Kafka快速入门系列(4) | 超好用的Kafka和zookeeper群起脚本(建议收藏!)

【摘要】 本篇博主带来的是Kafka和zookeeper群起脚本的创建与使用。
目录
一. Zookeeper1. 一键启动脚本2. 一键关闭脚本
二. Kafka1. 启动2. 关闭
之前介绍过Kafka集群环境的搭建,但是细心的朋友们都发现,Kafka与ZooKeeper一样,都需要在每台节点上执行对应的开启/关闭脚本,十分的不方便。现在...
本篇博主带来的是Kafka和zookeeper群起脚本的创建与使用。

之前介绍过Kafka集群环境的搭建,但是细心的朋友们都发现,Kafka与ZooKeeper一样,都需要在每台节点上执行对应的开启/关闭脚本,十分的不方便。现在我们学习只用到了3台节点,如果以后到了企业,节点多了我们肯定就不能这么干了,那有什么简便的方法么?
既然博主都这么说了,大家是不是可以推断出我们可以写一个Kafka的集群启动/关闭脚本呢?
结果是肯定的,当然了除了Kafka的集群启动/关闭脚本,Zookeeper博主也会在此分享给大家。
一. Zookeeper
1. 一键启动脚本
- 1. 创建并使其变成可执行性文件
[bigdata@hadoop002 zookeeper-3.4.10]$ cd bin/
[bigdata@hadoop002 bin]$ vim start-allzk.sh
// 输入以下内容
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
echo "========== $i =========="
ssh $i 'source /etc/profile;/opt/module/zookeeper-3.4.10/bin/zkServer.sh start'
echo $i " zookeeper is starting"
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
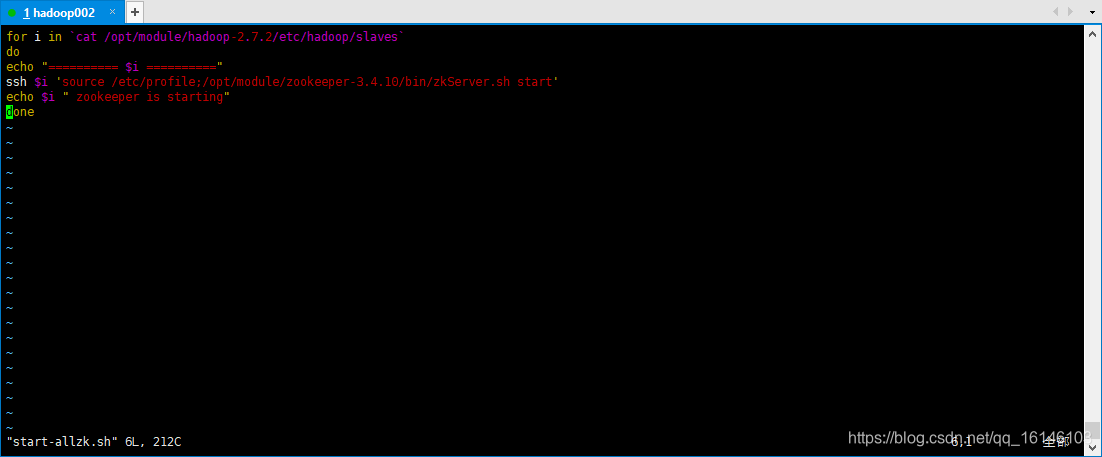
创建完成后,别忘了让其变成可执行性文件
[bigdata@hadoop002 bin]$ chmod u+x start-allzk.sh
- 1
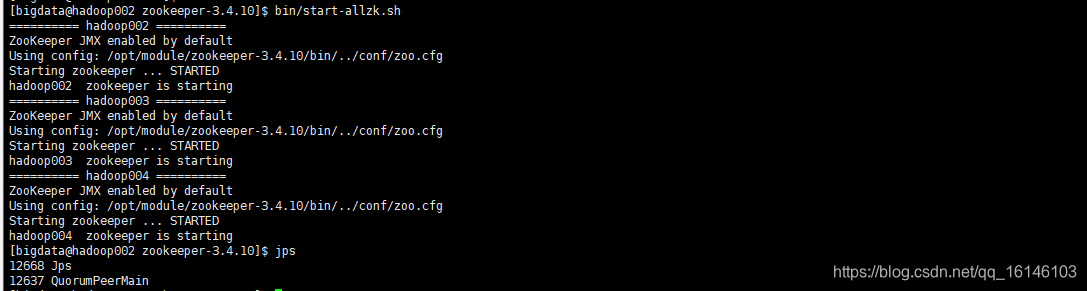
- 2. 测试启动效果
2. 一键关闭脚本
- 1. 创建并使其变成可执行性文件
[bigdata@hadoop002 zookeeper-3.4.10]$ cd bin/
[bigdata@hadoop002 bin]$ vim stop-allzk.sh
// 输入以下内容
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
echo "========== $i =========="
ssh $i 'source /etc/profile;/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop'
echo $i " zookeeper is stopping"
