Spark Core快速入门系列(11) | 文件中数据的读取和保存

大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是文件中数据的读取和保存


从文件中读取数据是创建 RDD 的一种方式.
把数据保存的文件中的操作是一种 Action.
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:Text文件、Json文件、csv文件、Sequence文件以及Object文件;
文件系统分为:本地文件系统、HDFS、Hbase 以及 数据库。
平时用的比较多的就是: 从 HDFS 读取和保存 Text 文件.
一. 读写 Text 文件
// 读取文件
scala> val rdd1 = sc.textFile("hdfs://hadoop002:9000//user/hive/warehouse/emp/emp.txt")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://hadoop002:9000//user/hive/warehouse/emp/emp.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> val rdd2 = rdd1.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ +_)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:26
// 保存数据到hdfs
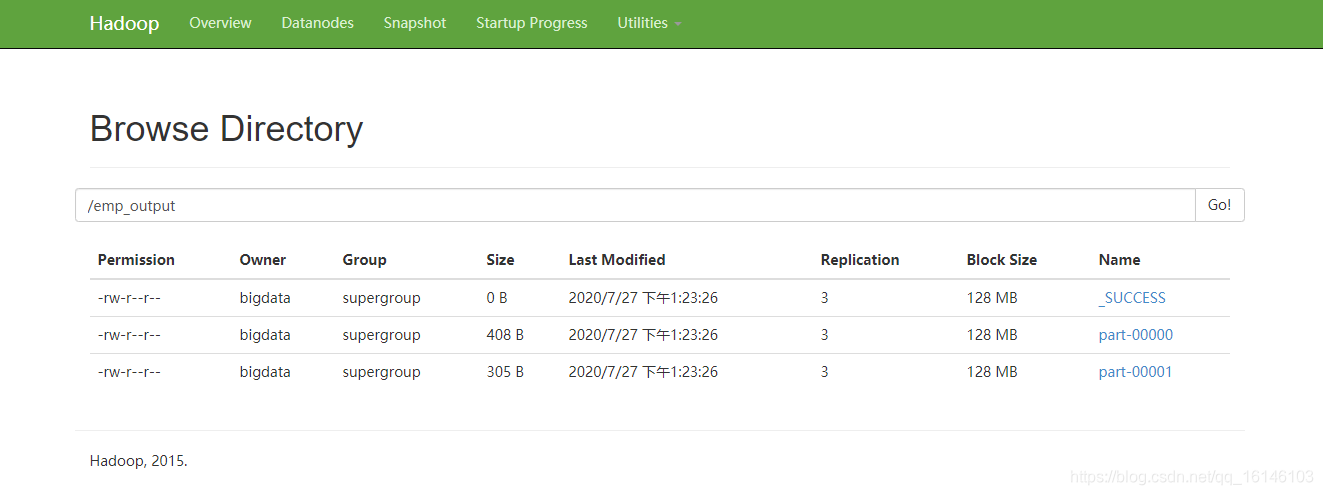
scala> rdd2.saveAsTextFile("hdfs://hadoop002:9000/emp_output")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
二. 读取 Json 文件
如果 JSON 文件中每一行就是一个 JSON 记录,那么可以通过将 JSON 文件当做文本文件来读取,然后利用相关的 JSON 库对每一条数据进行 JSON 解析。
注意:使用 RDD 读取 JSON 文件处理很复杂,同时 SparkSQL 集成了很好的处理 JSON 文件的方式,所以实际应用中多是采用SparkSQL处理JSON文件。
// 读取 json 数据的文件, 每行是一个 json 对象
scala> val rdd1 = sc.textFile("/opt/module/spark/examples/src/main/resources/people.json")
rdd1: org.apache.spark.rdd.RDD[String] = /opt/module/spark-local/examples/src/main/resources/people.json MapPartitionsRDD[11] at textFile at <console>:24
// 导入 scala 提供的可以解析 json 的工具类
scala> import scala.util.parsing.json.JSON
