HBase快速入门系列(8) | 一文教你HBase与Hive如何集成

大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是HBase与Hive的集成。
标注:
此处为反爬虫标记:读者可自行忽略
- 1
- 2

原文地址:https://buwenbuhuo.blog.csdn.net/
一. 两者对比
1. Hive
- (1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
- (2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
- (3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
2. HBase
- (1) 数据库
是一种面向列存储的非关系型数据库。
- (2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
- (3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
- (4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
二. HBase与Hive集成使用
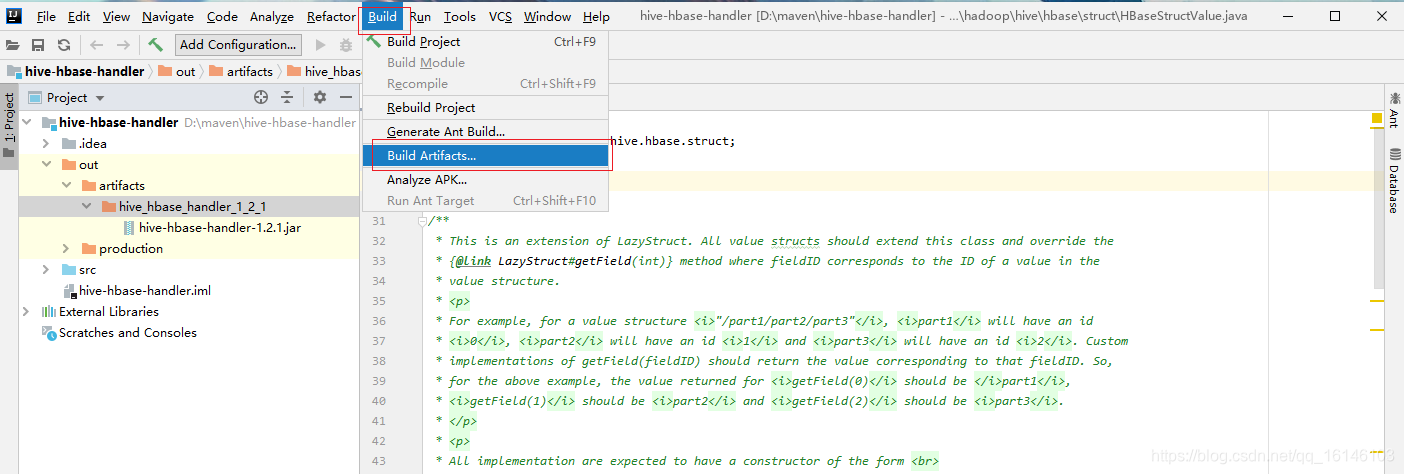
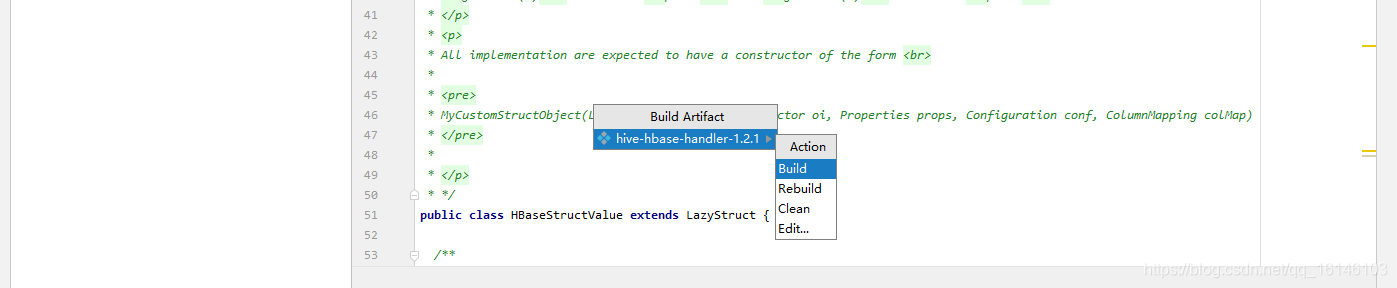
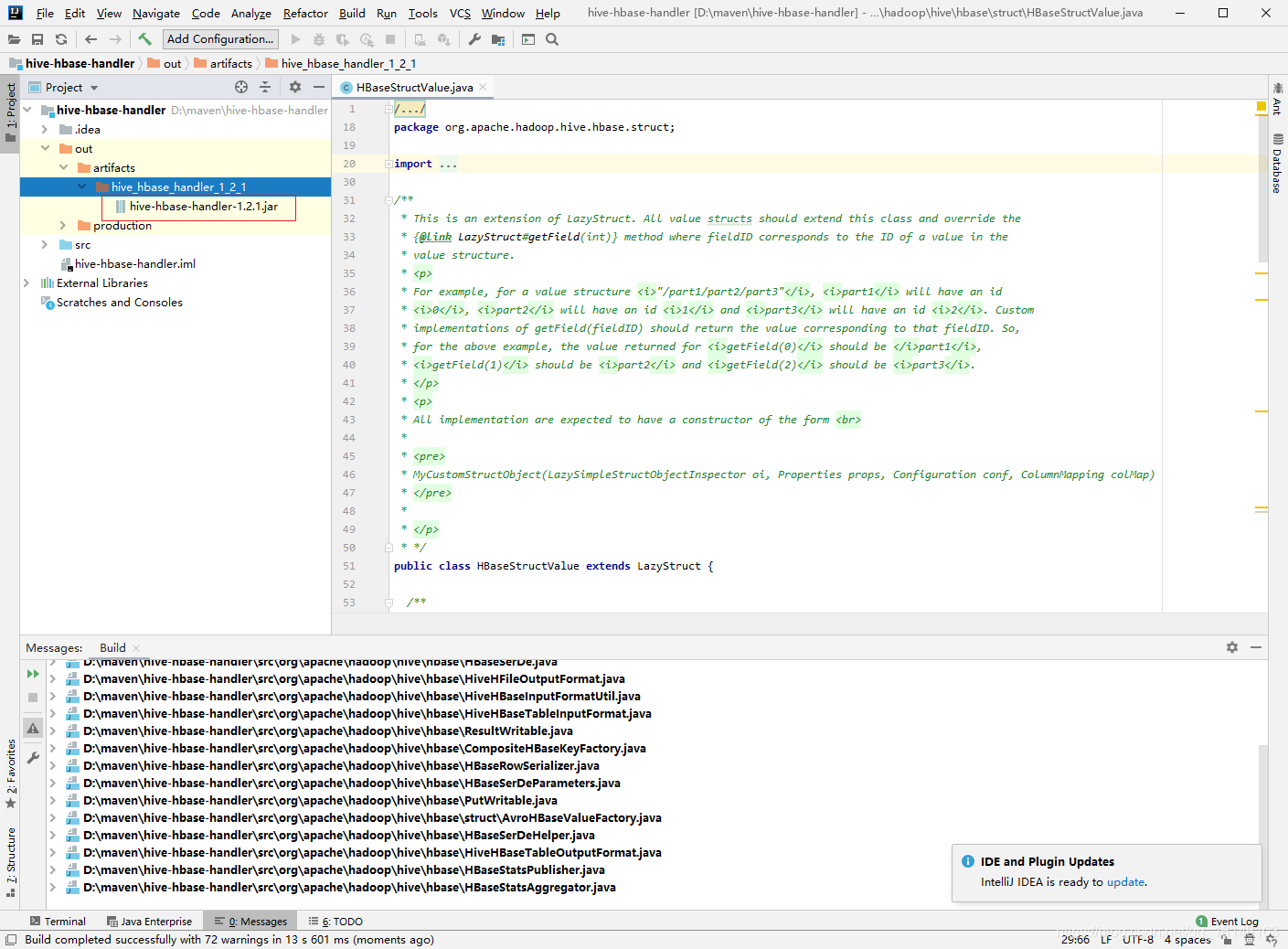
1. 编译jar包
由于HBase与Hive的集成的这两个版本中无法兼容。所以,我们重新编译:hive-hbase-handler-1.2.2.jar!!好气!!
