快速入门网络爬虫系列 Chapter16 | 爬虫性能提升

一、基础简介
1、任务调度
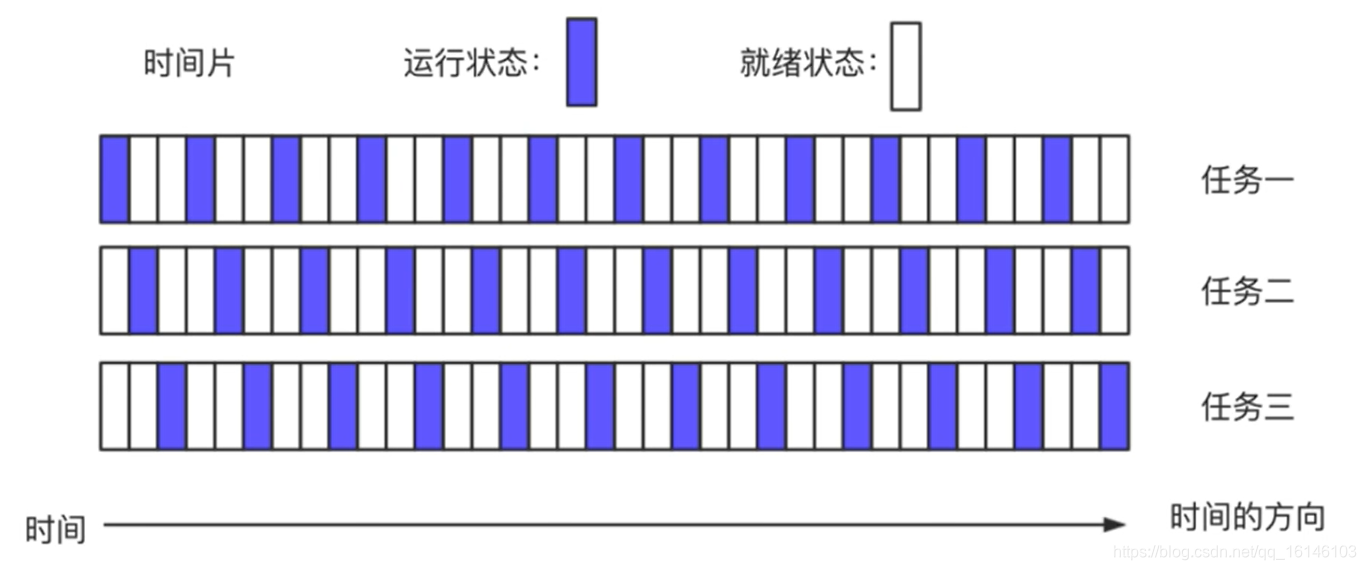
操作系统通常采用时间片轮转的抢占式调度方式
一个任务执行一段时间后强制暂停,去执行下一个任务
每个任务轮流执行
2、线程与进程
2.1、进程
具有独立功能的程序在数据集合上的一次动态执行过程
系统进行资源分配和调度的一个独立单位
任务调度的最小单位
以资源管理器为例
2.2、线程
线程是CPU调度和分派的基本单位
能独立运行
基本上不拥有系统资源,可与通一个进程的其他线程共享进程的资源
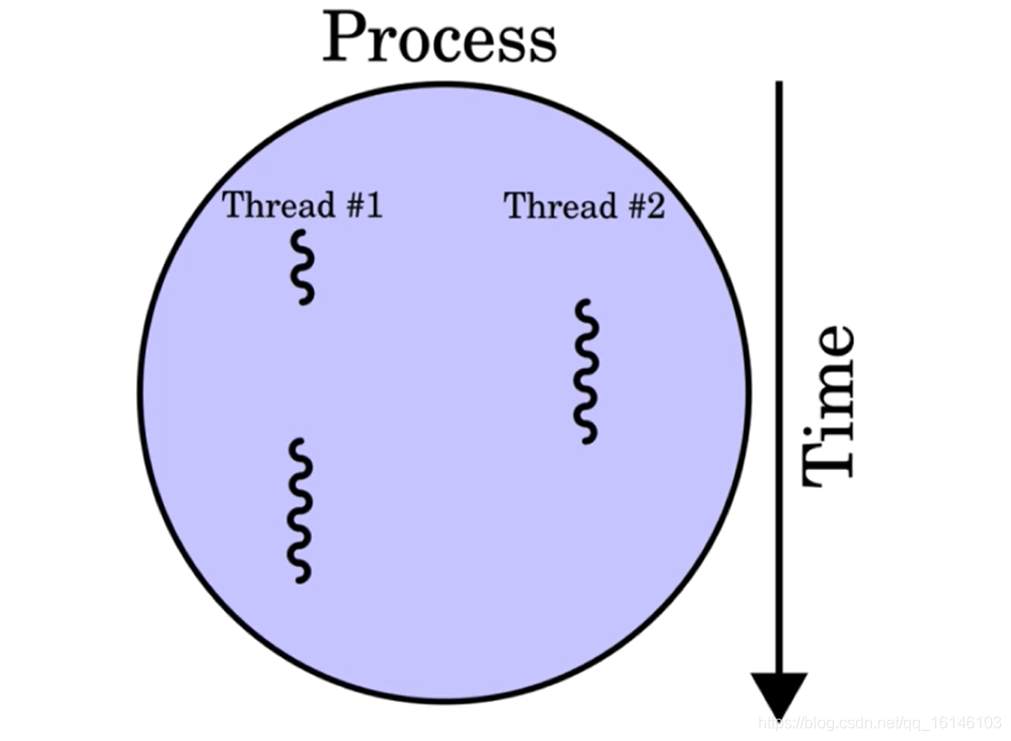
一个进程中可以有多个线程
线程与进程的关系
2.3、线程与进程的联系
线程被称为轻量级进程,和进程一样拥有独立的执行控制
一个进程包含多个线程,线程是进程对的一个实体
一个线程可以创建和撤销所属进程中的另一个线程
同一个进程中的多个线程之间可以并发执行
2.4、线程与进程的区别
线程不像进程一样拥有独立的内存空间
线程和所属进程的其他线程共享内存空间
线程之间的通讯更加简单
3、多线程
目前为止,开发的爬虫都属于单线程,不能充分利用硬件资源和带宽资源
多线程是一种常用的提高效率的手段,可以提升网络爬虫性能
Python语言中的threading库提供易用的对线程API
3.1、多线程的原理
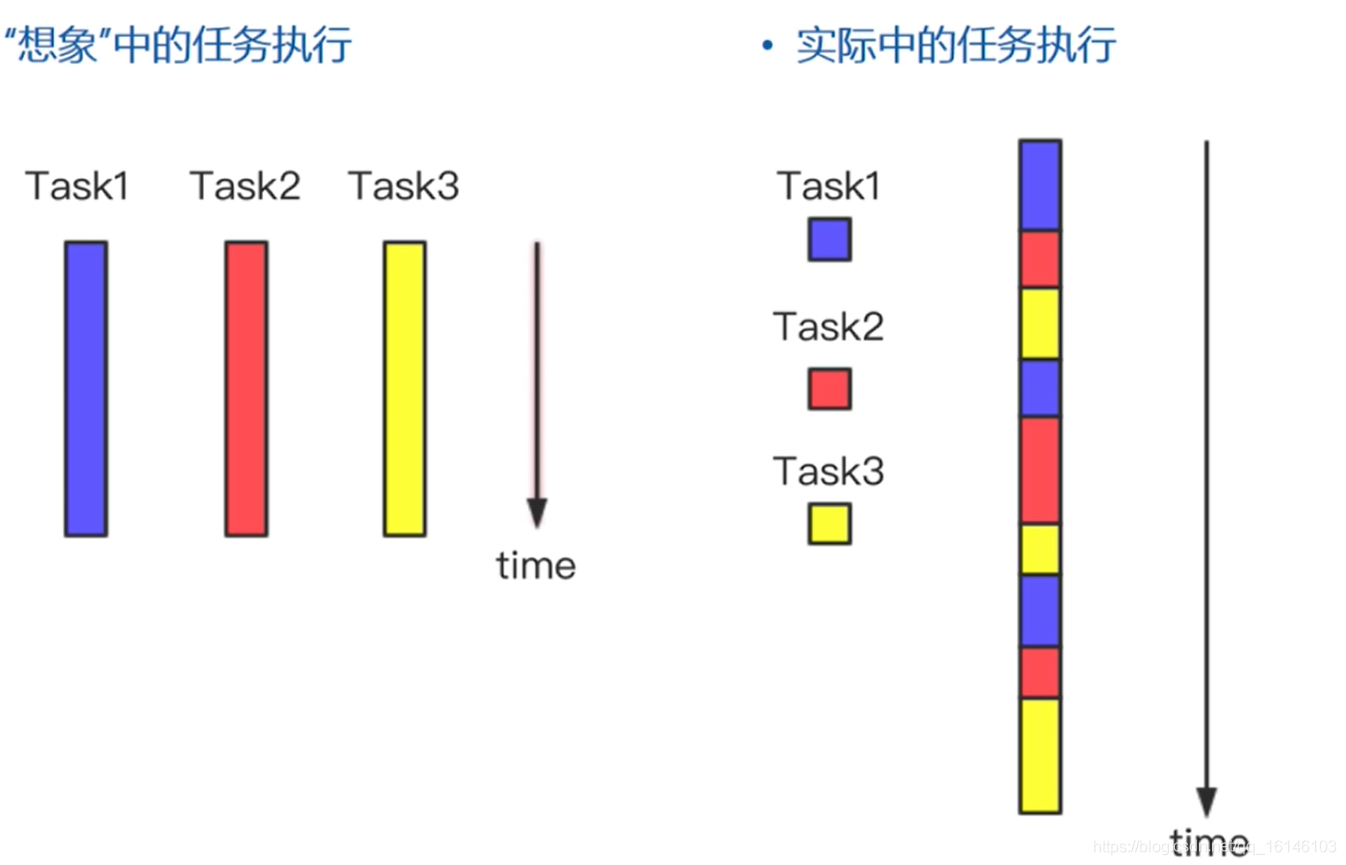
在同一进程中,程序的执行在不同线程之间切换
每一时刻,CPU只处理一个线程
CPU在不同线程之间快速切换,给人一种同时处理多个线程的错觉
一个线程等待网页下载时,进程可以切换到其他线程执行任务,避免浪费CPU资源
3.2、多线程爬虫结构
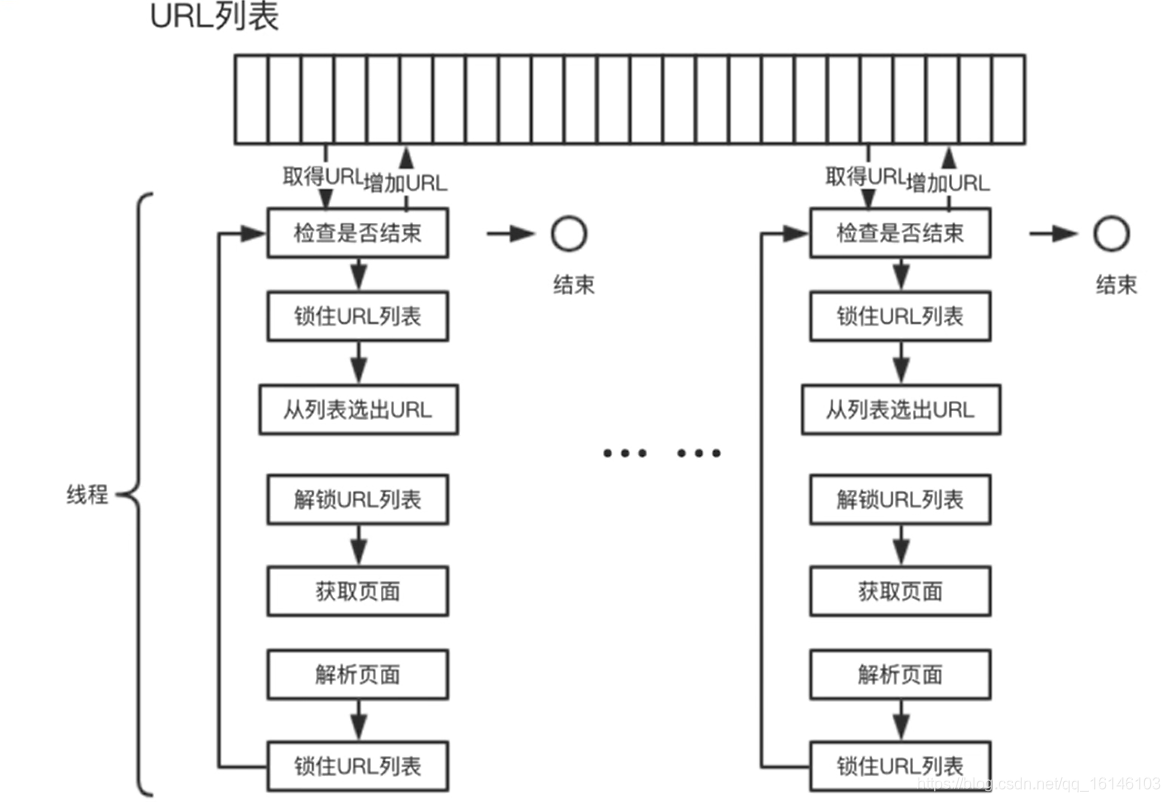
使用多线程爬虫结构可以提高爬虫的效率。
3.3、多线程的优势
多线程的目的是更大限度的利用CPU资源