import scala.util.parsing.json.JSON
// 使用 map 来解析 Json, 需要传入 JSON.parseFull
scala> val rdd2 = rdd1.map(JSON.parseFull)
rdd2: org.apache.spark.rdd.RDD[Option[Any]] = MapPartitionsRDD[12] at map at <console>:27
// 解析到的结果其实就是 Option 组成的数组, Option 存储的就是 Map 对象
scala> rdd2.collect
res2: Array[Option[Any]] = Array(Some(Map(name -> Michael)), Some(Map(name -> Andy, age -> 30.0)), Some(Map(name -> Justin, age -> 19.0)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
三. 读写 SequenceFile 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(Flat File)。
Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用 sequenceFile keyClass, valueClass。
注意:SequenceFile 文件只针对 PairRDD
- 1. 保存一个 SequenceFile 文件
scala> val rdd1 = sc.parallelize(Array(("a", 1),("b", 2),("c", 3)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[13] at parallelize at <console>:26
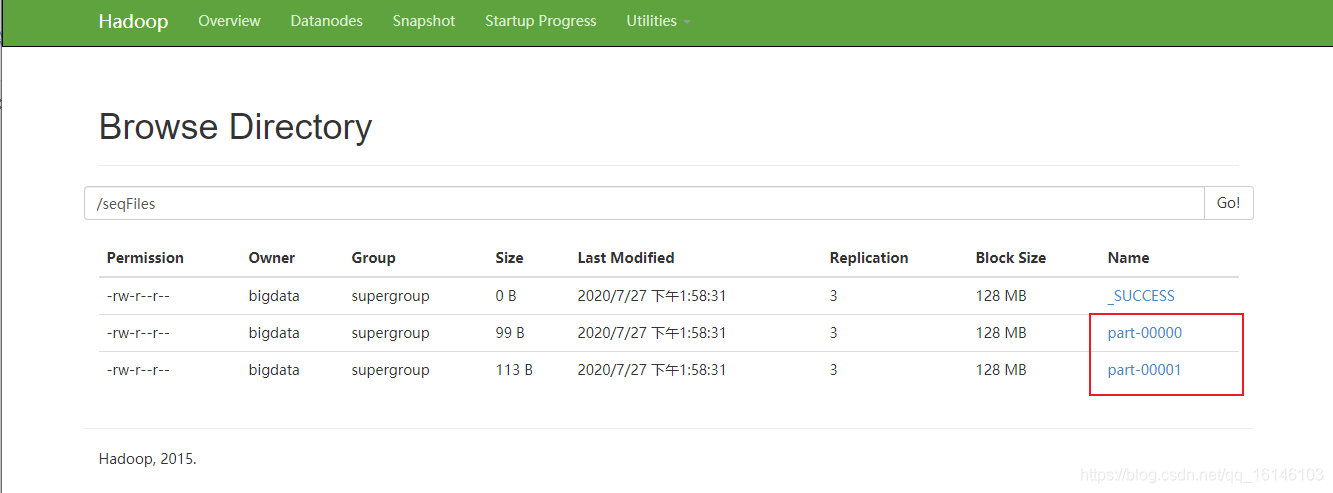
scala> rdd1.saveAsSequenceFile("hdfs://hadoop002:9000/seqFiles")
- 1
- 2
- 3
- 4
- 5
- 2.读取 SequenceFile 文件
// 注意: 需要指定泛型的类型 sc.sequenceFile[String, Int]
scala> val rdd1 = sc.sequenceFile[String, Int]("hdfs://hadoop002:9000/seqFiles")
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[16] at sequenceFile at <console>:26
scala> rdd1.collect
res5: Array[(String, Int)] = Array((a,1), (b,2), (c,3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