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
创建完成后,别忘了让其变成可执行性文件
[bigdata@hadoop002 bin]$ chmod u+x stop-allzk.sh
- 1
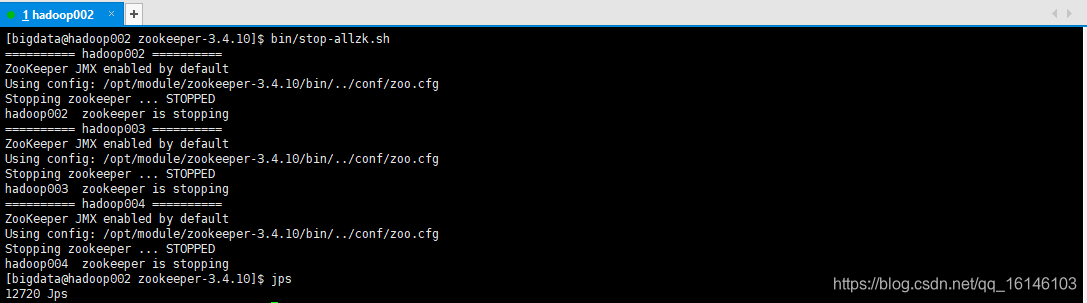
- 2. 测试启动效果
二. Kafka
1. 启动
- 1. 创建并使其变成可执行性文件
[bigdata@hadoop002 kafka]$ cd bin/
[bigdata@hadoop002 bin]$ vim start-kafkaall.sh
// 输入以下内容
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
echo "========== $i =========="
ssh $i 'source /etc/profile && /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties'
echo "INFO:starting kafka server on "$i
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
创建完成后,别忘了让其变成可执行性文件
[bigdata@hadoop002 bin]$ chmod u+x start-kafkaall.sh
- 1
- 2. 测试启动效果

2. 关闭
- 1. 创建并使其变成可执行性文件
[bigdata@hadoop002 kafka]$ cd bin/
[bigdata@hadoop002 bin]$ vim stop-kafkaall.sh
// 输入以下内容
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
echo "========== $i =========="
ssh $i "source /etc/profile;jps |grep kafka |cut -c 1-6 |xargs kill -s 9"
echo $i " kafka is stopping"
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
创建完成后,别忘了让其变成可执行性文件
[bigdata@hadoop002 bin]$ chmod u+x stop-kafkaall.sh
- 1
- 2. 测试启动效果

大家如果配置了环境变量的话,直接在任意目录下都可以执行这两个脚本,是不是很方便呢!
本次的分享就到这里了,

看 完 就 赞 , 养 成 习 惯 ! ! ! \color{#FF0000}{看完就赞,养成习惯!!!} 看完就赞,养成习惯!!!^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/105938229

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)