当某一线程的处理不需要占用CPU,只和I/O等资源打交道时,其他线程有机需要获得CPU资源
对于计算密集型的应用,CPU间歇,同时其他可运行的资源较少。此时,CPU不能“腾出手来”处理其他线程
3.4、与单线程相比
对爬取1000个网页的效果进行对比
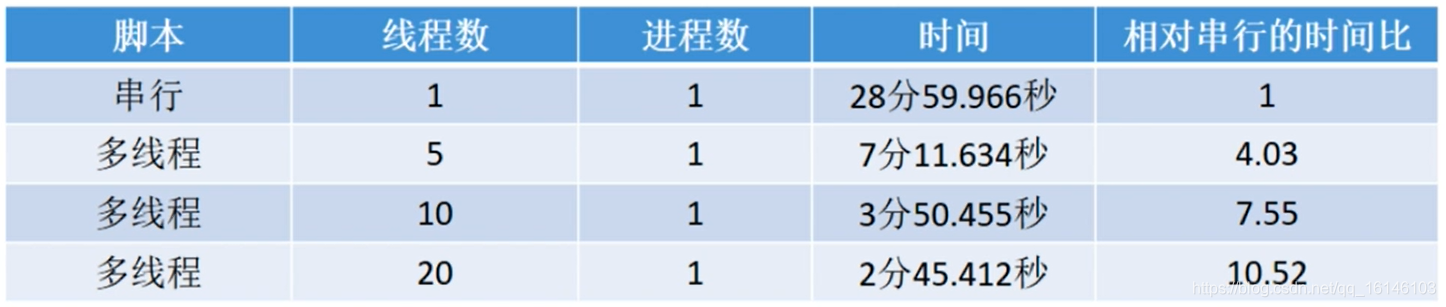
举例:
豆瓣电影使用单线程
%%time
import requests
import re
base_url = 'https://movie.douban.com/tag/喜剧'
params = {'start':'0','type':'T','timeout':'5'}
html = requests.get(base_url,params=params).text
r = re.compile('<a calss="nbg" .* title=\"?(.*)\"')
print(','.join(r.findall(html)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

3、Python的多线程模块
Python提供多个模块来支持多线程编程
thread:提供基本的线程和锁定支持
threading:提供更高级别的、功能更全的线程管理
Queue:创建队列数据结构、用于多线程之间进行共享
- 选用threading模块来实现多线程
- 相较于thread模块
threading包含thread模块的大部分功能
threading包括许多非常好用的同步机制
3.1、threading模块
Thread类:threading模块的主要执行对象
使用Thread类创建线程
创建Thread的实例,传入一个函数
创建Thread的实例,传入一个可调用的类实例
派生Thread的子类,并创建子类的实例
%%time
import requests
import threading
import re
base_url = 'https://movie.douban.com/tag'