步骤:
- 1. 新建一个Java项目名称为
hive-hbase-handler

- 2. 找到源码包所需要编译的部分,copy到项目内
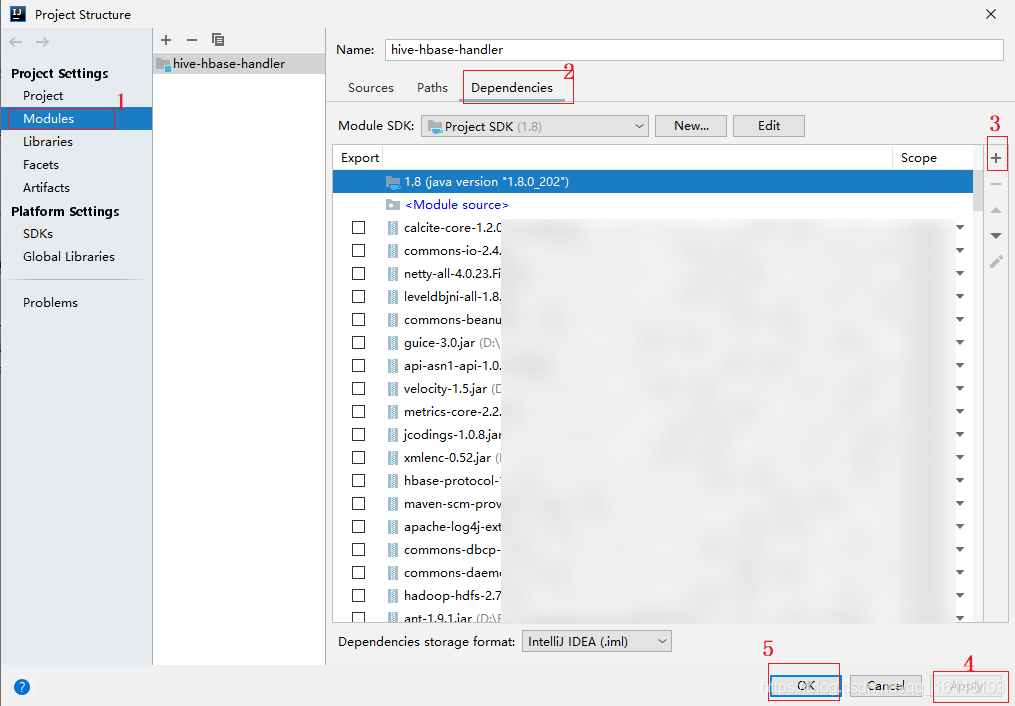
- 3. 添加依赖(此包为hbase和hive的lib包里的所有文档的整合,如有需要可私聊博主)
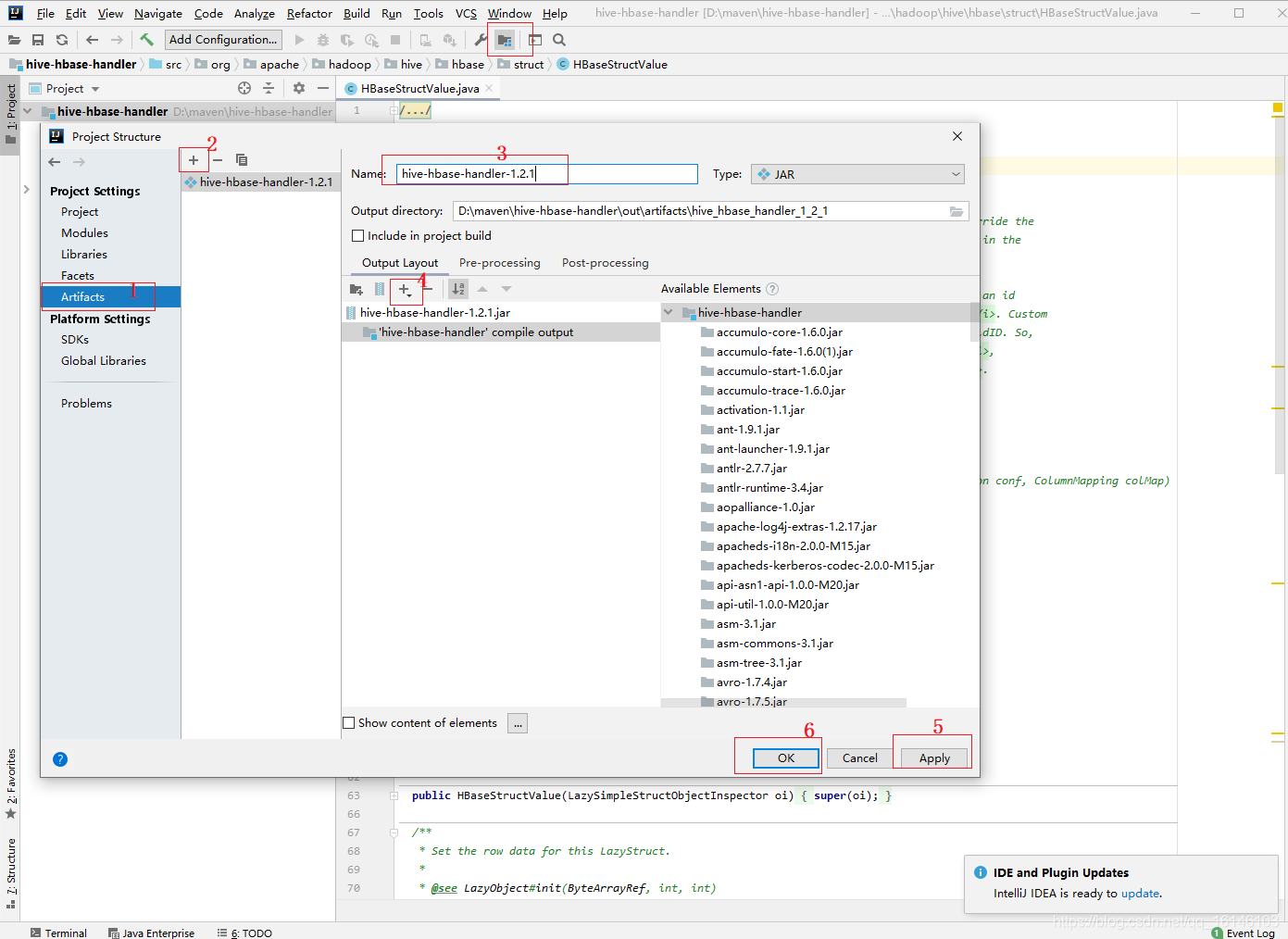
- 4. 打包jar包
- 5.替换原Jar包

2. 环境准备
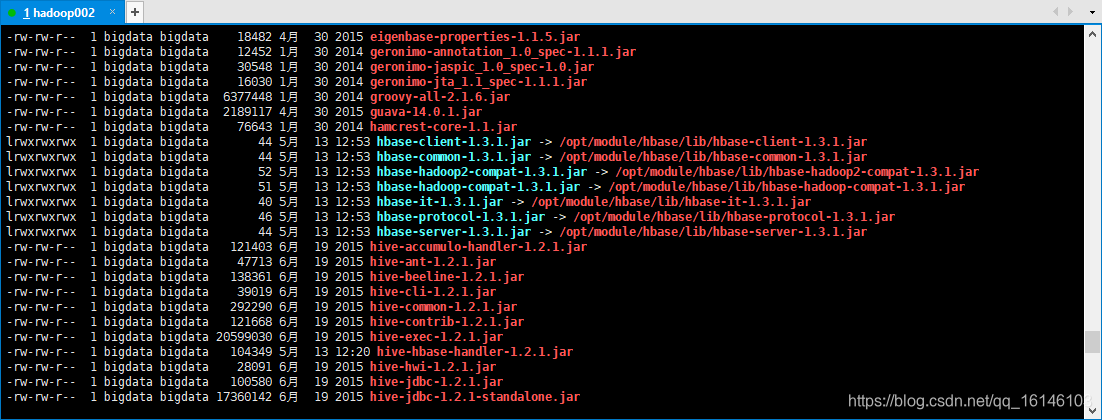
- 1.因为我们后续可能会在操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
[bigdata@hadoop002 module]$ sudo vim /etc/profile
export HBASE_HOME=/opt/module/hbase
export HIVE_HOME=/opt/module/hive
// 立即生效
[bigdata@hadoop002 module]$ source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 软连接
