MapReduce快速入门系列(8) | Shuffle之排序(sort)——区内排序

【摘要】
上一篇博文讲了Shuffle排序的相关概念以及全排序的操作,这篇博文继续分享的是排序的另一种操作:区内排序。
目录
一. 需求分析二. 代码实现2.1 增加自定义分区类MyPartitioner22.2 在驱动类中添加分区类
三. 运行及其结果
一. 需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置。
1. ...
上一篇博文讲了Shuffle排序的相关概念以及全排序的操作,这篇博文继续分享的是排序的另一种操作:区内排序。
一. 需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置。
- 1. 把原数据排序后

- 2. 期望数据输出


二. 代码实现
2.1 增加自定义分区类MyPartitioner2
package com.buwenbuhuo.WritableComparable2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author 卜温不火
* @create 2020-04-24 18:14
* com.buwenbuhuo.WritableComparable2 - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class MyPartitioner2 extends Partitioner<com.buwenbuhuo.WritableComparable.FlowBean, Text> { @Override public int getPartition(com.buwenbuhuo.WritableComparable.FlowBean flowBean, Text text, int numPartitions) { switch (text.toString().substring(0, 3)) { case "136": return 0; case "137": return 1; case "138": return 2; case "139": return 3; default: return 4; } }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.2 在驱动类中添加分区类
// 加载自定义分区类
job.setPartitionerClass(ProvincePartitioner.class);
// 设置Reducetask个数
job.setNumReduceTasks(5);
- 1
- 2
- 3
- 4
- 5
- 6
- 此部分的完整代码如下:
package com.buwenbuhuo.WritableComparable2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-04-24 18:19
* com.buwenbuhuo.WritableComparable2 - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class SortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(new Configuration()); job.setJarByClass(com.buwenbuhuo.WritableComparable2.SortDriver.class); job.setMapperClass(com.buwenbuhuo.WritableComparable.SortMapper.class); job.setReducerClass(com.buwenbuhuo.WritableComparable.SortReducer.class); job.setMapOutputKeyClass(com.buwenbuhuo.WritableComparable.FlowBean.class); job.setMapOutputValueClass(Text.class); job.setPartitionerClass(MyPartitioner2.class); job.setNumReduceTasks(5); job.setOutputKeyClass(Text.class); job.setOutputValueClass(com.buwenbuhuo.WritableComparable.FlowBean.class); FileInputFormat.setInputPaths(job, new Path("d:\\output")); FileOutputFormat.setOutputPath(job, new Path("d:\\output2")); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
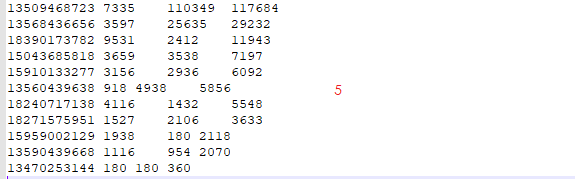
三. 运行及其结果
- 1. 运行
- 2. 结果
- 3. 与设想的对比
可以看到是一样的。






本期的分享就到这里了,小伙伴们有什么疑惑或好的建议可以积极在评论区留言~,博主会持续更新新鲜好玩的技术,喜欢的小伙伴们不要忘了点赞,记得要关注博主呐ヾ(◍°∇°◍)ノ゙。
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105736481

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)