MapReduce快速入门系列(12) | MapReduce之OutputFormat

前面我们讲解了MapTask,ReduceTask和MapReduce运行机制。,那么这篇文章博主继续为大家讲解OutputFormat数据输出。
一. OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面介绍几种常见的OutputFormat实现类。
1.1 文本输出TextOutputFormat
默认的输出格式是TextOutFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toSTRING()方法把它们转换为字符串。
1.2 SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
1.3 自定义OutputFormat
根据用户需求,自定义实现输出。
二. 自定义OutputFormat的使用场景和步骤
2.1 使用场景
为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
eg:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。
2.2 自定义OutputFormat步骤
1、自定义一个类继承FileOutputFormat。
2、改写RecordWriter,具体改写输出数据的方法write()。
三. 举例操作
3.1 需求
过滤输入的log日志,包含buwenbuhuo的网站输出到d:/buwenbuhuo.log,不包含buwenbuhuo的网站输出到d:/other.log。

3.2 需求分析
- 需求: 过滤输入的log日志,包含buwenbuhuo的网站输出到
d:/buwenbuhuo.log,不包含buwenbuhuo的网站输出到d:/other.log。


3.3 编写代码
- 1. 自定义一个MyOutputFormat类
package com.buwenbuhuo.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-04-25 16:37
* com.buwenbuhuo.outputformat - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class MyOutputFormat extends FileOutputFormat<LongWritable, Text> { @Override public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { MyRecordWriter myRecordWriter = new MyRecordWriter(); myRecordWriter.initialize(job); return myRecordWriter; }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 2. 编写MyRecordWriter类
package com.buwenbuhuo.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-04-25 16:37
* com.buwenbuhuo.outputformat - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class MyRecordWriter extends RecordWriter<LongWritable, Text> { private FSDataOutputStream buwenbuhuo; private FSDataOutputStream other; /** * 初始化方法 * @param job */ public void initialize(TaskAttemptContext