想要快速爬取整站图片?速进(附完整代码)

大家好,我是不温卜火,是一名计算机学院大数据专业大三的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/

本片博文为大家带来的想要快速爬取整站图片?速进(附完整代码)。
完整代码在Github,如有需要可自行下载。
GIthub地址:https://github.com/459804692/scrapy/tree/master/scrapy_demo

快速爬取整个网站的图片当然是可行的!!!但是 我们还是先从一个切入点切入,此处的切入点,博主选择的是宝马五系车型为切入点,同理,爬取妹子图也是如此。
一. 爬取前的准备
汽车直接官网:https://www.autohome.com.cn/
宝马五系网页地址:https://www.autohome.com.cn/65/
图片地址:https://car.autohome.com.cn/pic/series/65.html
二. 查看网页

根据上图,可以发现我们所要爬取的部分都在<div class="uibox">xxx</div>这个父标签内。
好了,既然已经知道我们的切入点在哪了,那么我们下面就要对此部分进行解析了
上一张图片可能不是太直观,那么我们可以通过查看源码,来进行解析:

根据上图我们可以知道第一个标记处为我们所要爬取部分的title。
而我们所要爬取的图片则为标记的第二部分<img src>xxxx</img>
三. 分析与实现
1. 先确定我们所要爬取内容的具体位置

好了,根据上图我们可以看到我们准备爬取的内容都在<div class="uibox"></div>中。这时,我们应该想到的是先把这部分全部获取下来,然后通过循环遍历,把我们所需要的部分分别提取出来。
首先我们先来实现获取所有“uibox”中的内容,通过xpath进行解析,解析式如下:
uiboxs = response.xpath("//div[@class='uibox']")[1:] # 使用切片操作
- 1
下图为所获取到的所有结果(通过scrapy shell 解析所得到的结果)

至于为什么会用到接片操作,我们可以看下图
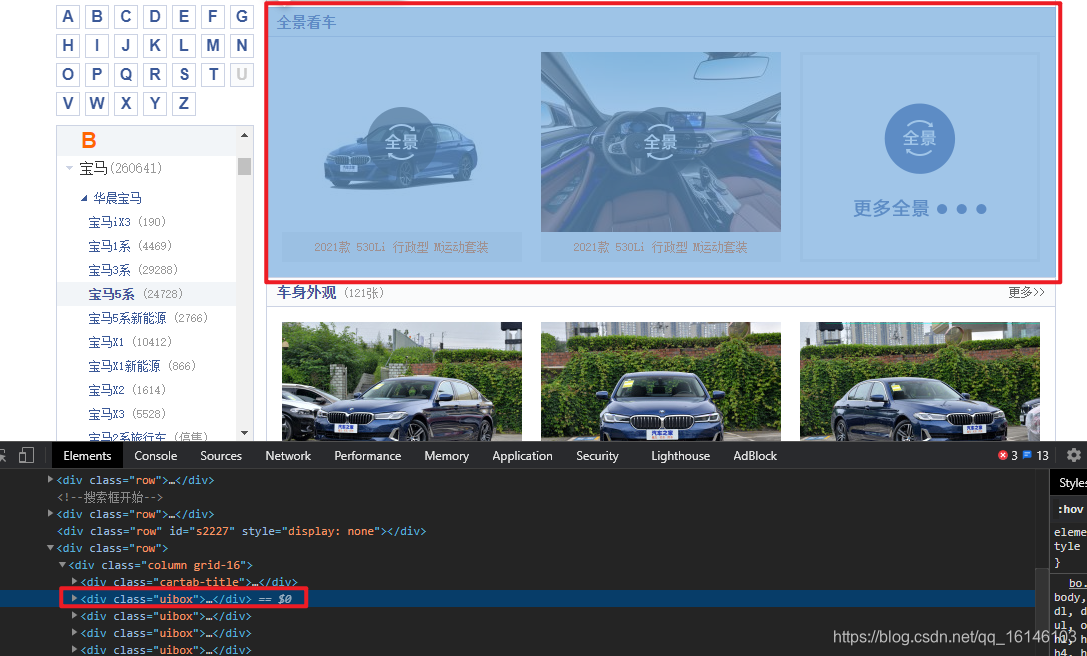 由上图我们可以看到爬取图片的时候全景看车这部分是不需要爬取的。由于其不是我们所需要的,那么我们就需要把它排除掉,而排除操作我选择的是切片操作。
由上图我们可以看到爬取图片的时候全景看车这部分是不需要爬取的。由于其不是我们所需要的,那么我们就需要把它排除掉,而排除操作我选择的是切片操作。
切片操作完成后,我们通过循环遍历可以分别得到我们所需要的图片名称及图片链接。
怎样得到的?我们先看下HTML源码结构:


根据上面两张图片,我们可以分别进行xpath解析。解析式如下:
for uibox in uiboxs: category = uibox.xpath(".//div[@class = 'uibox-title']/a/text()").get() print(category) urls = uibox.xpath(".//ul/li/a/img/@src").getall() print(urls)
- 1
- 2
- 3
- 4
- 5
解析完成后,我们通过输出打印看下效果:

根据上图我们可以看到图片的网址是不完全的,这时候我们可以通过添加https:使其形式成为url = "https:"+url这种形式。最终可以的到下图的效果:
for url in urls: url = "https:"+url print(url)
- 1
- 2
- 3

上述代码用的是最原始的遍历方法让每一个图片地址输出成我们想要的,那么还有其他方法没有?
答案是肯定! 下面博主给的代码即为优化方法:
优化1:自动拼接成完整的URL
for url in urls: url = response.urljoin(url) print(url)
- 1
- 2
- 3
优化2: 使用map()
在使用map()优化前,我们需要先设定好item.py
class BmwItem(scrapy.Item): category = scrapy.Field() urls= scrapy.Field()
- 1
- 2
- 3
urls = list(map(lambda url:response.urljoin(url),urls)) item = BmwItem(category = category , urls = urls) yield item
- 1
- 2
- 3
上述两种优化方法得到的结果和第一个是一样的。效果图如下:

2. 存储的具体实现 (在pipelines中处理)
在使用pipelines的时候,我们需要先从设置里打开选项,把默认的注释去掉

去掉注释以后,我们就把图片保存到本地这一想法从理论成为现实:
怎样实现?
在此博主总共分成两步进行实现,首先是先判断是否有目录,如果有的话就直接进行下一步,如果没有的话,则会进行自动创建,源码部分如下:
def __init__(self): # 获取并创建当前目录,没有自行创建 self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images') if not os.path.exists(self.path): os.mkdir(self.path) else: print('images文件夹存在')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
文件夹创建完成后,就需要对图片进行保存了。源码如下:
def process_item(self, item, spider): category = item['category'] urls = item['urls'] category_path = os.path.join(self.path,category) if not os.path.exists(category_path): os.mkdir(category_path) for url in urls: image_name = url.split('_')[-1] request.urlretrieve(url,os.path.join(category_path,image_name)) return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对上述源码,博主只对image_name = url.split('_')[-1]这一句做详细解释。至于为什么要这样操作,看下图:

根据上图,我们不难看出所有图片地址的_之前基本上都是一样的,那么我们就以_为分割线 ,通过切片的方式选取最后一部分当作我们所要保存的图片的名称!
下面查看一下运行的结果:

通过图片我们可以看到我们已经成功的把理想编程了现实。
3. 更新完善源码
虽然通过以上的步骤我们已经完成了图片的爬取,但是我们要知道我们用的是不同的循环遍历的方法一张一张的下载。初次之外,上述的方法也没有用到异步下载,效率较为低下。
在这个时候我们就可以使用scrapy框架自带的item pipelines了。
为什么要选择使用scrapy内置的下载文件的方法:
- 避免重新下载最近已经下载过的数据。
- 可以方便的指定文件存储的路径。
- 可以将下载的图片转换成通用的格式。比如png或jpg。
- 可以方便的生成缩略图。
- 可以方便的检测图片的宽和高,确保他们满足最小限制。
- 异步下载,效率非常高
下载文件的Files Pipeline与下载图片的Images Pipeline:
当使用Files Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个Item,然后在这个item中定义两个属性,分别为file_urls以及files = file_urls是用来存储需要下载的文件的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到item的fileds属性中。比如下载路径、下载的url和文件的校验码等。
- 在配置文件settings.py中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。
- 启动pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.files.FilesPipelines:1。
当使用Images Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个Item,然后在这个item中定义两个属性,分别为image_urls以及images = image_urls是用来存储需要下载的图片的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中。比如下载路径、下载的url和文件的校验码等。
- 在配置文件settings.py中配置IMAGES_STORE,这个配置是用来设置文件下载下来的路径。
- 启动pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.images.ImagesPipelines:1。
- 1. 修改完善items.py
class BmwItem(scrapy.Item): category = scrapy.Field() image_urls= scrapy.Field() images = scrapy.Field()
- 1
- 2
- 3
- 4
- 2. 修改主程序
# 修改此部分
item = BmwItem(category = category , image_urls = urls)
- 1
- 2
- 3. 调用scrapy自带的image Pipelines及images_store
ITEM_PIPELINES = { # 'bmw1.pipelines.Bmw1Pipeline': 300, # 系统自带的Pipeline 可以实现异步 'scrapy.pipelines.images.ImagesPipeline': 1
}
# 图片下载的路径,供image pipelines使用
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
好了,修改完成,下面我们来看下效果
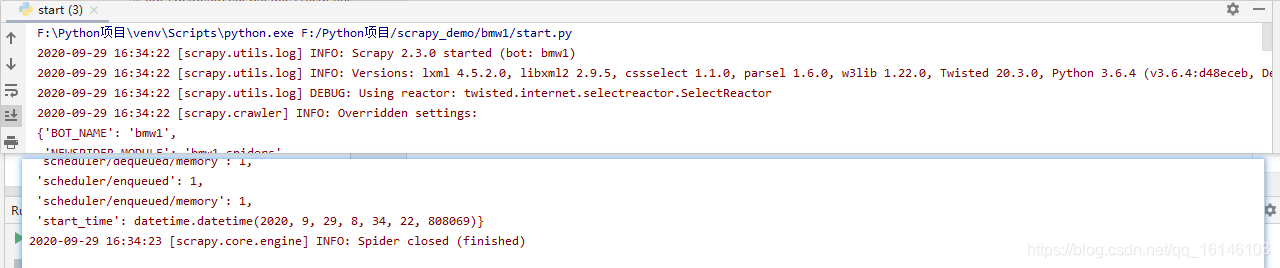
我们可以看到现在下载速度很快,只用了两秒就完成了整个宝马五系车型图片的下载,但是这样还是有弊端的,因为这样我们下载所有图片都在一个默认的full文件夹下,而没有任何分类。

这时候可能会有读者问:这能按分类进行排序么!答案是能的。看博主下面操作:
为了实现上述读者所说的需求,其实很简单,只需要我们再次在pipelines.py中重写一个类即可
- 4. 重写类
# 重写一个新类,使其能够分类下载
class BMWImagesPipeline(ImagesPipeline): def get_media_requests(self, item, info): # 这个方法是在发送下载请求之前调用 # 其实这个方法本身就是去发送下载请求的 request_objs = super(BMWImagesPipeline, self).get_media_requests(item,info) for request_obj in request_objs: request_obj.item = item return request_objs def file_path(self, request, response=None, info=None): # 这个方法是在图片将要被存储的时候调用,来获取这个图片存储的路径 path = super(BMWImagesPipeline, self).file_path(request,response,info) category = request.item.get('category') images_store = settings.IMAGES_STORE category_path = os.path.join(images_store,category) if not os.path.exists(category_path): os.mkdir(category_path) images_name = path.replace("full/","") images_path = os.path.join(category_path,images_name) return images_path
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 6.修改item_pipelines
ITEM_PIPELINES = { # 'bmw1.pipelines.Bmw1Pipeline': 300, # 系统自带的Pipeline 可以实现异步 # 'scrapy.pipelines.images.ImagesPipeline': 1 # 使用自己创建的类对象 'bmw1.pipelines.BMWImagesPipeline': 1
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 7. 运行查看结果

