快速入门网络爬虫系列 Chapter09 | JSON数据处理

【摘要】
Chapter09 | JSON数据处理
一、JSON1、获取JSON响应2、解析JSON2.1、解码JSON的功能2.2、从dict中还原为JSON对象
二、API1、第一种2、第二种3、代码实现4、测试
一、JSON
JSON是指JavaScript对象表示法(JavaScript Object Notation):
独立于语言和平台...
一、JSON
JSON是指JavaScript对象表示法(JavaScript Object Notation):
- 独立于语言和平台
- 与XML类似,存储和交换文本信息
- 与XML语言更快、更易解析
JSON的主要表达形式:
- 单个JSON对象,书写格式为{string:value,string:value}
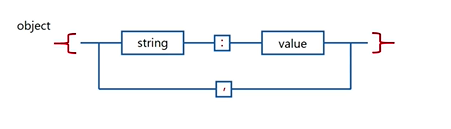
1、获取JSON响应
通过网络库requests,网络爬虫获取响应,并使用JSON格式展示数据
import requests
import urllib
url = 'http://httpbin.org/get'
response = requests.get(url,timeout = 5)
print(response.text)
- 1
- 2
- 3
- 4
- 5
- 6

2、解析JSON
2.1、解码JSON的功能
Python的json库可以提供编码,解码JSON的功能
json库的主要函数有:
- json.loads():JSON字符串转换成Python
- json.load():文件中JSON字符串转换为Python
- json.dumps():Python对象序列化为JSON对象
- json.dump():Python对象序列化为JSON对象,并写入文件
把网络爬虫获取的响应转换成Python对象:
import json
json_data = json.loads(response.text)
print(type(json_data))
print(json_data)
- 1
- 2
- 3
- 4

