快速入门网络爬虫系列 Chapter10 | 数据结构化存储

【摘要】
Chapter10 | 数据结构化存储
一、结构化过程1、非结构化数据2、半结构化数据3、结构化数据
二、怎样数据结构化1、明确数据需求2、选择数据结构3、怎么存
三、半数据化结构3.1、JSON3.2、XML(可广泛应用)1、XML的特性1、一个简单的XML例子2、使用xml.etree生成xml
我们先来了解下数据化结构与非数...
我们先来了解下数据化结构与非数据化结构
一、数据化结构
数据化结构,简单来说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统、医疗HIS数据库、教育一卡通、政府行政审批、其他核心数据库等
二、非结构化数据
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频信息等等

- 在使用结构化数据的同时,数据的体量和多样性都会降低,同时降低的还有操作数据需要的相关技术难度、数据分析前准备数据所花费的时间以及业务用户评价数据所花费的精力。
一、结构化过程
1、非结构化数据
- “《互联网大数据处理技术与应用》一书是由曾剑平编著,并由清华大学出版社于2017年出版。”
- “ 清华大学出版社成立于1980年6月,是由教育部主管、清华大学主办的综合出版单位。”
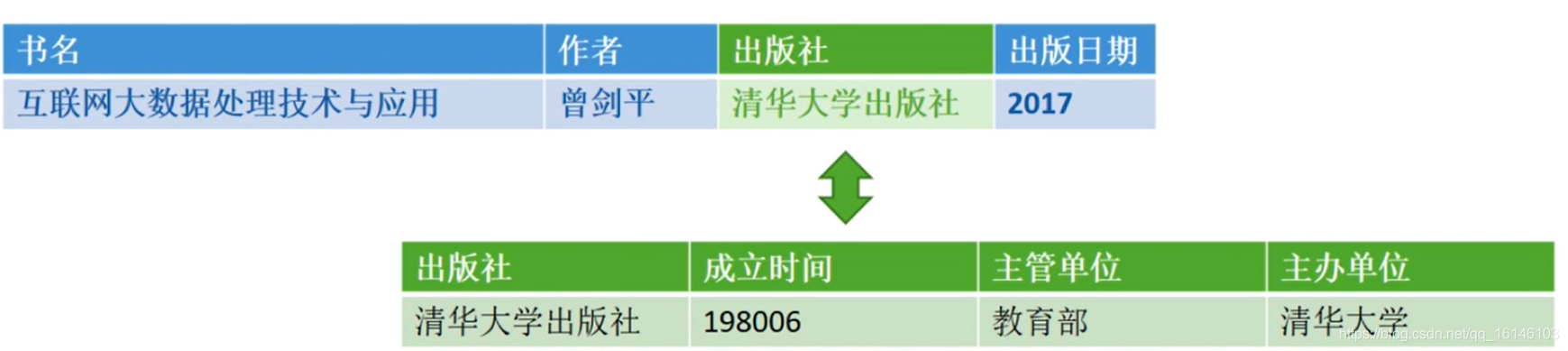
2、半结构化数据
- (书名:互联网大数据处理技术与应用;作者:曾剑平;出版社:清华大学出版社;出版日期:2017)
- (出版社:清华大学出版社;成立时间:198006;主管单位:教育部;主办单位:清华大学)
3、结构化数据
二、怎样数据结构化
1、明确数据需求
- 需要抽取什么数据
- 存放成什么格式
- 怎么存
2、选择数据结构
- 半结构化:XML、JSON
- 结构化:数据库
3、怎么存
- 文件:单独还是一起存放,如何发展数据关系
- 数据库:数据库设计
三、半数据化结构
3.1、JSON
- API常用格式