job) throws IOException { String outdir = job.getConfiguration().get(FileOutputFormat.OUTDIR); FileSystem fileSystem = FileSystem.get(job.getConfiguration()); buwenbuhuo = fileSystem.create(new Path(outdir + "/buwenbuhuo.log")); other = fileSystem.create(new Path(outdir + "/other.log")); } /** * 将KV写出,每对KV调用一次 * @param key * @param value * @throws IOException * @throws InterruptedException */ @Override public void write(LongWritable key, Text value) throws IOException, InterruptedException { String out = value.toString() + "\n"; if (out.contains("buwenbuhuo")) { buwenbuhuo.write(out.getBytes()); } else { other.write(out.getBytes()); } } /** * 关闭资源 * @param context * @throws IOException * @throws InterruptedException */ @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(buwenbuhuo); IOUtils.closeStream(other); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 3. 编写OutputDriver类
package com.buwenbuhuo.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-04-25 16:37
* com.buwenbuhuo.outputformat - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class OutputDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(new Configuration()); job.setJarByClass(OutputDriver.class); job.setOutputFormatClass(MyOutputFormat.class); FileInputFormat.setInputPaths(job, new Path("d:\\input")); FileOutputFormat.setOutputPath(job, new Path("d:\\output")); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
3.4 运行及结果
- 1. 运行
- 2.结果
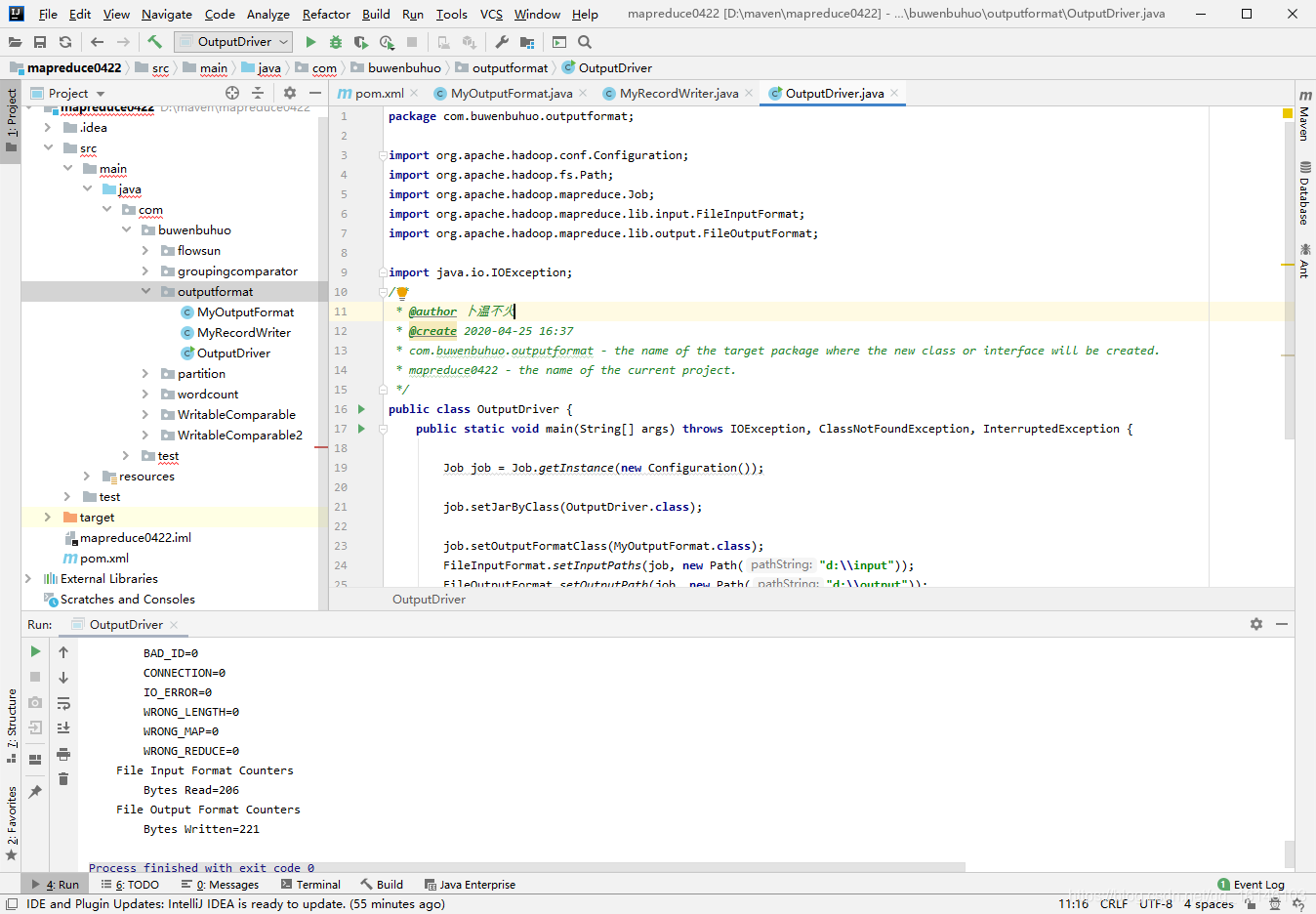
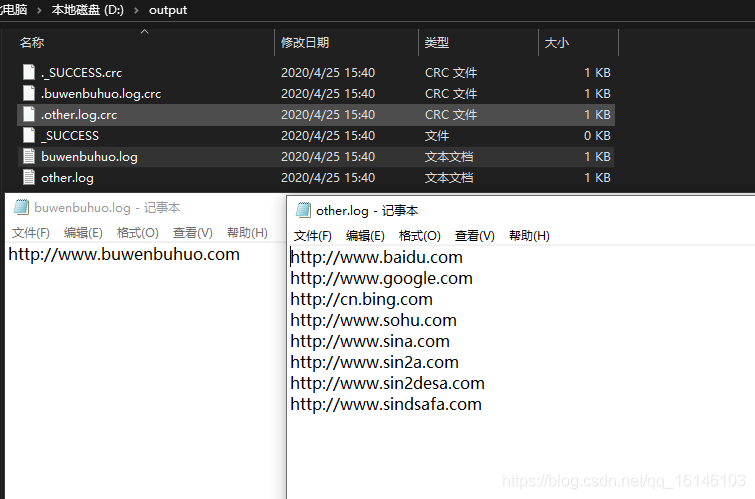
到了这里说明我们的自定义outputFormat算是成功了。那本期的分享到这里也就该结束了,小伙伴们有什么疑惑或好的建议可以在评论区留言或者私信博主都是可以的。博主有时间会一一回复大家,另外,受益的小伙伴们记得关注博主呀(^U^)ノ~YO。
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105750084

- 点赞
- 收藏
- 关注作者
评论(0)