import requests
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://api.github.com/events')
data = page.json()
print(type(data))
print(type(data[0]))
print(data[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9


2.2、从dict中还原为JSON对象
Json库还可以从dict中还原为JSON对象,在Python中为字符串类型
back_json = json.dumps(json_data)
print(type(back_json))
print(back_json)
- 1
- 2
- 3

二、API
应用编程接口(Application Programming Interface,API)
- API不同的应用提供方便友好的接口
- 开发者用不同的语言结构编写程序,通过API获取数据,实现不同程序间的信息共享
API在网络爬虫中的使用场景:
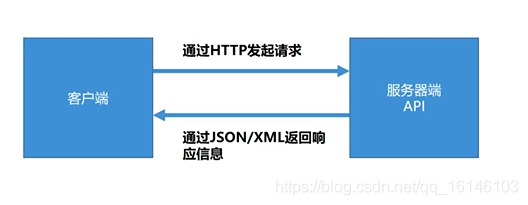
API并不随处可见,但可以请求接收请求,并向客户端返回响应的信息
与网站不同的是,API必须:
- 拥有严谨的语言规则,标准的规范来产生数据
- 使用XML或者JSON格式来展示数据,而不是HTML表示
下面以新浪微博为例:
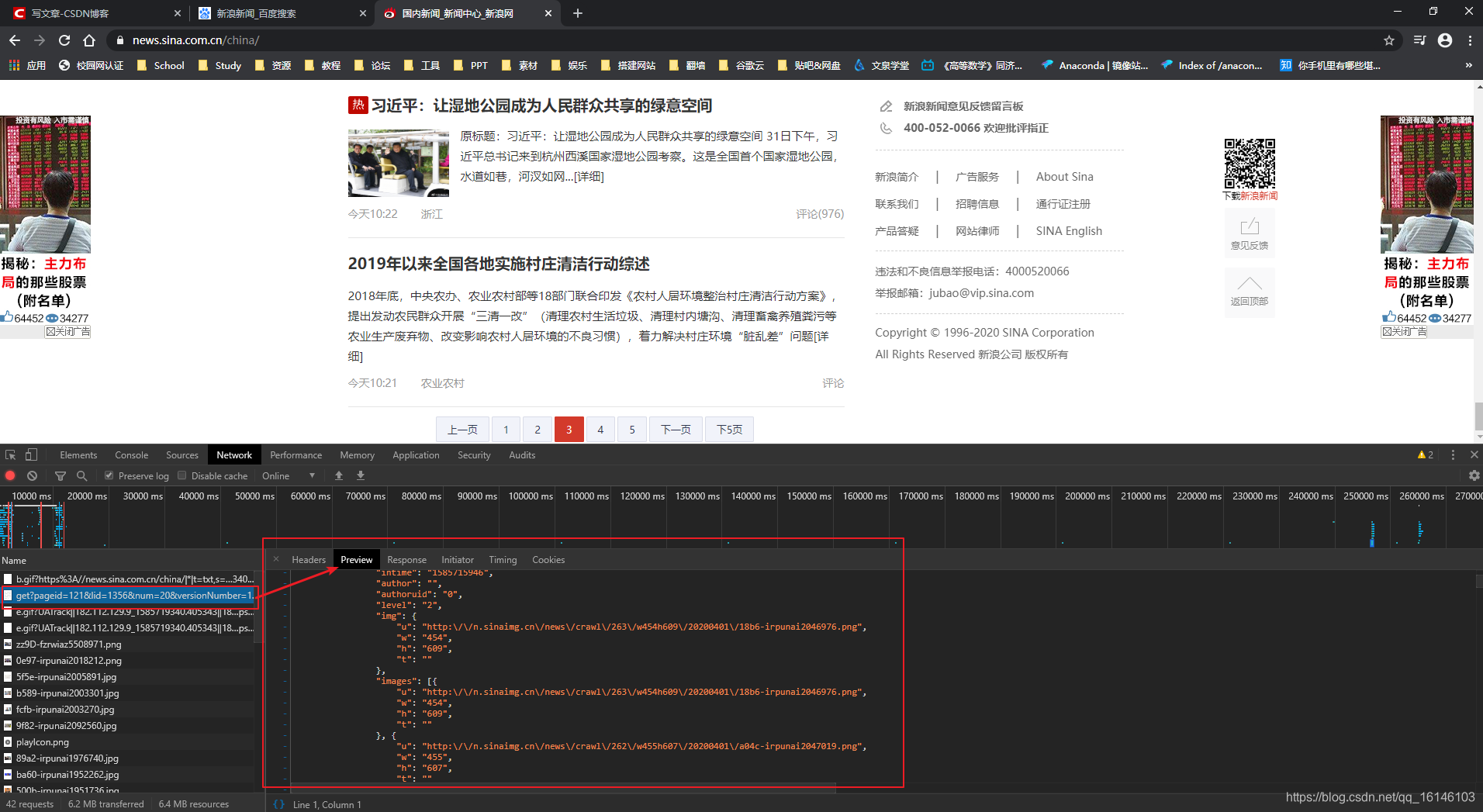
由上图我们可以看到数据,但是这些数据不是我们想要看到的,这是因为我们并没有转码。
下面我们通过两种方式打开来验证下内容:
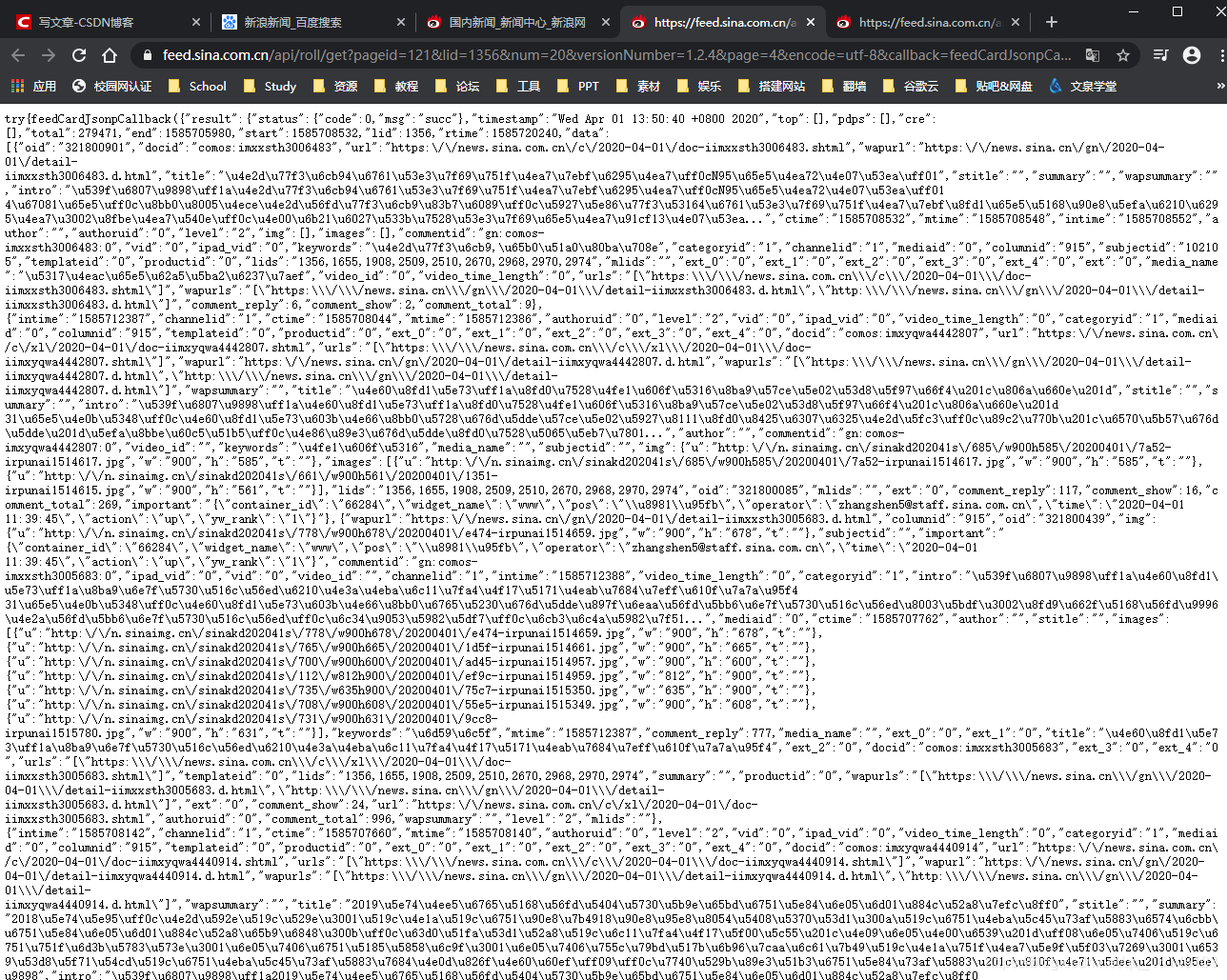
1、第一种
直接点击get
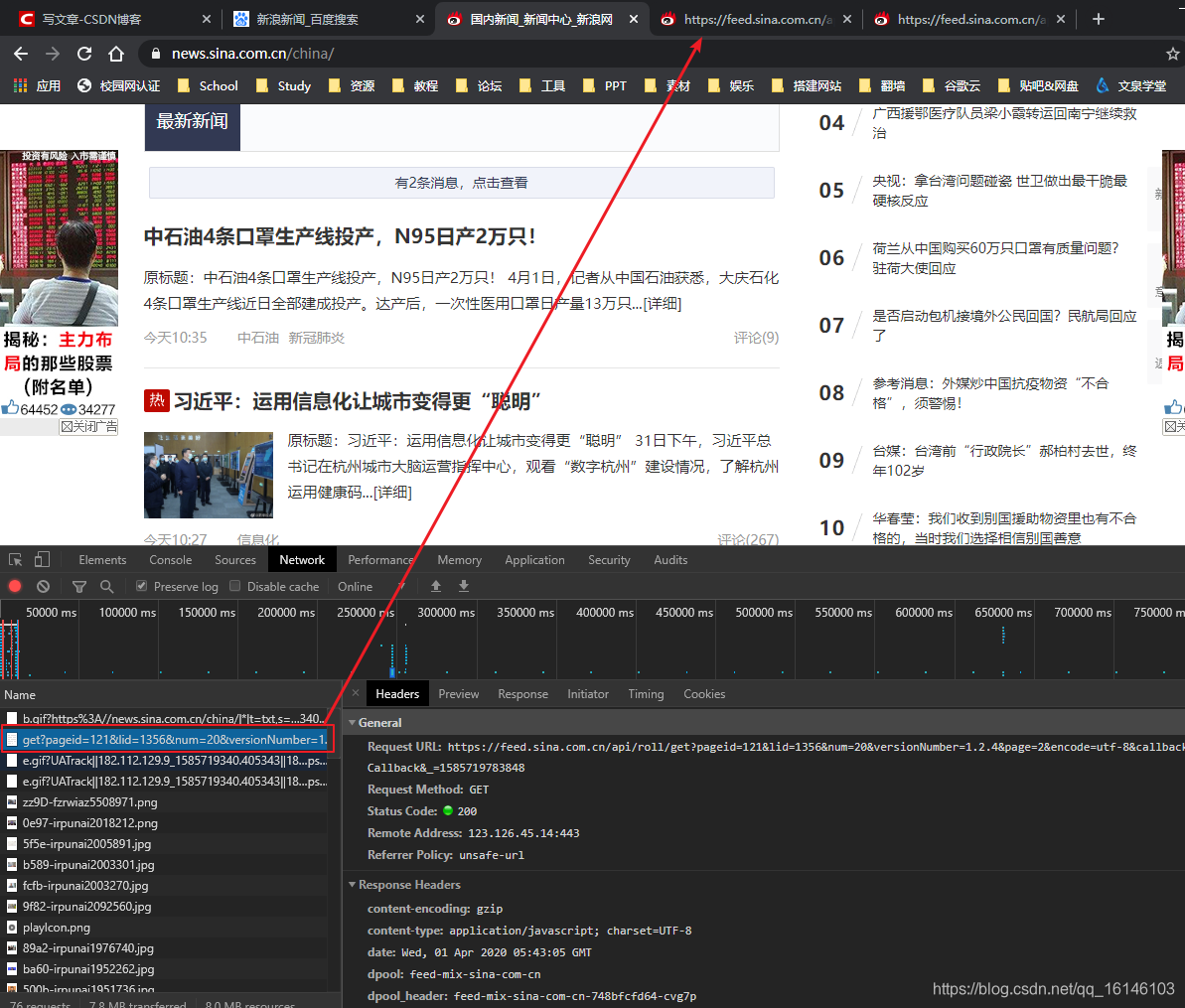
结果如下:
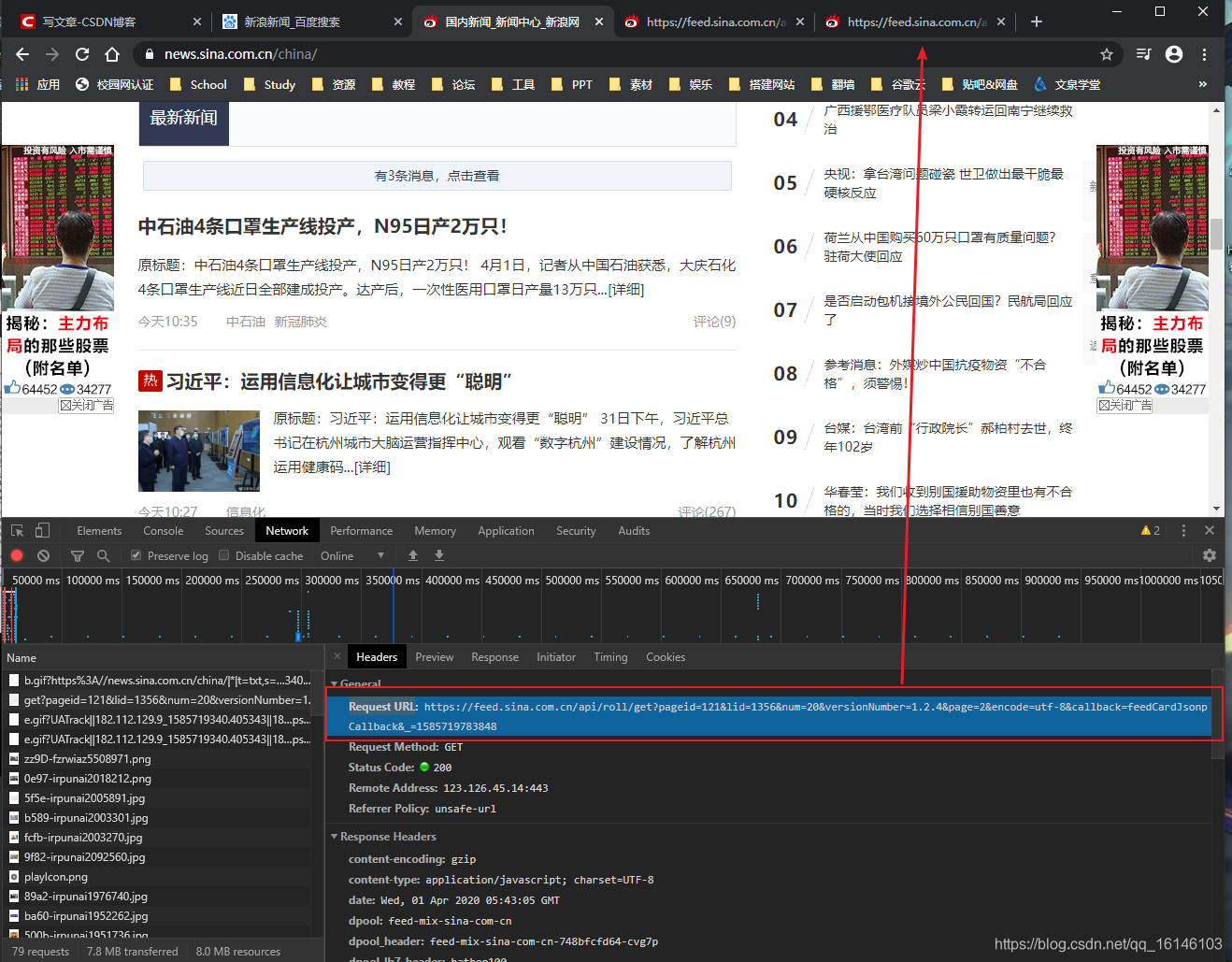
2、第二种
复制Request URL的链接打开
结果如下:
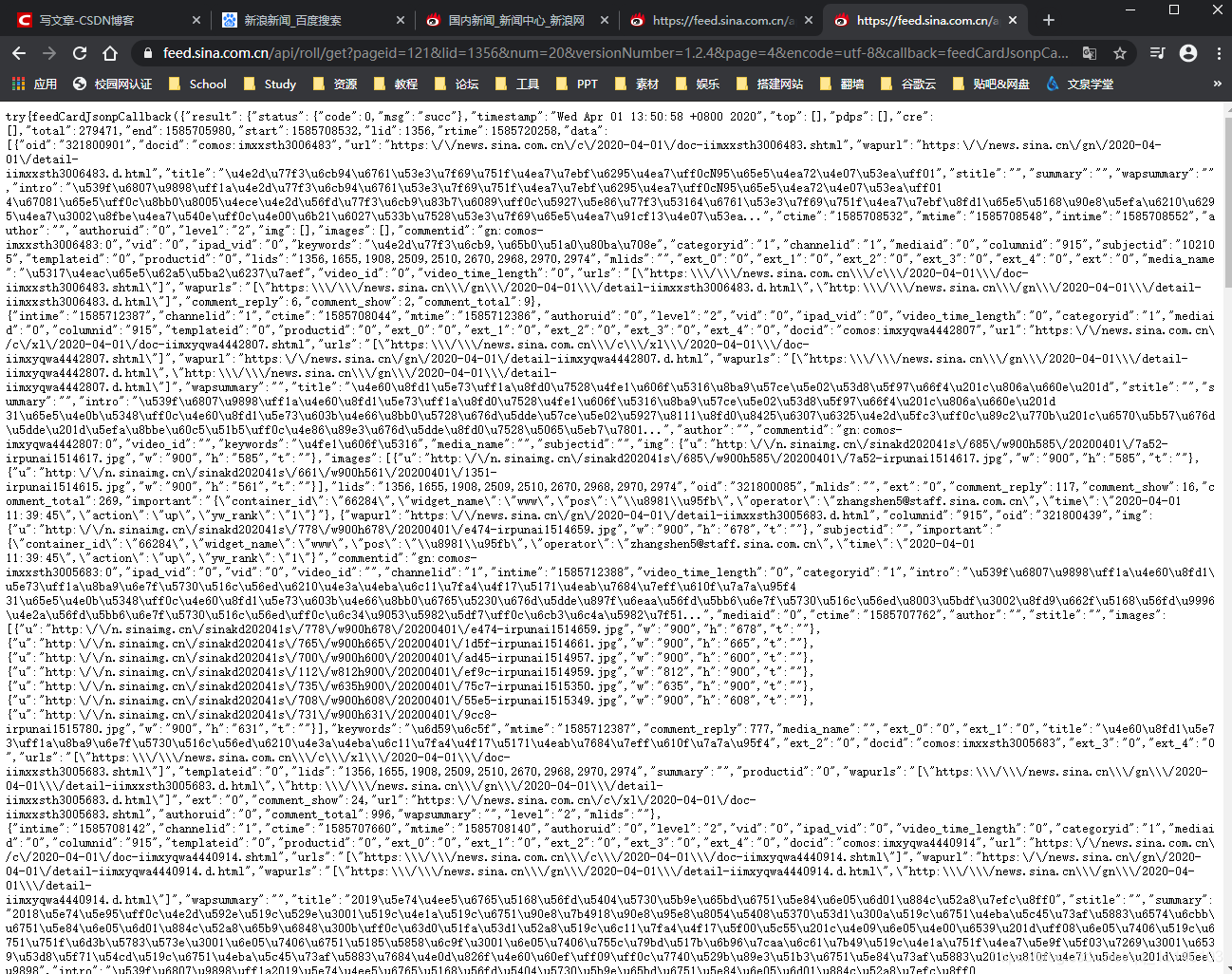
