快速入门网络爬虫系列 Chapter11 | 将数据存储成文件

上一篇我们学习了两种最常用的方式:用
BeautifulSoup从HTML网页中提取,从JSON中提取。数据提取出来以后就要存储。如果我们抓取的是图片等文件,通常我们仍会以文件的形式存储在文件系统中;如果我们抓取的是结构化的数据,通常我们会存储在数据库或CSV文件中。本篇博文讲解的是不同的存储方式。
通常,如果我们抓取的是图片、音频、视频、文档等内容,那么我们会把东西保存成文件。
import requests
image_url = 'http://httpbin.org/image/png'
file_path = 'test.png'
response = requests.get(image_url,timeout = 5)
with open(file_path,'wb') as f: f.write(response.content)
from IPython.display import Image,display
display(Image(filename = file_path))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

可以看到,我们下载了图片,并正确读取了出来。需要注意的是,我们获取响应内容时,采用的是response.content,而不是response.text。这是因为response.text是响应的unicode表示,response.content响应的字节数组。因为图片是二进制的,所以此处要用response.content。这种方法除了可以下载图片,还可以下载音视频文件,以及文档
下载图片时,我们还可以直接把响应内容存到PIL.Image中:
from PIL import Image
from io import BytesIO
from IPython.display import display
image = Image.open(BytesIO(response.content))
print(image.height,image.width)
image.save(file_path)
display(image)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

因为PIL.Image包含了很多操作图片的方法,如resize,rotate,thumbnail等,方便用户在保存之前做一些预处理。
如果需要抓取的数据量不大,通常我们可以把数据存成CSV。这样如果你用pandas载入数据的时候就会非常方便。Python中有一个原生库csv,是专门用来读写CSV文件的。
如何用csv创建一个CSV文件:
import csv
file_path = 'test.csv'
with open(file_path,'w')as f: writer = csv.writer(f,delimiter = '\t',quotechar = '"',quoting = csv.QUOTE_ALL) writer.writerow(['C1','C2','C3']) # 写一行,这一行同时也是标题 data = [(1,2,3),(4,5,6)] writer.writerows(data) # 写多行 with open(file_path,'r')as f: reader = csv.reader(f,delimiter = '\t',quotechar = '"',quoting = csv.QUOTE_ALL) for row in reader: print('\t'.join(row))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
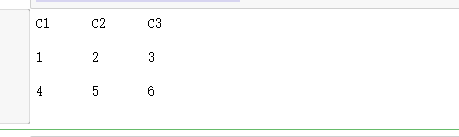
上面的代码首先创建一个writer,以'\t'为列的分隔符,给所有的数据都加上双引号,这是为了防止数据中也包含'\t'。然会写了一行标题,最后写了两行数据。接着又创建了一个reader正确地读出了CSV文件。
csv.writer在写入文件时要将unicode字符串进行编码,因为Python地默认编码是ascii,所以如果要写入的内容包含非ASCII字符时,就会出现UnicodeEncodeError。此时可以在调用writerow之前先将unicode字符串编码成UTF-8字符串,或者直接使用unicodecsv写入unicode字符串:
import unicodecsv
file_path = 'test.csv'
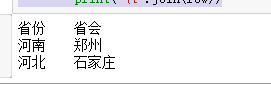
with open(file_path,'wb')as f: writer = unicodecsv.writer(f,delimiter = '\t',quotechar = '"',quoting = csv.QUOTE_ALL) writer.writerow(['省份','省会']) # 写一行,标题 data = [("河南","郑州"),("河北","石家庄")] writer.writerows(data) # 写多行 with open(file_path,'rb')as f: reader = unicodecsv.reader(f,delimiter = '\t',quotechar = '"',quoting = csv.QUOTE_ALL) for row in reader: print('\t'.join(row))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105269123

- 点赞
- 收藏
- 关注作者
评论(0)