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar $HIVE_HOME/lib/hbase-common-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbase-server-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar $HIVE_HOME/lib/hbase-client-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-it-1.3.1.jar $HIVE_HOME/lib/hbase-it-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar
[bigdata@hadoop002 lib]$ ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 2. 在hive-site.xml中修改zookeeper的属性
[bigdata@hadoop002 conf]$ sudo vim hive-site.xml
// 添加如下内容
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop002,hadoop003,hadoop004</value>
<description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3. 测试案例1
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
- 前提准备
// 启动所需要的服务
[bigdata@hadoop002 module]$ start-dfs.sh
[bigdata@hadoop003 module]$ start-yarn.sh
[bigdata@hadoop002 zookeeper-3.4.10]$ bin/start-allzk.sh
[bigdata@hadoop002 hbase]$ bin/start-hbase.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1. 在Hive中创建表同时关联HBase
// 需要另开窗口
[bigdata@hadoop002 hive]$ bin/hive
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
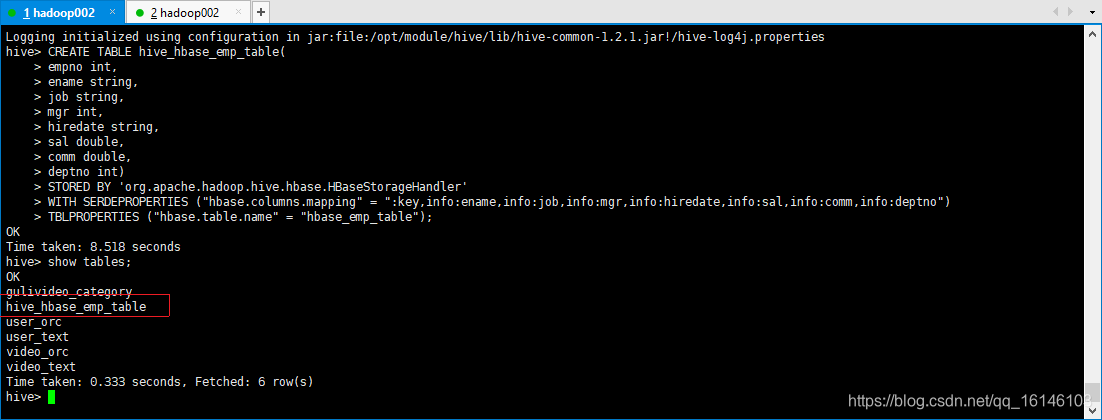
这是需要查看下Hbase里是否有表建立
[bigdata@hadoop002 hbase]$ bin/hbase shell
// 查看表格
hbase(main):001:0> list
- 1
- 2
- 3
- 4
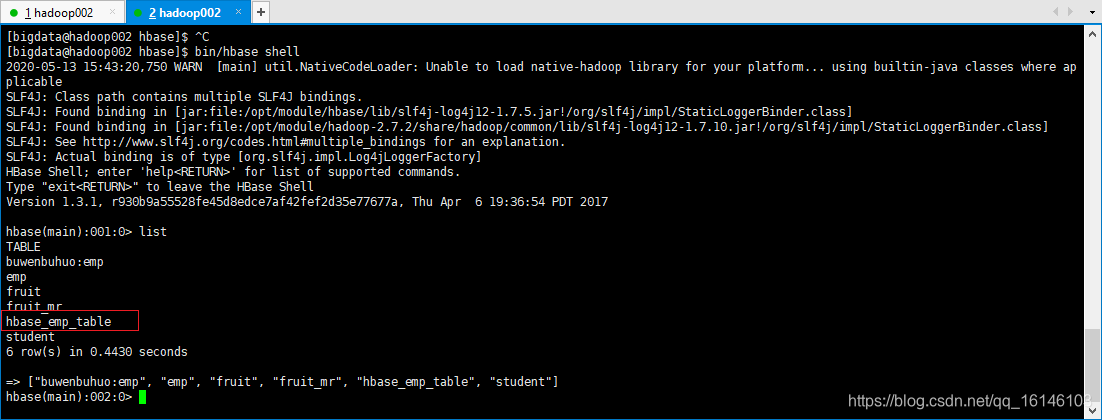
- 2. 在Hive中创建临时中间表,用于load文件中的数据
提示:不能将数据直接load进Hive所关联HBase的那张表中
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 3. 向Hive中间表中load数据
上传数据
hive> hive> load data local inpath '/opt/module/datas/emp.txt' into table emp;
- 1

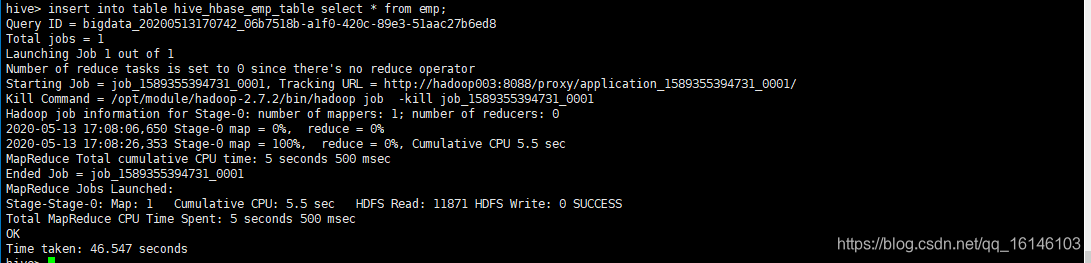
- 4. 通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
- 1
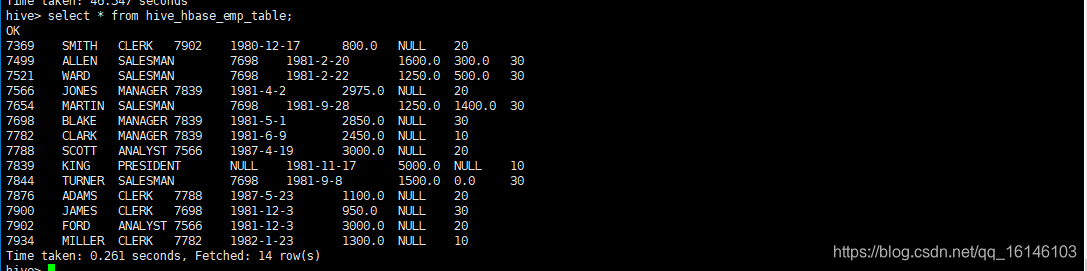