- 8. 大图img保存

你以为到这里就大功告成了嘛!如果真的这样认为那你就大错特错了,因为现在保存的还只是小图,我们需要保存的是大图。下面我们先来看看大图与小图的区别:
大图网址:https://car3.autoimg.cn/cardfs/product/g26/M08/5A/55/autohomecar__ChcCP12J_XGAXP0pAAtylyqMfeQ144.jpg
小图网址:https://car3.autoimg.cn/cardfs/product/g26/M08/5A/55/240x180_0_q95_c42_autohomecar__ChcCP12J_XGAXP0pAAtylyqMfeQ144.jpg
- 1
- 2

根据上图,我们可以发现,大图只是比小图少了240x180_0_q95_c42_这一部分,既然得到了这样一则比较有用的信息,那么我们就可以通过替换发把原来的小图网址转换成大图网址,说干就干,上才艺:
srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs))
- 1
此部分到这里大体就完成了,剩下一点博主就直接把此部分的代码放上:
rules = ( Rule(LinkExtractor(allow=r"https://car.autohome.com.cn/pic/series/65.+"),callback="parse_page",follow=True), ) def parse_page(self, response): category = response.xpath("//div[@class='uibox']/div/text()").get() srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li//img/@src').getall() srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs)) # 得到整个状态列表 # urls = [] # for src in srcs: # url = response.urljoin(src) # urls.append(url) # srcs = list(map(lambda x:response.urljoin(x),srcs)) yield BmwItem(category=category,image_urls = srcs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
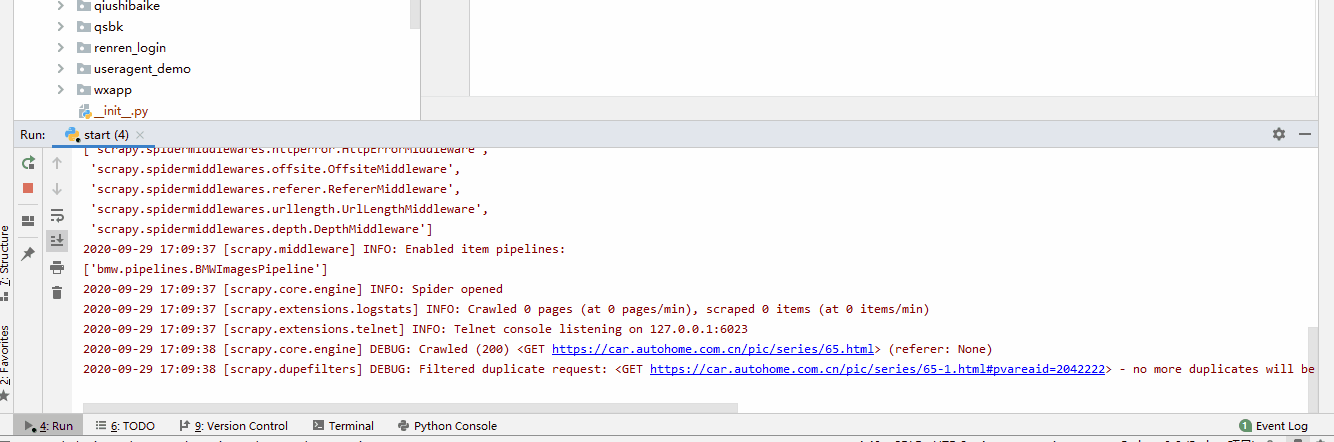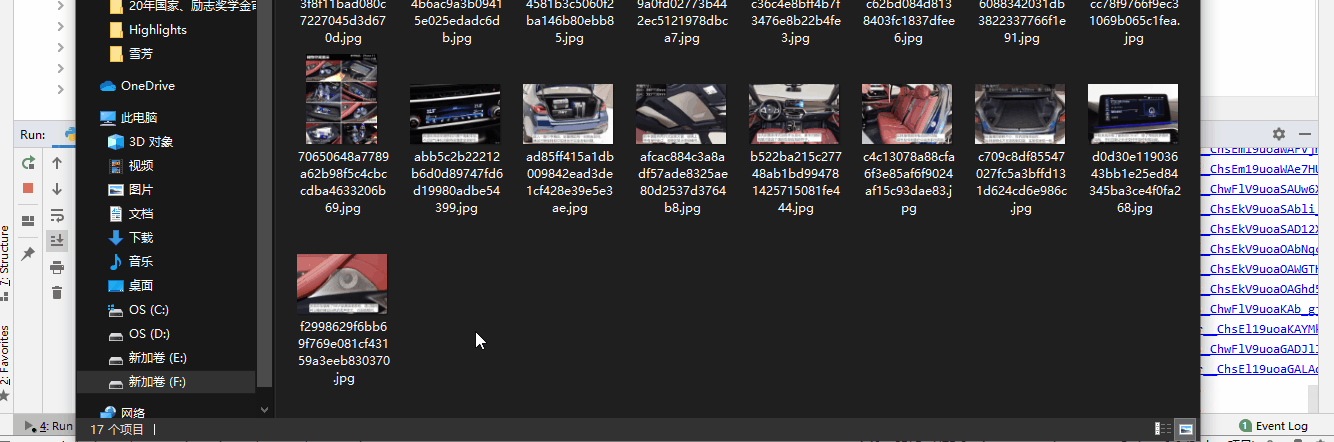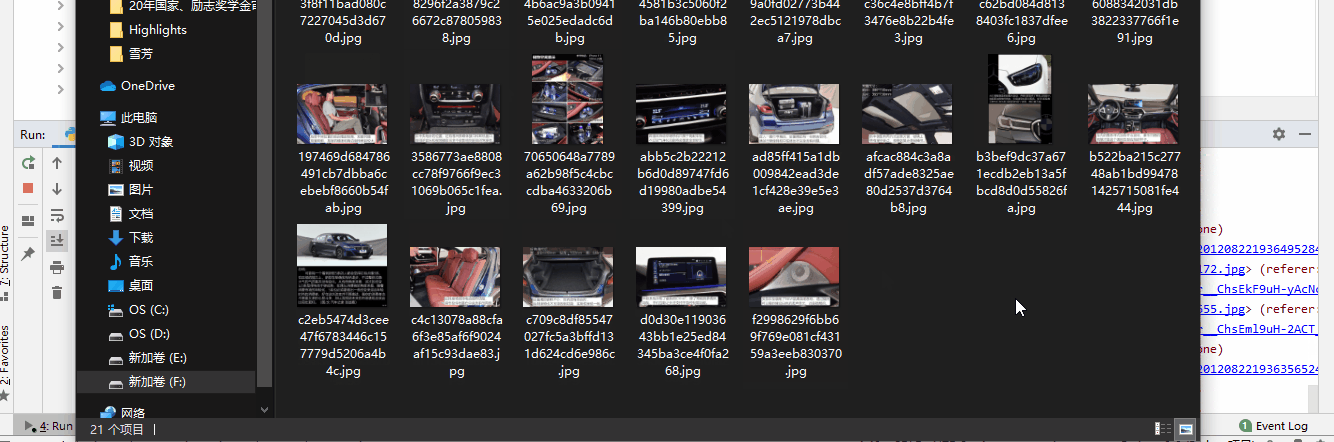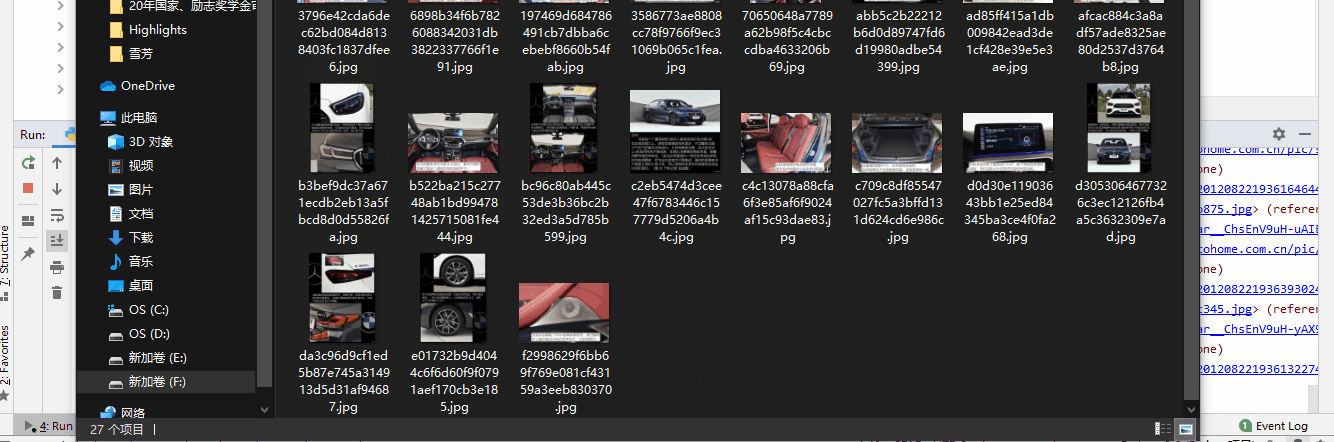
- 9. 最终运行结果
四. 代码
- 1. bmw5
