数据清洗 Chapter01 | 数据清洗概况

这篇文章讲述的是数据存储方式和数据类型等基本概念、数据清洗的必要性和质量评价的关键点。希望这篇数据清洗的文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
一、什么是数据
从广泛的意义上来讲,数据是一个宽泛的概念
- 计算机中的0101代码
- 日常生活中的音乐,图片,视频等
- 人类的语言、文字
- 了解数据清洗,需要理解数据的内涵和外延
1、数据的类型
- 1、表格数据
关系记录、数据矩阵、向量、事务数据

- 2、图和网络
万维网、社交网络、分子结构
- 3、多媒体数据
文本、图像、视频、音频
2、表格数据
在此,只了解表格数据
-
1、数据集(数据库)
-
由数据对象构成
-
一个数据对象表示一个实体
-
2、概念
下面的这些表示相似的概念,在不同的地方可以交叉使用
- 样本(samples or examples)
- 对象(objects)
- 实例(instances)
- 元组(tuples)
- 数据点(data points)
数据对象由属性(attributes)及其值(value)构成
表格数据中的行为数据对象,列为特征。如下图:

3、属性类别
类型:
-
名义型(Nominal)
-
布尔型(Binary)
-
等级型(Ordinal)
-
数值型(Numeric)
-
3.1、名义型
对数据对象进行分类或分组,使同类同质,异类异质
eg:
汽车品牌 ={路虎,奥迪,大众,奥拓}
学校 = {北大,清华,武大}
其值只是不同类别的代码,不能区分大小写,更不能进行任何数学计算
- 3.2、布尔型
布尔型数据是在条件或循环中的条件判断
Python中布尔类型对应两个布尔值:True和False,分别对应1和0

- 3.3、等级型
将数据对象分成不同的类型
确定所分类别的等级差别和序列差别
eg:
身高:高、中、低
年级:三年级、二年级
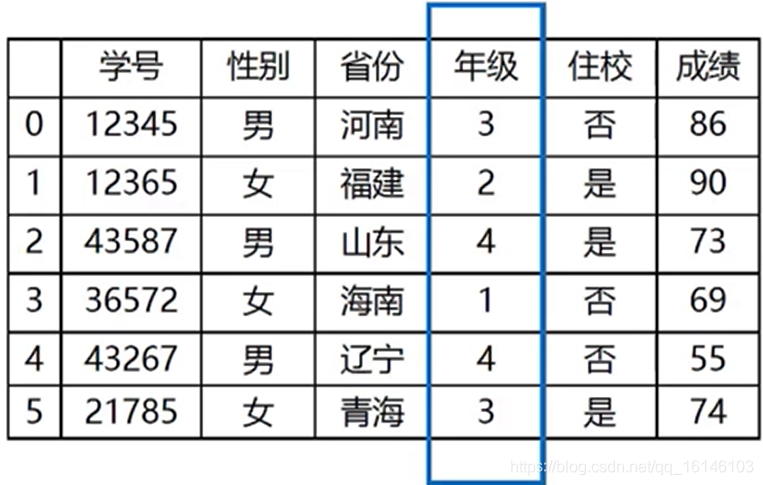
等级行只能比较大小,不能进行数学计算
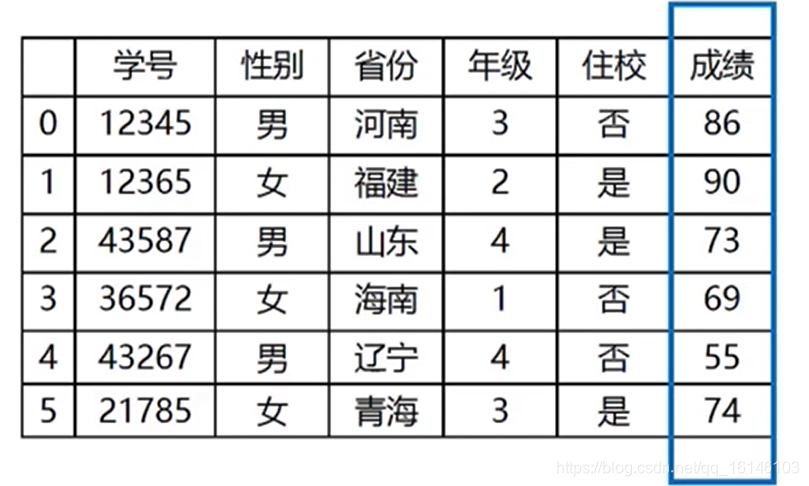
- 3.4、数值型
最常见的数据类型
直接使用自然数或可进行测量的具体数值
可直接用数值计算方法进行汇总和分析
二、数据清洗
1、什么是数据清洗
脏数据

