Spark Core快速入门系列(12) | 变量与累加器问题

大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是变量与累加器问题


一. 共享变量
- 1.代码
package Demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
**
@author 不温卜火
**
* @create 2020-08-01 12:18
**
* MyCSDN : https://buwenbuhuo.blog.csdn.net/
*
*/
object AccDemo1 {
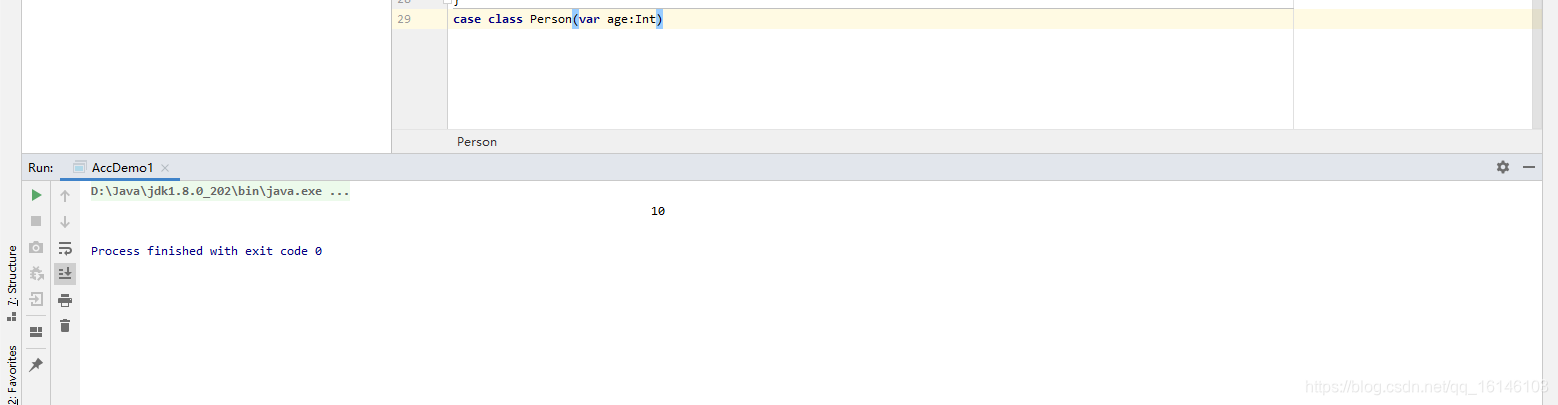
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val p1 = Person(10) // 将来会把对象序列化之后传递到每个节点上 val rdd1 = sc.parallelize(Array(p1)) val rdd2: RDD[Person] = rdd1.map(p => {p.age = 100; p}) rdd2.count() // 仍然是 10 println(p1.age)
}
}
case class Person(var age:Int)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 2.结果:
正常情况下, 传递给 Spark 算子(比如: map, reduce 等)的函数都是在远程的集群节点上执行, 函数中用到的所有变量都是独立的拷贝.
这些变量被拷贝到集群上的每个节点上, 都这些变量的更改不会传递回驱动程序.
支持跨 task 之间共享变量通常是低效的, 但是 Spark 对共享变量也提供了两种支持:
- 累加器
- 广播变量
二. 累加器
累加器用来对信息进行聚合,通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,所以更新这些副本的值不会影响驱动器中的对应变量。
如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
累加器是一种变量, 仅仅支持“add”, 支持并发. 累加器用于去实现计数器或者求和. Spark 内部已经支持数字类型的累加器, 开发者可以添加其他类型的支持.
2.1 内置累加器
需求:计算文件中空行的数量
- 1. 代码
package Demo
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
**
@author 不温卜火
**
* @create 2020-08-01 12:22
**
* MyCSDN : https://buwenbuhuo.blog.csdn.net/
*
*/
object AccDemo2 {
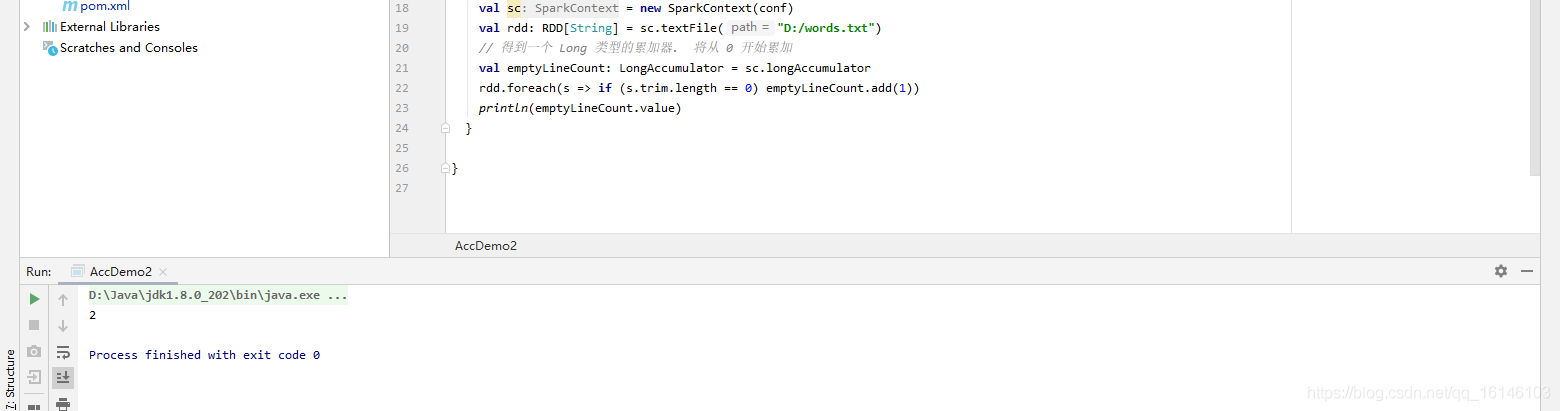
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val rdd: RDD[String] = sc.textFile("D:/words.txt") // 得到一个 Long 类型的累加器. 将从 0 开始累加 val emptyLineCount: LongAccumulator = sc.longAccumulator rdd.foreach(s => if (s.trim.length == 0) emptyLineCount.add(1)) println(emptyLineCount.value)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 2. 运行结果