经过对比,我们发现结果是一样的。
3、代码实现
下面在代码实现下:
import requests
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8&callback=feedCardJsonpCallback&_=1585719783848')
print(page.content)
- 1
- 2
- 3
- 4
- 5
- 6

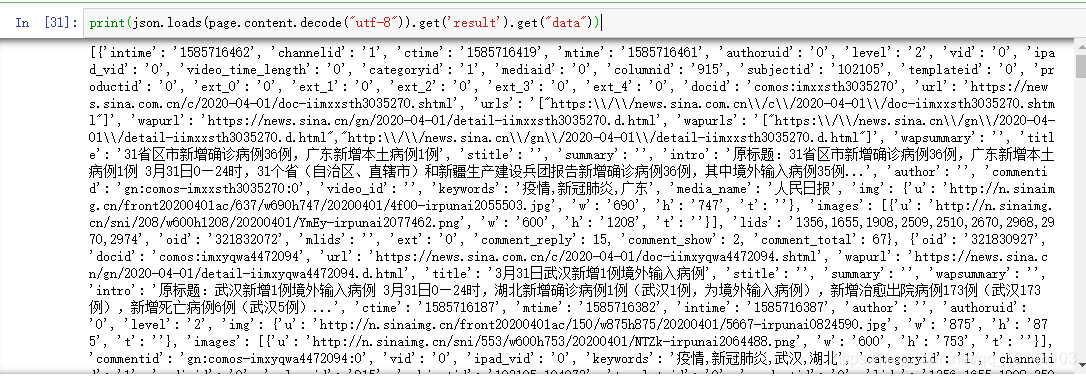
上述代码遍获取到了所需要解析的文件,下面就需要进行解析了:
import requests
import json
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8')
print((json.loads(page.content.decode("utf-8"))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7

这样就转换成dict类型的数据,供我们提取
4、测试
取出网址:
import requests
import json
from bs4 import BeautifulSoup as bs
s=requests.session()
s.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
page=s.get('https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8')
news = json.loads(page.content.decode("utf-8")).get('result').get("data")
for new in news: print(new.get("url"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105240501

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)