- 数据结构简单
- 有Python Json库支持
- 可以和Python字典结构相互转化
3.2、XML(可广泛应用)
- 可扩展标记语言,标记通用标记语言的子集,是一种用于标记电子文件使其具有结构化的标记语言
1、XML的特性
可扩展标记语言可以对文档和数据进行结构化处理,从而能够在部门、客户和供应商之间进行交换,实现动态内容生成,企业集成和应用开发
- 准确的搜索
- 方便的传送软件组件
- 更好的描述一些事物
- 设计宗旨是传输数据,而不是显示数据
- 标签没有背被预定义,需要自行定义标签
- 具有自我描述性
1、一个简单的XML例子
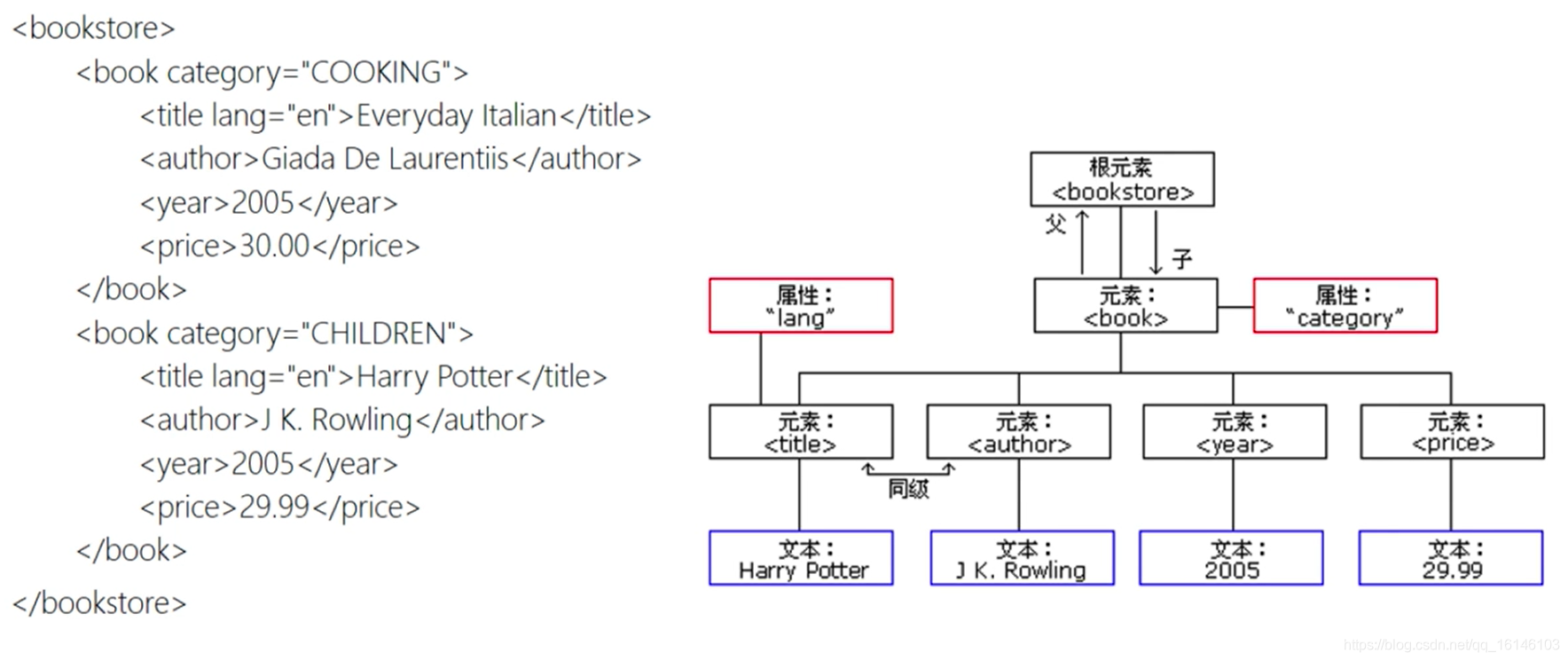
2、使用xml.etree生成xml
在这里主要使用xml.etree这个子包
import xml
from xml import etree
from xml.etree.ElementTree import ElementTree
root = etree.ElementTree.Element("root")
root.append(etree.ElementTree.Element("child1"))
child2 = etree.ElementTree.SubElement(root,"child2")
child3 = etree.ElementTree.SubElement(root,"child3")
print(xml.etree.ElementTree.tostring(root))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

爬虫场景中可以使用
- json+xml迭代完成xml与json的相互转化
- 使用xmltodict包
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105264905

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)