R语言入门 Chapter05 | 因子

【摘要】
不登高山,不知天之高也;不临深溪,不知地之厚也。 ——荀子
这篇文章讲述的是R语言中关于数据框的相关知识。希望这篇R语言文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
Chapter05 | 因子
在R中名义型变量和有序性变量称为因子,factor。这些分类变量的可能值称为一个水平,level,例如good,better...
不登高山,不知天之高也;不临深溪,不知地之厚也。 ——荀子
这篇文章讲述的是R语言中关于数据框的相关知识。希望这篇R语言文章对您有所帮助!如果您有想学习的知识或建议,可以给作者留言~
在R中名义型变量和有序性变量称为因子,factor。这些分类变量的可能值称为一个水平,level,例如good,better,best,都称为一个leve。
由这些水平值构成的向量就称为因子。
所有元素构成因子
因子类型的数据:
- state.division
- state.region
因子的应用:
-
1、计算频数
-
2、独立性检验
-
3、相关性检验
-
4、方差分析
-
5、主成分分析
-
6、因子分析
-
1、频数统计
# cyl这一列可以当作因子类型
> mtcars$cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> table(mtcars$cyl)
4 6 8
11 7 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 2、如何将向量转换为因子
使用factor()函数
> f <- factor(c("red","red","green","red","blue","green","blue","blue"))
> f
[1] red red green red blue green blue blue
Levels: blue green red
# 有序性变量也可以作为因子
# 不定义levels时levels自动去重
> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Fri Mon Sun Thu Wed
# 自定义levels不允许重复
> week <- factor(c("Mon","Fri","Thu","Wed","Mon","Fri","Sun"),order = TRUE,
+ levels = c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))
> week
[1] Mon Fri Thu Wed Mon Fri Sun
Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun
# 一个向量转换成因子,直接输入到factor()内即可
> fcyl <- factor(mtcars$cyl)
> fcyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
Levels: 4 6 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
-
3、向量和因子图形的对比
-
向量
plot(mtcars$cyl)
- 1
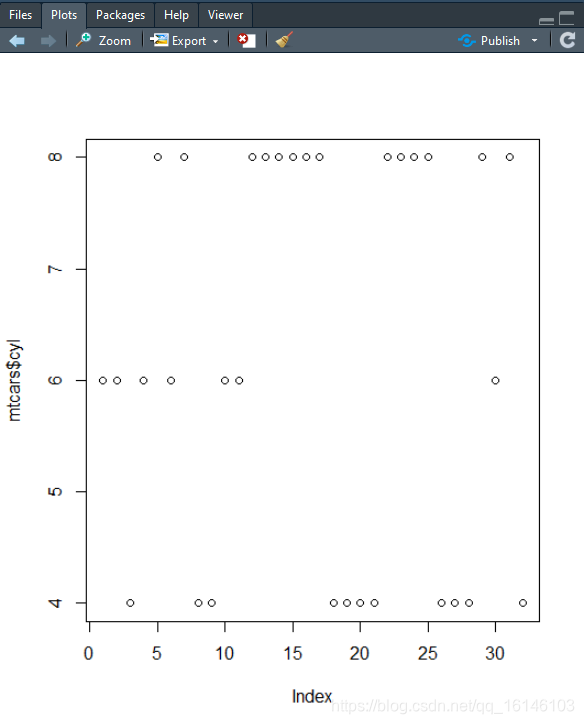
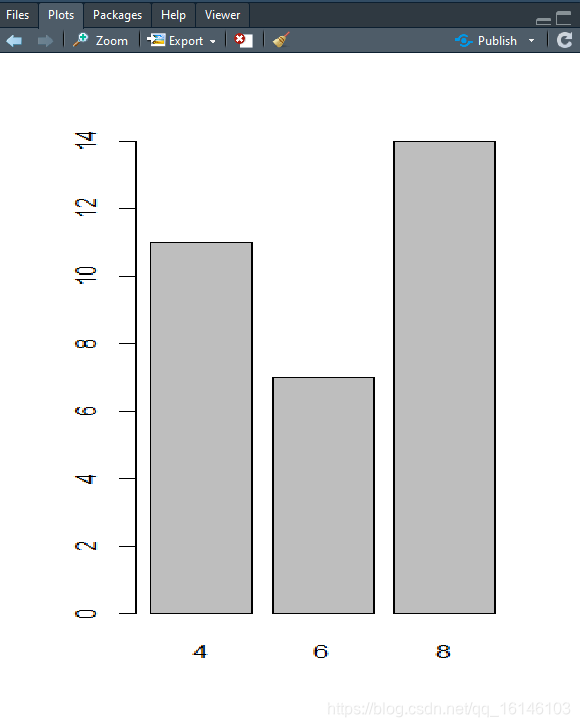
- 因子
plot(fcyl)
- 1
- 4、cut()函数
cut函数可以将连续性变量x分割为n个水平的因子
> num <- c(1:100)
> num
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
[45] 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66
[67] 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88
[89] 89 90 91 92 93 94 95 96 97 98 99 100
# 每隔10个进行分组
> cut (num,c(seq(0,100,10)))
[1] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] [10] (0,10] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20] (10,20]
[19] (10,20] (10,20] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30]
[28] (20,30] (20,30] (20,30] (30,40] (30,40] (30,40] (30,40] (30,40] (30,40]
[37] (30,40] (30,40] (30,40] (30,40] (40,50] (40,50] (40,50] (40,50] (40,50]
[46] (40,50] (40,50] (40,50] (40,50] (40,50] (50,60] (50,60] (50,60] (50,60]
[55] (50,60] (50,60] (50,60] (50,60] (50,60] (50,60] (60,70] (60,70] (60,70]
[64] (60,70] (60,70] (60,70] (60,70] (60,70] (60,70] (60,70] (70,80] (70,80]
[73] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (70,80] (80,90]
[82] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90] (80,90]
[91] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100] (90,100]
[100] (90,100]
10 Levels: (0,10] (10,20] (20,30] (30,40] (40,50] (50,60] (60,70] (70,80] ... (90,100]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
如果数字较大,我们可以通过cut()函数进行频数统计,很方便
各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是本人更新博客的动力!!!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105420919

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)