四. 读写 objectFile 文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。
可以通过objectFile[k,v] 函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出
- 1. 把 RDD 保存为objectFile
scala> val rdd1 = sc.parallelize(Array(("a", 1),("b", 2),("c", 3)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[17] at parallelize at <console>:26
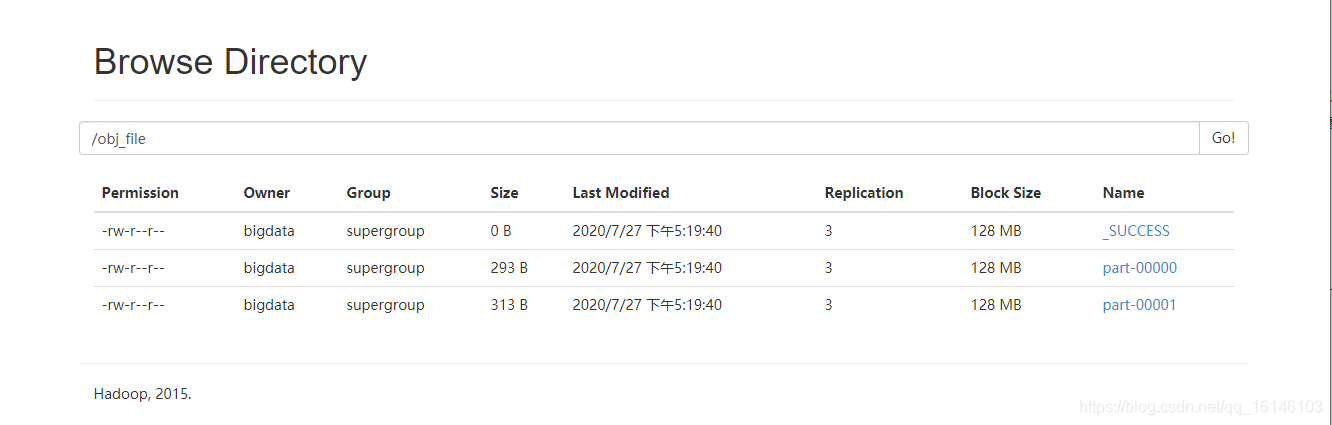
scala> rdd1.saveAsObjectFile("hdfs://hadoop002:9000/obj_file")
- 1
- 2
- 3
- 4
- 5
- 2.读取 objectFile
scala> val rdd1 = sc.objectFile[(String, Int)]("hdfs://hadoop002:9000/obj_file")
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[21] at objectFile at <console>:26
scala> rdd1.collect
res7: Array[(String, Int)] = Array((a,1), (b,2), (c,3))
- 1
- 2
- 3
- 4
- 5
- 6
五. 从 HDFS 读写文件
Spark 的整个生态系统与 Hadoop 完全兼容的,所以对于 Hadoop 所支持的文件类型或者数据库类型,Spark 也同样支持.
另外,由于 Hadoop 的 API 有新旧两个版本,所以 Spark 为了能够兼容 Hadoop 所有的版本,也提供了两套创建操作接口.
对于外部存储创建操作而言,HadoopRDD 和 newHadoopRDD 是最为抽象的两个函数接口,主要包含以下四个参数.
- 1)输入格式(InputFormat): 制定数据输入的类型,如 TextInputFormat 等,新旧两个版本所引用的版本分别是
org.apache.hadoop.mapred.InputFormat
和org.apache.hadoop.mapreduce.InputFormat(NewInputFormat) - 2)键类型: 指定[K,V]键值对中K的类型
- 3)值类型: 指定[K,V]键值对中V的类型
- 4)分区值: 指定由外部存储生成的RDD的partition数量的最小值,如果没有指定,系统会使用默认值defaultMinSplits
注意:其他创建操作的API接口都是为了方便最终的Spark程序开发者而设置的,是这两个接口的高效实现版本.例 如,对于textFile而言,只有path这个指定文件路径的参数,其他参数在系统内部指定了默认值。
- 在Hadoop中以压缩形式存储的数据,不需要指定解压方式就能够进行读取,因为Hadoop本身有一个解压器会根据压缩文件的后缀推断解压算法进行解压.