class Bmw5Spider(CrawlSpider): name = 'bmw5' allowed_domains = ['car.autohome.com.cn'] start_urls = ['https://car.autohome.com.cn/pic/series/65.html'] rules = ( Rule(LinkExtractor(allow=r"https://car.autohome.com.cn/pic/series/65.+"),callback="parse_page",follow=True), ) def parse_page(self, response): category = response.xpath("//div[@class='uibox']/div/text()").get() srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li//img/@src').getall() srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs)) # 得到整个状态列表 # urls = [] # for src in srcs: # url = response.urljoin(src) # urls.append(url) # srcs = list(map(lambda x:response.urljoin(x),srcs)) yield BmwItem(category=category,image_urls = srcs) # 爬取缩略图用此部分 def parse(self, response): # SelectorList -> list (可进行遍历) uiboxs = response.xpath("//div[@class='uibox']")[1:] # 使用切片操作 for uibox in uiboxs: category = uibox.xpath(".//div[@class = 'uibox-title']/a/text()").get() urls = uibox.xpath(".//ul/li/a/img/@src").getall() # for url in urls: # url = "https:"+url # print(url) # 优化1:自动拼接成完整的URL # for url in urls: # url = response.urljoin(url) # print(url) # 优化2: 使用map() urls = list(map(lambda url:response.urljoin(url),urls)) item = BmwItem(category = category , image_urls = urls) yield item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 2. items
class BmwItem(scrapy.Item): category = scrapy.Field() image_urls= scrapy.Field() images = scrapy.Field()
- 1
- 2
- 3
- 4
- 3. pipelines
class BmwPipeline: def __init__(self): # 获取并创建当前目录,没有自行创建 self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images') if not os.path.exists(self.path): os.mkdir(self.path) def process_item(self, item, spider): category = item['category'] urls = item['urls'] category_path = os.path.join(self.path,category) if not os.path.exists(category_path): os.mkdir(category_path) for url in urls: image_name = url.split('_')[-1] request.urlretrieve(url,os.path.join(category_path,image_name)) return item