- 5. 查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;
- 1
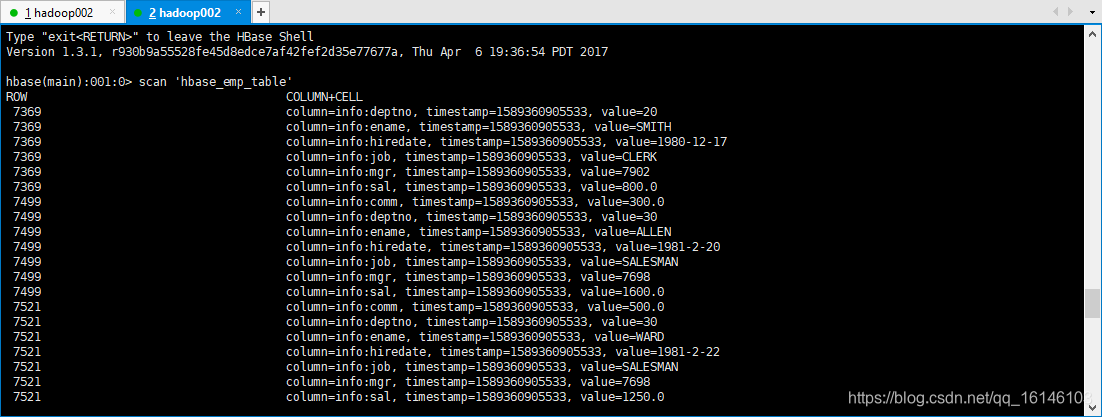
HBase:
hbase> scan ‘hbase_emp_table’
- 1
4. 测试案例2
目标:在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。(前提要先完成案例1)
- 1. 在Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
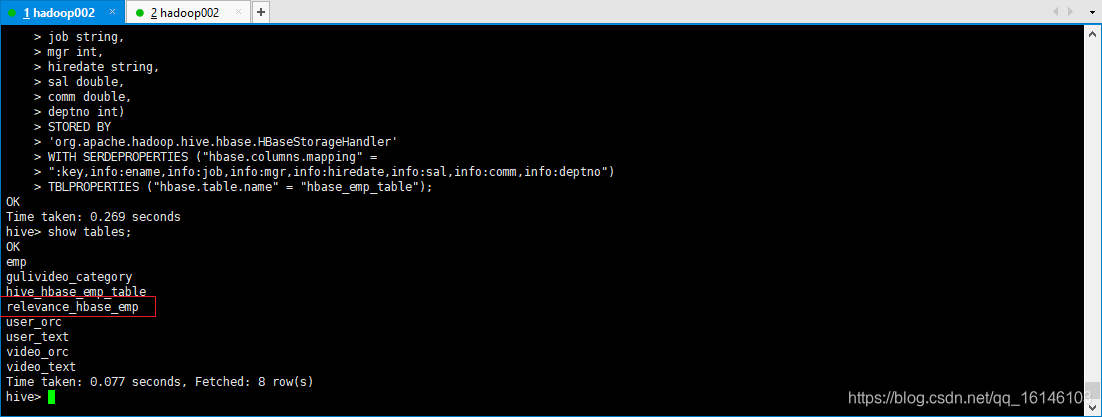
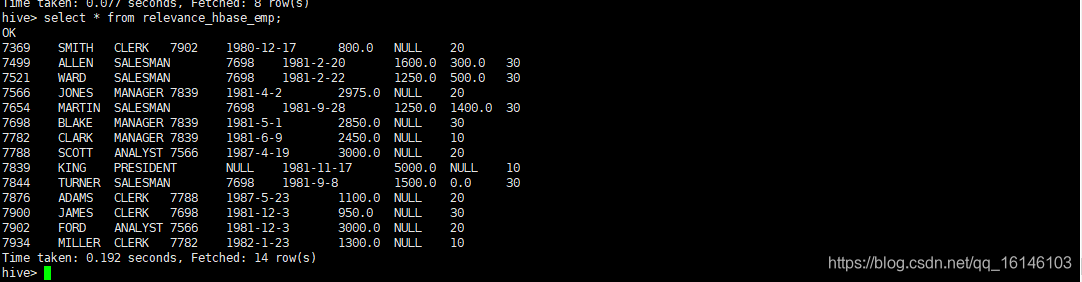
- 2. 关联后就可以使用Hive函数进行一些分析操作了
// 可快速查看内容,第一次比较慢
hive (default)> select * from relevance_hbase_emp;
- 1
- 2
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/106093865

- 点赞
- 收藏
- 关注作者
评论(0)