- 如果用Spark从Hadoop中读取某种类型的数据不知道怎么读取的时候,上网查找一个使用map-reduce的时候是怎么读取这种这种数据的,然后再将对应的读取方式改写成上面的hadoopRDD和newAPIHadoopRDD两个类就行了
六. 从 Mysql 数据读写文件
1.引入Mysql依赖
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6

2. 从 Mysql 读取数据
package Day05
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
**
@author 不温卜火
**
* @create 2020-07-27 17:43
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
object JDBCDemo {
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) //定义连接mysql的参数 val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop002:3306/rdd" val userName = "root" val passWd = "199712" val rdd = new JdbcRDD( sc, () => { Class.forName(driver) DriverManager.getConnection(url, userName, passWd) }, "select id, name from user where id >= ? and id <= ?", 1, 20, 2, result => (result.getInt(1), result.getString(2)) ) rdd.collect.foreach(println) }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1. 对象数据
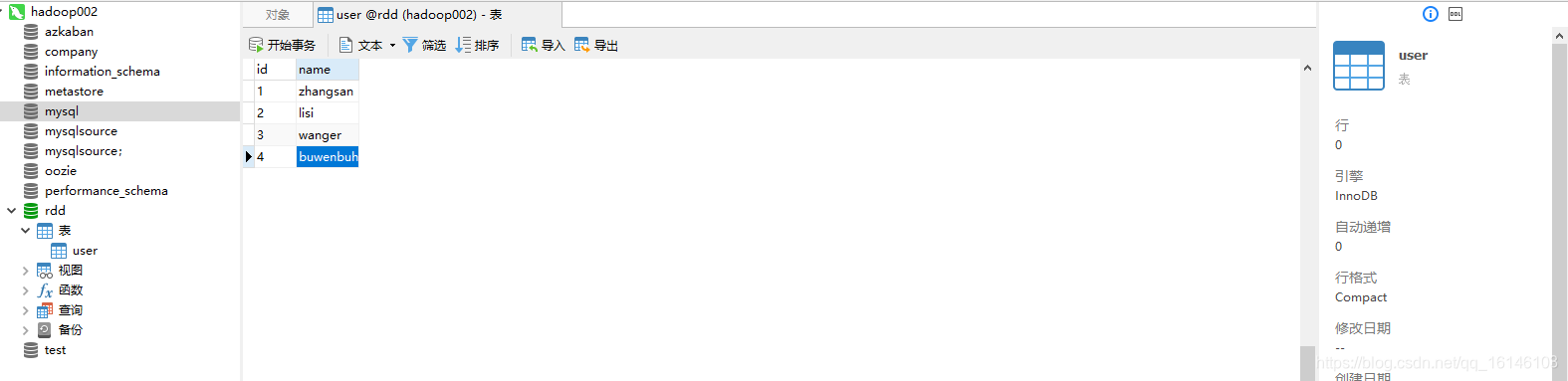
- 2. 获取数据
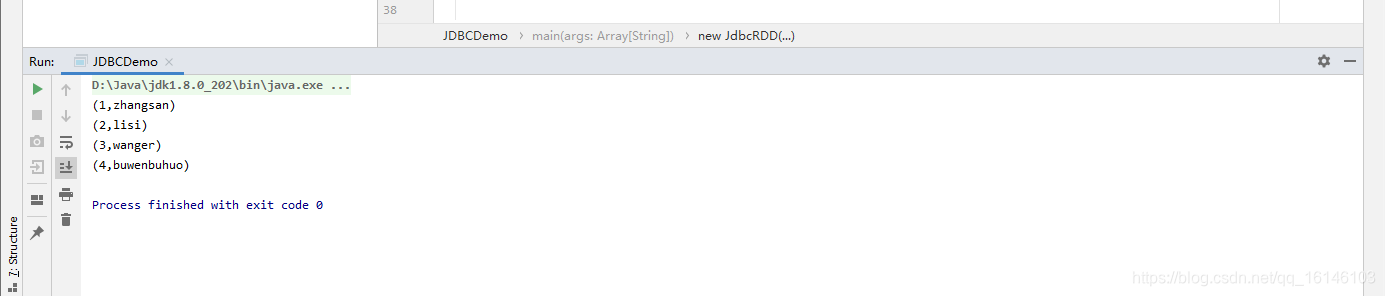
3. 向 Mysql 写入数据
package Day05
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
**
@author 不温卜火
**
* @create 2020-07-27 18:57
**
* MyCSDN :https://buwenbuhuo.blog.csdn.net/
*/
object JDBCDemo2 {
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) //定义连接mysql的参数 val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop002:3306/rdd" val userName = "root" val passWd = "199712" val rdd: RDD[(Int, String)] = sc.parallelize(Array((5, "police"), (6, "fire"))) // 对每个分区执行 参数函数 rdd.foreachPartition(it => { Class.forName(driver) val conn: Connection = DriverManager.getConnection(url, userName, passWd) it.foreach(x => { val statement: PreparedStatement = conn.prepareStatement("insert into user values(?, ?)") statement.setInt(1, x._1) statement.setString(2, x._2) statement.executeUpdate() }) }) }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
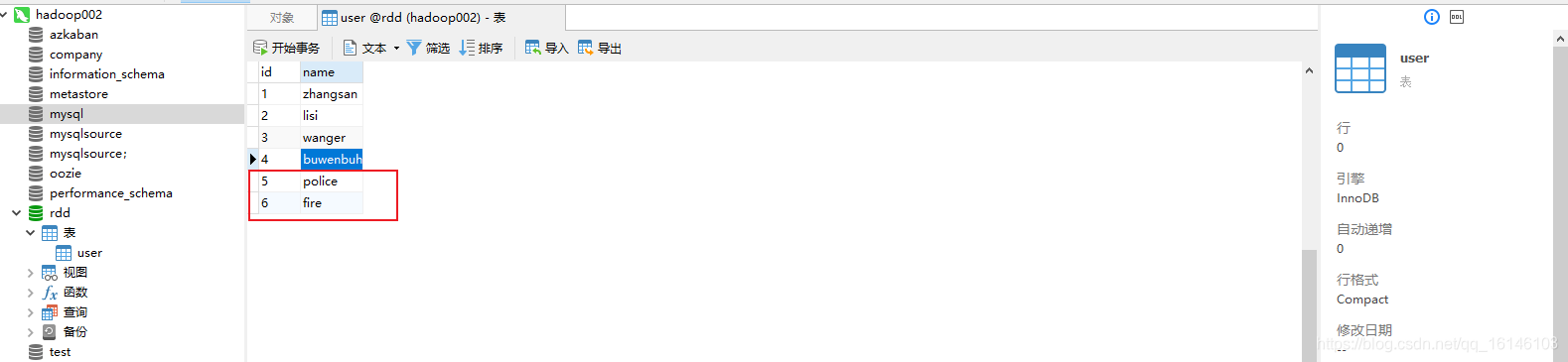
七. 从 Hbase 读写文件
由于 org.apache.hadoop.hbase.mapreduce.TableInputFormat 类的实现,Spark 可以通过Hadoop输入格式访问 HBase。