r =re.compile('<a calss="nbg" .* title=\"?(.*)\"')
def worker(tag): url = base_url +tag params = {'start':'0','type':'T','timeout':'5'} html = requests.get(base_url,params=params).text thread_name = threading.currentThread().getName() print(thread_name,','.join(r.findall(html)),'\n')
threads = []
for tag in ['喜剧','动画','剧情']: thread = threading.Thread(name='Thread-' + tag,target=worker,args=(tag,)) threads.append(thread) thread.start()
for thread in threads: thread.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

串行的爬取策略如下
%%time
import requests
import threading
import re
base_url = 'https://movie.douban.com/tag/'
r =re.compile('<a class="nbg" .* title=\"?(.*)\"')
def worker(tag): url = base_url +tag params = {'start':'0','type':'T','timeout':'5'} html = requests.get(base_url,params=params).text
for tag in ['喜剧','动画','剧情']: worker(tag)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

3.2、Thread类的调用
创建函数的部分为:
thread = threading.Thread(name='Thread-' + tag,target=worker,args=(tag,))
Thread的构造函数包含以下参数
name:定义线程的名字
target:指定线程启动时要执行的函数
args:线程启动时传递给target函数的参数
线程创建之后,调用join方法,然后等待线程结束
thread.join()
join方法会一直阻塞,直到thread线程结束
下面代码中的worker函数,其实就是每一个线程thread中的target,即需要执行的函数
def worker(tag): url = base_url +tag params = {'start':'0','type':'T','timeout':'5'} html = requests.get(base_url,headers=headers,params=params).text thread_name = threading.currentThread().getName() print(thread_name,','.join(r.findall(html)),'\n')
- 1
- 2
- 3
- 4
- 5
- 6
worker函数完成对特定标签下的电影名称的抓取
3.3、线程池的创建
如果每一个任务都需要创建一个新线程。
那么线程的创建和销毁都比较消耗资源,这时候需要创建线程池来解决问题。
from queue import Queue
import inspect
import threading
import re
import time
class ThreadPool(object): def __init__(self,thread_num,worker,queue): assert isinstance(thread_num,int) assert inspect.isfunction(worker) # assert isinstance(queue,Queue) self.queue = queue self.threads = [] self.stop_event = threading.Event() for i in range(0,thread_num): thread = threading.Thread(name='Thread-'+ str(i),target=worker,args=(self,queue,self.stop_event, )) self.threads.append(thread) for thread in self.threads: thread.start() def join(self,wait_until_all_task_done=True): # 等到所有任务完成 if wait_until_all_task_done: self.queue.join() # 设置线程结束 self.stop_event.set() for thread in self.threads: thread.join()
def worker(queue,stop_event): thread_name = threading.currentThread().getName() while not stop_event.is_set(): try: task_id = queue.get(timeout = 1) # 阻塞1秒,防止永久阻塞 print(thread_name,task_id) queue.task_done() except Exception as e : print(e)
queue = Queue()
pool = ThreadPool(2,worker,queue)
for tag in range(1,5): queue.put(tag)
pool.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105324084

- 点赞
- 收藏
- 关注作者
评论(0)