- 3. 说明

- 在驱动程序中通过sc.longAccumulator得到Long类型的累加器, 还有Double类型的
- 可以通过value来访问累加器的值.(与sum等价). avg得到平均值
- 只能通过add来添加值.
- 累加器的更新操作最好放在action中, Spark 可以保证每个 task 只执行一次. 如果放在 transformations 操作中则不能保证只更新一次.有可能会被重复执行.
2.2 自定义累加器
通过继承类AccumulatorV2来自定义累加器.
下面这个累加器可以用于在程序运行过程中收集一些文本类信息,最终以List[String]的形式返回。
- 1. 累加器
package Demo
import java.util
import java.util.{ArrayList, Collections}
import org.apache.spark.util.AccumulatorV2
/**
**
@author 不温卜火
**
* @create 2020-08-01 12:56
**
* MyCSDN : https://buwenbuhuo.blog.csdn.net/
*
*/
object MyAccDemo {
def main(args: Array[String]): Unit = { }
}
class MyAcc extends AccumulatorV2[String, java.util.List[String]] {
private val _list: java.util.List[String] = Collections.synchronizedList(new ArrayList[String]())
override def isZero: Boolean = _list.isEmpty override def copy(): AccumulatorV2[String, util.List[String]] = { val newAcc = new MyAcc _list.synchronized { newAcc._list.addAll(_list) } newAcc
} override def reset(): Unit = _list.clear() override def add(v: String): Unit = _list.add(v) override def merge(other: AccumulatorV2[String, util.List[String]]): Unit =other match { case o: MyAcc => _list.addAll(o.value) case _ => throw new UnsupportedOperationException( s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}")
} override def value: util.List[String] = java.util.Collections.unmodifiableList(new util.ArrayList[String](_list))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 2. 测试
package Demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
**
*
*@author 不温卜火
**
* @create 2020-08-01 12:57
**
* MyCSDN : https://buwenbuhuo.blog.csdn.net/
*
*/
object MyAccDemo1 {
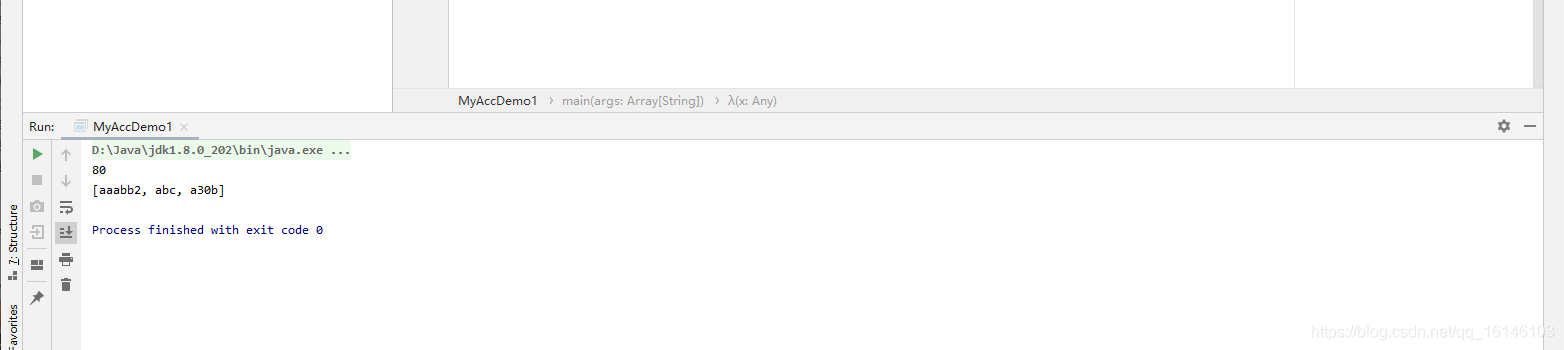
def main(args: Array[String]): Unit = { val pattern = """^\d+$""" val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) // 统计出来非纯数字, 并计算纯数字元素的和 val rdd1 = sc.parallelize(Array("abc", "a30b", "aaabb2", "60", "20")) val acc = new MyAcc sc.register(acc) val rdd2: RDD[Int] = rdd1.filter(x => { val flag: Boolean = x.matches(pattern) if (!flag) acc.add(x) flag }).map(_.toInt) println(rdd2.reduce(_ + _)) println(acc.value)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
注意:
在使用自定义累加器的不要忘记注册sc.register(acc)
- 3. 运行结果
三. 广播变量
广播变量在每个节点上保存一个只读的变量的缓存, 而不用给每个 task 来传送一个 copy.
例如, 给每个节点一个比较大的输入数据集是一个比较高效的方法. Spark 也会用该对象的广播逻辑去分发广播变量来降低通讯的成本.
广播变量通过调用SparkContext.broadcast(v)来创建. 广播变量是对v的包装, 通过调用广播变量的 value方法可以访问.
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 说明
-
通过对一个类型T的对象调用SparkContext.broadcast创建出一个Broadcast[T]对象。任何可序列化的类型都可以这么实现。
-
通过value属性访问该对象的值(在Java中为value()方法)。
-
变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/107619331

- 点赞
- 收藏
- 关注作者
评论(0)