# 重写一个新类,使其能够分类下载
class BMWImagesPipeline(ImagesPipeline): def get_media_requests(self, item, info): # 这个方法是在发送下载请求之前调用 # 其实这个方法本身就是去发送下载请求的 request_objs = super(BMWImagesPipeline, self).get_media_requests(item,info) for request_obj in request_objs: request_obj.item = item return request_objs def file_path(self, request, response=None, info=None): # 这个方法是在图片将要被存储的时候调用,来获取这个图片存储的路径 path = super(BMWImagesPipeline, self).file_path(request,response,info) category = request.item.get('category') images_store = settings.IMAGES_STORE category_path = os.path.join(images_store,category) if not os.path.exists(category_path): os.mkdir(category_path) images_name = path.replace("full/","") images_path = os.path.join(category_path,images_name) return images_path
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 4. settings
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
ITEM_PIPELINES = { # 虽然能够下载,但是不能实现异步 # 'bmw.pipelines.BmwPipeline': 300, # 系统自带的Pipeline 可以实现异步 # 'scrapy.pipelines.images.ImagesPipeline': 1 # 使用自己创建的类对象 'bmw.pipelines.BMWImagesPipeline' : 1
}
# 图片下载的路径,供image pipelines使用
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!


文章来源: buwenbuhuo.blog.csdn.net,作者:不温卜火,版权归原作者所有,如需转载,请联系作者。
原文链接:buwenbuhuo.blog.csdn.net/article/details/108854748

- 点赞
- 收藏
- 关注作者
评论(0)