- 数据清洗
从一个充满拼写错误,缺失值,异常值等问题的原始数据集(Raw Data)通过数据转换,缺失处理,异常处理等手段映射为一个符合质量要求的“新”数据集(Consistent Data)的过程

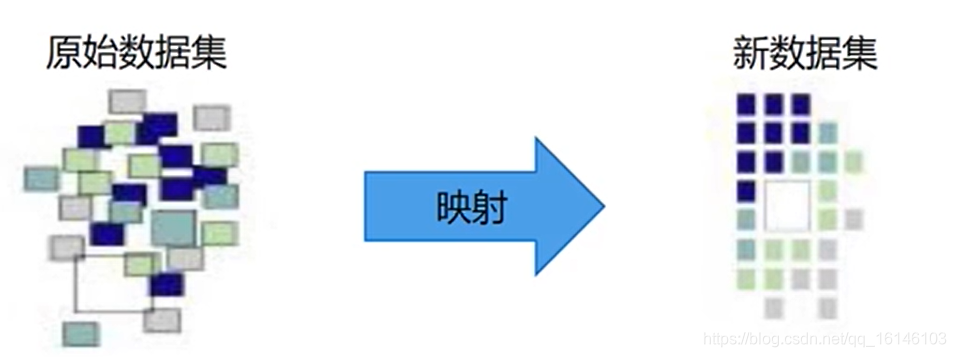
数据清洗在大数据分析流程中的位置

2、为什么要进行数据清洗
- 从不同渠道获得的数据,集成在一起,组成新的数据集,需要进行数据清洗,来保证数据集的质量
- 数据分析算法对输入的数据集有要求
- 显示情况下的数据集质量不禁如人意,需要数据清洗
3、数据存在的问题
- 1、单数据源
- 违背属性约束条件:日期,电话号码,身份证号等
- 属性违反唯一性:主键同一取值出现多次
- 数据更新不及时
- 数据存在噪音
- 数据存在拼写错误
- 数据存在相似,重复记录
- 2、多数据源
- 同一属性存在不同的名称:人的真实姓名和绰号
- 同一属性存在不同的定义:字段的长度测量单位,类型不一致
- 数据存在重复,拼写错误
- 数据的汇总时间不一致:按照年度,季度,月度统计
- 数据的存储单位不一致:按照GB,TB为单位存储
三、数据质量评估
如何评估数据的质量?
准确性,一致性,时效性,完整性,数据重复,数据冗余
易用性和可维护性
相关性和可信度
- 1、准确性
考察数据集记录的信息是否存在异常或错误
业务数据通常存在特征取值缺失,特征缺失,主键缺失等问题
问题多发生在数据的源头,由各种主客观原因(主观录入错误,数据需求不明确,数据提供者故意隐瞒等)所导致
要获得高质量的数据集,需要把控好数据收集,数据录入的源头
- 2、一致性
考察数据是否符合统一规范,数据记录是否保持统一格式
数据一致性问题通常存在于数据整合阶段:
来自不同数据源的数据汇总在一起,特征的表述不相同
相同的特征名称在不同的数据源中代表不同的含义
- 1、特征名称不同,含义相同
通过其相应的取值范围和与其他特征的相似性,来找出这些指标对特征名称进行统一
在医疗指标数据中,有reference字段,代表指标值的正常值范围
如:身高的reference会是150-180,体重会是50-80
通过reference来初步判断哪些指标代表的含义相同
- 2、特征名称相同,含义不同
不同医疗器械采集的数据中通常含有名称为蛋白的字段,但特征可能指尿蛋白,也可能指血蛋白
在实际操作中需要组合成新的特征(尿蛋白,血蛋白)
- 3、时效性
考察数据从产生到分析的时间间隔,也称为数据的延长时长
数据集所代表的信息并不一定能正确描述当前的情形
爬取动态网页内容
由于网页内容,结构都在变化,获取的数据带有明显的时效性
考虑到数据获取的时间成本
数据分析的周期不能过长,否则会导致分析的结论失去现实意义
- 4、完整性
考察数据信息是否存在缺失,包括数据集的字段以及数据记录
- 5、数据重复
考察数据特征,数据记录的重复情况
- 6、易用性和可维护性
考察数据的使用与访问情况,以及数据的更新,维护状况
- 7、相关性和可信度
考察数据与相关业务的相关情况,参考数据的实用性
- 8、数据冗余
考察数据集特征之间的相关性
如果一个特征可由另一个特征推导出来,那么这两个特征存在冗余
年龄可由生日推算获得,那么年龄和生日之间存在冗余
计算两个特征之间的相关系数来测量二者的冗余程度
计算两个特征之间的相关系数可以来测量二者之间的冗余程度
- 1、连续型数据相关性检验:
Pearson相关系数用于计算连续型变量之间的相关性
公式:

其中,ρA,ρB分别为变量A和B的标准差
相关系数r的取值范围为[-1,1]
r>0,特征A和特征B呈正相关关系
r=0,特征A和特征B独立,不存在相关性
r<0,特征A和特征B呈负相关关系
|r|值越大,两个特征之间的相关性越高
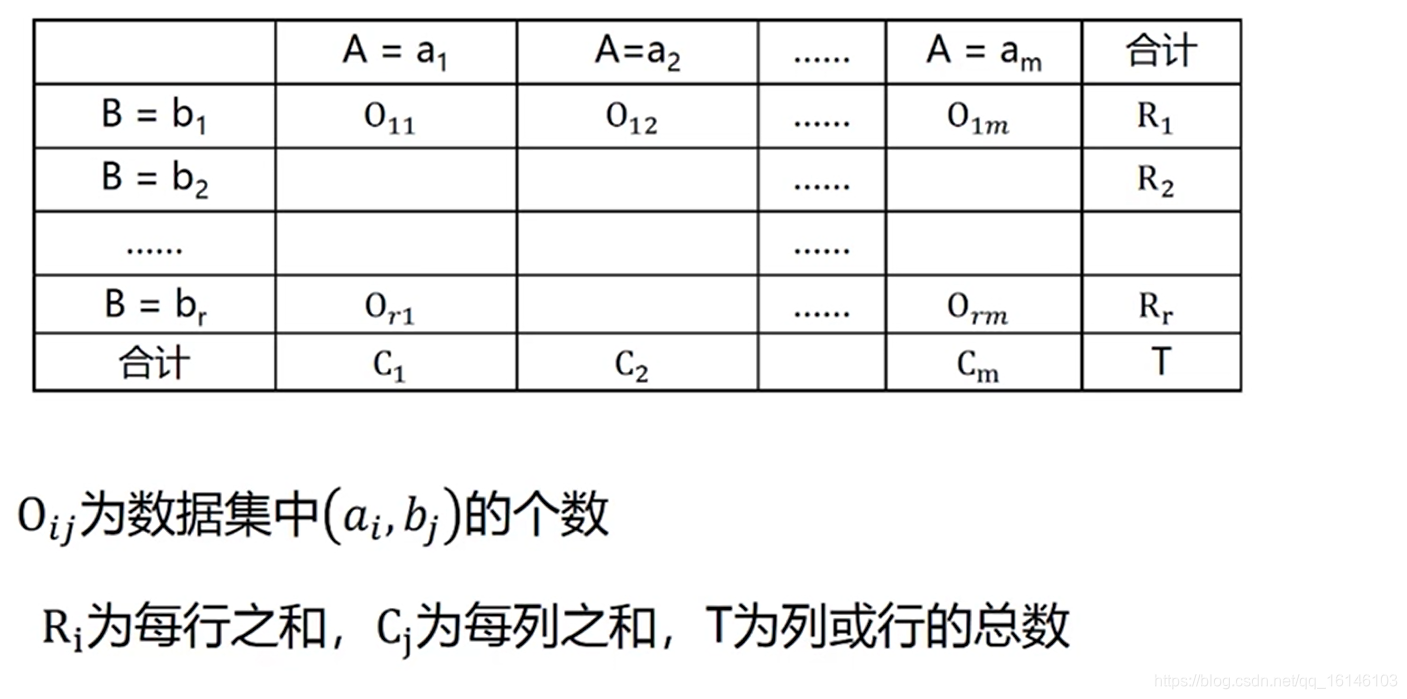
- 2、离散型数据相关性检测:
卡方独立性检验用于离散型数据的相关性检测 ,也成为列联表(contingency table),卡方检验
卡方独立性检验的步骤:
零假设:变量A和变量B无关
水平:确定显著水平α
检验:依据零假设,计算卡方值
确定自由度,根据自由度查临界值表进行推断
eg:

卡方值和自由度计算
计算公式:
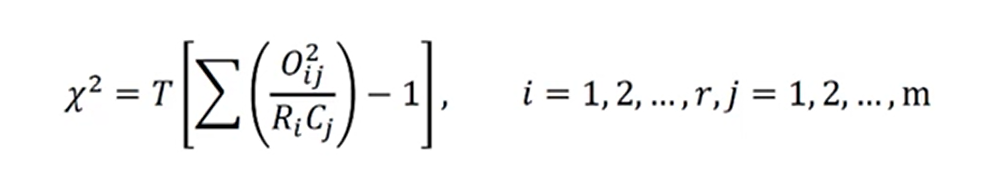
自由度计算公式:

四、数据清洗的主要内容
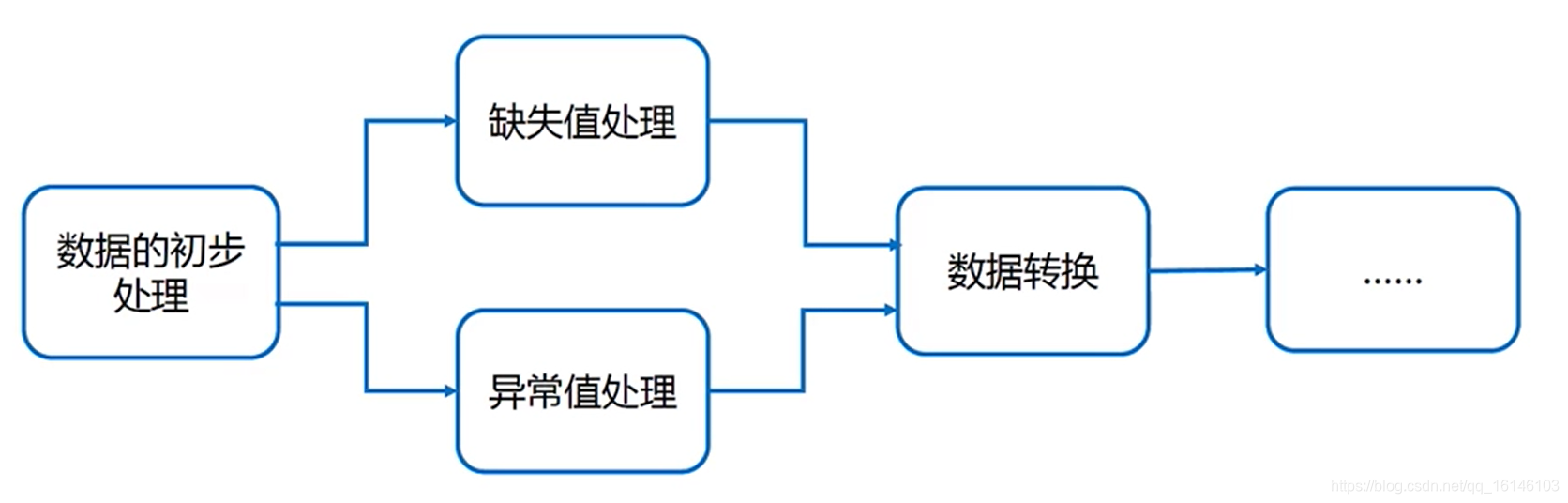
- 1、数据初步处理
使用Python的标准库或者第三方库读入数据,或者将数据读入数据库
使用数据可视化手段观察数据的取值分布情况
对数据进行整合或分组
- 2、缺失值处理
确定缺失值的范围,以及所站比例
取出不需要的特征
使用缺失值填补等方法对缺失值进行填充
- 3、异常值处理
检测异常值:基于统计,举例,密度的检测方法,复杂方法如孤立森林
处理检测值:删除异常值
保留异常值:选择鲁棒性更强的学习算法
- 4、数据转换
数据的格式进行统一:不同数据文件格式的转换
数据去重:取出重复的数据几率,提高算法进行效率
数据标准化:消除数据单位,量纲不同带来的影响
数据离散化:将连续型数据转换为离散型数据,增强模型对于异常值的鲁棒性
各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是本人更新博客的动力!!!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105427932

- 点赞
- 收藏
- 关注作者
评论(0)