这个输入格式会返回键值对数据,其中键的类型为org. apache.hadoop.hbase.io.ImmutableBytesWritable,而值的类型为org.apache.hadoop.hbase.client.Result。
1.导入依赖
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> <exclusions> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions>
</dependency>
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.1</version> <exclusions> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2. 从 HBase 读取数据
package day04
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object HBaseDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val hbaseConf: Configuration = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", "hadoop002,hadoop003,hadoop004") hbaseConf.set(TableInputFormat.INPUT_TABLE, "student") val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD( hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result]) val rdd2: RDD[String] = rdd.map { case (_, result) => Bytes.toString(result.getRow) } rdd2.collect.foreach(println) sc.stop() }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3. 向 HBase 写入数据
package day04
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
object HBaseDemo2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val hbaseConf = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", "hadoop002,hadoop003,hadoop004") hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "student") // 通过job来设置输出的格式的类 val job = Job.getInstance(hbaseConf) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Put]) val initialRDD = sc.parallelize(List(("10", "apple", "11"), ("20", "banana", "12"), ("30", "pear", "13"))) val hbaseRDD = initialRDD.map(x => { val put = new Put(Bytes.toBytes(x._1)) put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(x._2)) put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("weight"), Bytes.toBytes(x._3)) (new ImmutableBytesWritable(), put) }) hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration) }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/107609219

- 点赞
- 收藏
- 关注作者
评论(0)