadoop中的分布式文件系统,实现数据存储。

2.1、体系结构
- Namenode
- Datannode
- Secondary Namenode
1、Namenode

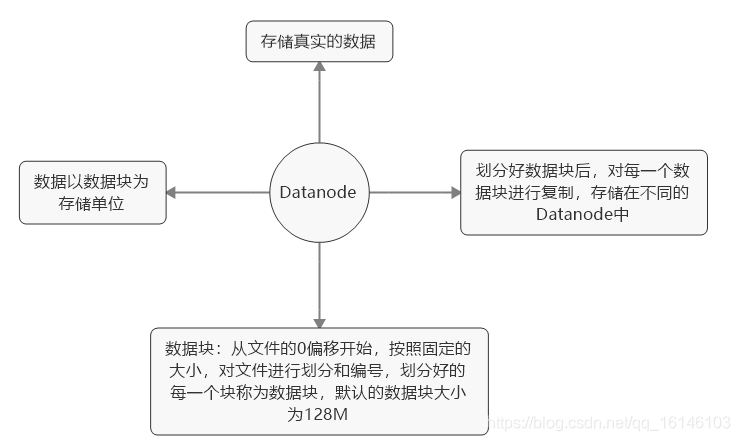
2、Datanode
3、Secondary Namenode
- 通常,只有一个Namenode进行集群的管理
- Secondary Namenode会同步Namenode的信息。
- 当Namenode出现故障时,Secondary Namenode会立即替代Namenode。
2.2、运行过程
1、心跳机制
- Datanode和Namenode之间的通信时通过心跳机制来实现。
- Datanode定期向Namenode发送报告。
- 超过设定时间,Namenode没有接收到Datanode的报告时,认为该Datanode宕机。
- Namenode不会再向Datanode分配资源。
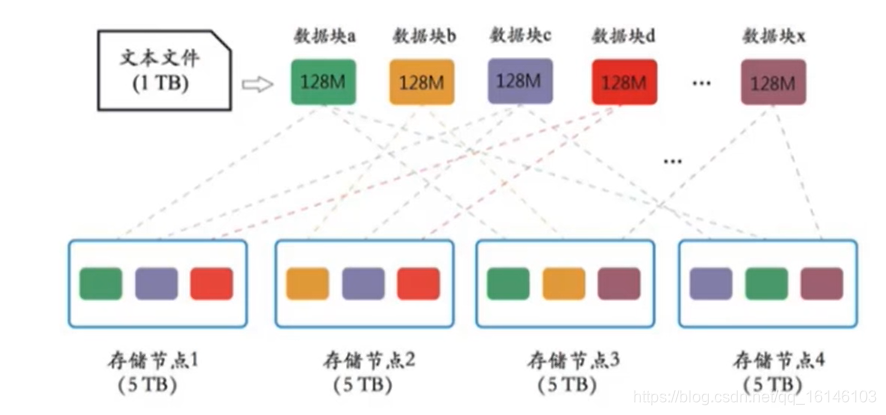
2、数据复制
- HDFS能够在各个从节点上自动保存数据的多份备份。
- 任何节点出现故障,数据仍可靠存储在其它节点上。
- 可从其他节点恢复该节点的数据。
3、负载均衡
- 数据复制时,需要balancer命令配置Threshold平衡Datanode的磁盘利用率。
- 先统计所有Datanode磁盘利用的平均值。
- 若某个Datanode磁盘利用率超过平均值,将Datanode上的数据块转移给磁盘利用率低的Datanode,所以可实现新增节点的数据自动分配。
2.3、从HDFS中的读取和写入
1、读取数据
- 客户端向Namenode发送请求并检查客户端的权限。
- Namenode向客户端发送数据的存储地址和安全令牌。
- 客户端到达存储数据的节点,向Datanode出示安全令牌。
- Datanode允许客户端读取特定的数据块。
- 若Datanode终止,Namenode向客户端共享该数据块的其他位置。
- 读取完成,关闭连接。
2、写入数据
- 客户端向Namenode发送写入请求。
- Namenode验证客户端身份。
- Namenode向客户端共享地址和安全令牌。
- 客户端写入操作完成后,Datanode复制数据。
- 复制完成,客户端进行确认。
2.4、HDFS的优缺点
1、优点
- 高容错性:
单个节点发生故障,备份机制使得HDFS可从其它节点获取数据,系统可持续运行。
- 高可用性:
允许文件通过网络在多台机器上进行分享。
- 更高效:
多台机器同时进行读取或者写入,极大缩短了读写时间。
2、缺点
- 一次写入,多次查询:
只支持一个写入者,文件写入后,不能进行修改。
- 不适合大量小文件存储:
Namenode会限制文件的存储数量。
- 数据访问有高延迟:
高吞吐会导致高延迟。
3、HDFS环境搭建
3.1、在Centos6.5下搭建Hadoop集群
搭建步骤:

- 安装成功后Hadoop之后,可输入jps查看Hadoop是否运行成功。

登录前端查看集群状态:http://192.168.138.2.100:8088/cluster
3.2、HDFS的简单操作
1、创建文件
bin/hdfs dfs -mkdir /data
- 1

2、上传文件
将爬取的豆瓣文件放在HDFS中的根目录上:
bin/hdfs dfs -put /home/douban.txt /
- 1

3.3、通过JAVA进行交互
- HDFS有JAVA接口
- 使用HDFS的shelll命令时,需要在虚拟机中进行操作或者使用交互式软件Xshell等进行操作。
- 通过编写JAVA程序,可在本地对HDFS中的文件进行读写操作,输出结果更加美观。
- 当前主流的JAVA集成开发环境——Eclipse、IntelliJ IDEA。
1、创建文件
- FileSystem.get()获取HDFS文件系统
FileSystem fs = FileSystem.get(conf);
- 1
- mkdirs()创建新文件
fs.mkdirs(new Path("/data"))
- 1
完整代码如下:
public class test2{
@Test
public void testMKdir() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.2.100:9000");
FileSystem fs = FileSystem.get(conf);
fs.mkdirs(new Path("/data"));
fs.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 使用的数据类型和方法均属于org.apache.hadoop包。
- 创建所有方法时,要抛出异常,或用try-catch。
2、上传文件
- 使用FileInputStream()以流的方式读入文件:
FileInputStream in = new FileIputStream("D:/hackdata/douban.txt");
- 1
- 使用creat()在HDFS中创建新文件:
FSDataOutputStream out = fs.create(new Path("/data/new"),ture);
- 1
- 使用HDFS自身接口快速拷贝文件:
IOUtils.copyBytes(in,out,4096,true);
- 1
完整代码:
public class test1{
@Test
public void testUpload() throws IOException{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.2.100:9000");
FileSystem fs = FileSystem.get(conf);
FileInputStream in = new FileIputStream("D:/hackdata/douban.txt");
FSDataOutputStream out = fs.create(new Path("/data/new"),ture);
IOUtils.copyBytes(in,out,4096,true);
fs.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

3、读取文件内容
open(path)打开指定路径的文件:
FSDataInputStream fis = fs.open(path);
- 1
声明字节数组bytes,以字节流方式读入数据:
byte[] bytes = new byte[1024];
- 1
字节数组转化为字符串类型,并进行打印:
System.out.println(new String(bytes,0,len));
- 1
完整代码:
public class test3{
@Test
public void testRead() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.2.100:9000");
FileSystem fs = FileSystem.get(conf);
Path = new Path("/data/new");
FSDataInputStream fis = fs.open(path);
byte[] bytes = new byte[1024];
int len = -1;
while ((len = fis.read(bytes))!=-1){ System.out.println(new String(bytes,0,len));
}
fis.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

4、删除文件
- 使用delete(path,recursive)删除文件:
fs.delete(new Path("/data"),ture);
- 1
- ture表示递归删除,即删除文件目录下的所有文件。
完整代码:
public class test4{
@Test
public void testDelete() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.2.100:9000");
FileSystem fs = FileSystem.get(conf);
fs.delete(new Path("/data"),ture);
fs.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105078086

- 点赞
- 收藏
- 关注作者
评论(0)